你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
HDInsight on AKS 上的 Apache Flink® 群集中的表 API 和 SQL
注意
我们将于 2025 年 1 月 31 日停用 Azure HDInsight on AKS。 在 2025 年 1 月 31 日之前,你需要将工作负荷迁移到 Microsoft Fabric 或同等的 Azure 产品,以避免工作负荷突然终止。 订阅上的剩余群集会被停止并从主机中移除。
在停用日期之前,仅提供基本支持。
重要
此功能目前以预览版提供。 Microsoft Azure 预览版的补充使用条款包含适用于 beta 版、预览版或其他尚未正式发布的 Azure 功能的更多法律条款。 有关此特定预览版的信息,请参阅 Azure HDInsight on AKS 预览版信息。 如有疑问或功能建议,请在 AskHDInsight 上提交请求并附上详细信息,并关注我们以获取 Azure HDInsight Community 的更多更新。
Apache Flink 提供两个关系 API(表 API 和 SQL),用于统一流和批处理。 表 API 是一种语言集成的查询 API,它允许关系运算符(如选择、筛选器和联接)中的查询组合直观。 Flink 的 SQL 支持基于实现 SQL 标准的 Apache Calcite。
表 API 和 SQL 接口与 Flink 的 DataStream API 之间无缝集成。 可以轻松地在所有 API 和基于它们构建的库之间进行切换。
Apache Flink SQL
与其他 SQL 引擎一样,Flink 查询在表之上运行。 它不同于传统数据库,因为 Flink 在本地不管理静态数据;相反,其查询在外部表上持续运行。
Flink 数据处理管道以源表开头,以接收器表结尾。 源表生成在查询执行期间运行的行:它们是查询 FROM 子句中引用的表。 连接器可以是 HDInsight Kafka、HDInsight HBase、Azure 事件中心、数据库、文件系统或任何其他位于类路径中的系统。
在 HDInsight on AKS 群集中使用 Flink SQL 客户端
请参阅本文,了解如何在 Azure 门户上使用 Secure Shell 的 CLI。 下面是有关如何入门的一些快速示例。
启动 SQL 客户端
./bin/sql-client.sh传递要与 sql-client 一起运行的初始化 sql 文件
./sql-client.sh -i /path/to/init_file.sql在 sql-client 中设置配置
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL 支持以下 CREATE 语句
- CREATE TABLE
- CREATE DATABASE
- CREATE CATALOG
下面是一个示例语法,用于使用 jdbc 连接器来连接到 MSSQL,其 ID、名称为 CREATE TABLE 语句中的列
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
创建数据库:
CREATE DATABASE students;
创建目录:
CREATE CATALOG myhive WITH ('type'='hive');
可以在这些表的顶部运行连续查询
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
从源表写出到接收器表:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
添加依赖项
JAR 语句用于将用户 jar 添加到 classpath 中,或者从类路径中删除用户 jar,或在运行时的 classpath 中显示添加的 jar。
Flink SQL 支持以下 JAR 语句:
- ADD JAR
- 显示 JAR
- 删除 JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
HDInsight on AKS 上的 Apache Flink® 群集中的 Hive 元存储
目录提供元数据,例如数据库、表、分区、视图和函数以及访问存储在数据库或其他外部系统中的数据所需的信息。
在 AKS 上的 HDInsight 中,Flink 支持两个目录选项:
GenericInMemoryCatalog
GenericInMemoryCatalog 是目录的内存中实现。 所有对象仅可用于 sql 会话的生存期。
HiveCatalog
HiveCatalog 有两个用途:作为纯 Flink 元数据的持久存储,以及作为读取和写入现有 Hive 元数据的接口。
注意
HDInsight on AKS 群集附带 Apache Flink Hive 元存储的集成选项。 在创建群集期间,可以选择使用 Hive 元存储
如何创建和注册目录的 Flink 数据库
请参阅本文,了解如何使用 CLI 并从 Azure 门户上的 Secure Shell 开始使用 Flink SQL 客户端。
启动
sql-client.sh会话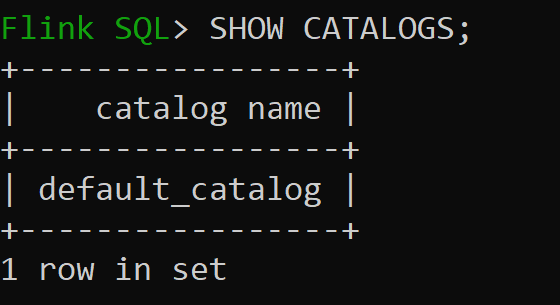
Default_catalog是默认内存中目录
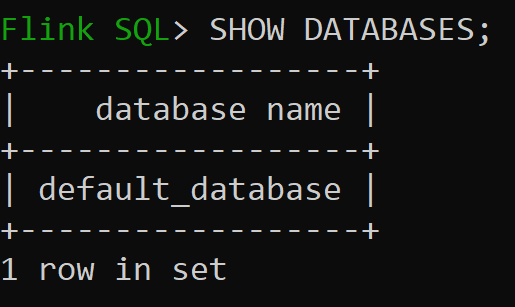
现在我们来检查内存中目录的默认数据库
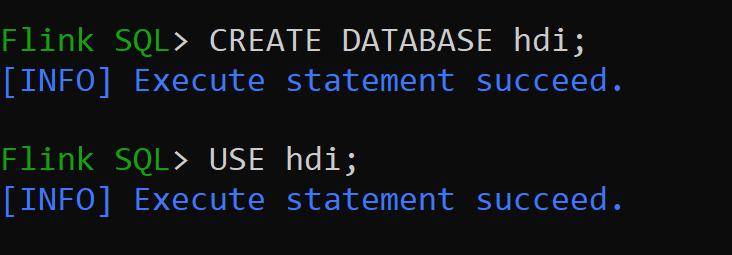
我们来创建版本 3.1.2 的 Hive 目录并使用它
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;注意
HDInsight on AKS 支持 Hive 3.1.2 和 Hadoop 3.3.2。
hive-conf-dir设置为位置/opt/hive-conf让我们在 hive 目录中创建数据库,并将其设置为会话的默认值(除非已更改)。
如何创建 Hive 表并将其注册到 Hive 目录
按照如何将 Flink 数据库创建和注册到目录的说明进行操作
我们来创建没有分区的连接器类型的 Flink 表 Hive
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');将数据插入 hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';从 hive_table 读取数据
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rows注意
Hive Warehouse Directory 位于在创建 Apache Flink 群集期间选择的存储帐户的指定容器中,可在目录/hive/仓库中找到
我们来创建有分区的连接器类型的 Flink 表 Hive
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
重要
Apache Flink 存在一个已知的限制。 为分区选择最后的 ‘n’ 列,而不考虑用户定义的分区列。 FLINK-32596 使用 Flink 方言创建 Hive 表时分区键会出错。
参考
- Apache Flink 表 API 和 SQL
- Apache、Apache Flink、Flink 和关联的开源项目名称是 Apache Software Foundation (ASF) 的商标。