设计索引
SQL Server 具有多个索引类型,以支持不同类型的工作负载。 在较高的层次上,可以将索引视为与表或视图相关联的磁盘结构,与扫描整个表相比,它使 SQL Server 能够更轻松地查找与索引键(由表或视图中的一列或多列组成)关联的一行或多行。
聚集索引
常见的 DBA 工作面试问题是询问应聘者聚集索引和非聚集索引之间的差异,因为索引是 SQL Server 中的基础数据存储技术。 聚集索引是基础表,根据键值按排序顺序存储。 给定表上只能有一个聚集索引,因为行只能按一个顺序存储。 没有聚集索引的表称为堆,而堆通常仅用作临时表。 一个重要的性能设计原则是使聚集索引键尽可能地窄。 在考虑聚集索引的关键列时,应考虑包含唯一值或包含多个非重复值的列。 良好的聚集索引键的另一个属性是用于按顺序访问的记录,这些记录经常用于对从表中检索到的数据进行排序。 在用于排序的列上使用聚集索引可以避免在每次执行查询时进行排序所需的开销,因为数据已按所需顺序存储。
注意
当我们说表以特定顺序“存储”时,指的是逻辑顺序,而不一定是物理的磁盘顺序。 索引在页之间具有指针,指针有助于创建逻辑顺序。 当“按顺序”扫描索引时,SQL Server 会逐页跟踪指针。 创建索引后,它很可能也立即以物理顺序存储在磁盘上,但是在你开始对数据进行修改并且需要将新页添加到索引时,指针仍会为我们指定正确的逻辑顺序,但是新页将很可能不以物理磁盘顺序排序。
“非聚集索引”
非聚集索引是与数据行分开的结构。 非聚集索引包含为索引定义的键值,以及指向包含该键值的数据行的指针。 可以使用 SQL Server 中的“包含的列”功能将其他非键列添加到非聚集索引的叶级别,以覆盖更多的列。 可以对表创建多个非聚集索引。
下面显示了何时需要向现有非聚集索引添加索引或添加列的示例:

查询计划表明,对于使用索引查找检索的每一行,都需要从聚集索引(表本身)中检索更多数据。 存在一个非聚集索引,但其仅包括产品列。 如果将查询中的其他列添加到非聚集索引(如下所示),则可以看到执行计划发生了更改,从而消除了键查找。

上面创建的索引是覆盖索引的一个示例,其中除了键列之外,还包括其他列以覆盖查询并消除访问表本身的需要。
非聚集索引和聚集索引都可以定义为唯一索引,这意味着键值不能重复。 在表上创建 PRIMARY KEY 或 UNIQUE 约束时,会自动创建唯一索引。
本节重点介绍 SQL Server 中的 B 树索引,这些索引也称为行存储索引。 B 树的一般结构如下所示:
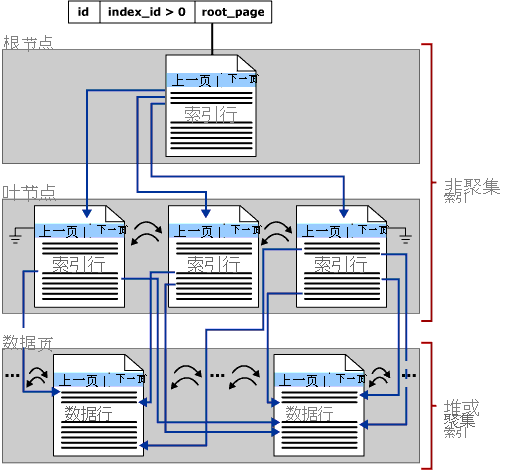
索引 B 树中的每个页称为一个索引节点,而 B 树的顶部节点称为根节点。 索引中的底部节点称为叶节点,叶节点的集合为叶级别。
索引设计是艺术与科学的结合。 其键中列数较少的窄索引需要较少的更新时间,且维护开销也较低;但是,对于像包含更多列的较宽索引这样的查询而言,它可能没有作用。 可能需要根据应用程序查询所选的列尝试几种索引方法。 查询优化器通常会为查询选择它认为最好的现有索引,然而,这并不意味着没有更好的索引可以建立。
正确地为数据库编制索引是一项复杂的任务。 在为表计划索引时,应牢记以下几项基本原则:
- 了解系统的工作负载。 与用于 90% 都是读取活动的数据仓库操作的表相比,主要用于插入操作的表从附加索引中获得的好处要少得多。
- 了解最常运行的查询,并围绕这些查询优化索引。
- 了解查询中使用的列的数据类型。 索引是整数数据类型、唯一列或非空列的理想选择。
- 在谓词和联接子句中经常使用的列上创建非聚集索引,并使这些索引尽可能地窄以避免产生开销。
- 了解你的数据大小/容量 – 对小型表进行表扫描将是一种相对便宜的操作,SQL Server 可能会决定进行表扫描,因为这样做很容易(简单)。 对大型表进行表扫描会很昂贵。
SQL Server 提供的另一种选择是创建筛选索引。 筛选索引最适合大型表中的列,该表中很大一部分行在该列中具有相同的值。 一个实际的示例是如下所示的雇员表,该表存储了所有雇员的记录,包括已离职或退休的雇员。
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
在此表中,有一个名为 CurrentFlag 的列,该列指示当前是否雇用了某雇员。 本示例使用位数据类型,仅指示两个值,1 表示当前正在雇佣,0 表示当前未雇佣。 对 CurrentFlag 列使用 WHERE CurrentFlag = 1 的筛选索引将可以对当前员工进行高效查询。
还可以为视图创建索引,当视图包含诸如聚合和/或表联接之类的查询元素时,此操作可以显著提高性能。
列存储索引
列存储为运行大型聚合工作负载的查询提供了改进的性能。 此类索引最初是针对数据仓库的,但随着时间的推移,列存储索引已用于了许多其他工作负载中,以帮助解决大型表上的查询性能问题。 从 SQL Server 2014 开始,既有非聚集列存储索引,也有聚集列存储索引。 像 B 树索引一样,聚集列存储索引是以特殊方式存储的表本身,而非聚集列存储索引则独立于表存储。 聚集列存储索引本质上包含给定表中的所有列。 但是,与行存储聚集索引不同,聚集列存储索引不进行排序。
非聚集列存储索引通常在两种情况下使用,第一种情况是表中的列具有列存储索引不支持的数据类型时。 列存储索引中支持大部分数据类型,但不支持 XML、CLR、sql_variant、ntext、text 和 image。 由于聚集列存储始终包含表的所有列(因为它就是表),因此非聚集列存储是唯一的选择。 第二种情况是筛选索引,这种情况在称为混合事务分析处理 (HTAP) 的体系结构中使用,在该体系中会将数据加载到基础表中,同时在该表上运行报表。 通过筛选索引(通常在日期字段中),此设计可实现良好的插入和报表性能。
列存储索引的存储机制是唯一的,因为索引中的每一列都是单独存储的。 它提供了两个好处。 其一是使用列存储索引的查询仅需要扫描满足查询所需的列,从而减少所执行的总 IO 量,其二是由于同一列中的数据在性质上可能类似,因此可以进行更大程度的压缩。
列存储索引在扫描大量数据的分析查询(例如数据仓库中的事实数据表)上表现最佳。 从 SQL Server 2016 开始,可以使用其他 B 树非聚集索引来扩充列存储索引,这在某些查询针对单一值进行查找时非常有用。
列存储索引还受益于批处理执行模式,批处理执行模式是指一次处理一组行(通常约为 900 行),而数据库引擎则一次仅处理一行。 查询引擎不是独立地加载每个记录并对其进行处理,而是在该 900 条记录的组中进行计算。 这种处理模型极大地减少了 CPU 指令的数量。
SELECT SUM(Sales) FROM SalesAmount;
与传统的行处理相比,批处理模式可显著提高性能。 SQL Server 2019 还包括用于行存储数据的批处理模式。 尽管行存储的批处理模式没有与列存储索引相同的读取性能,但是分析查询可能将性能提高多达 5 倍。
列存储索引为数据仓库工作负载提供的另一个好处是为 102,400 行或更多行的批量插入操作提供了优化的加载路径。 102,400 是直接加载到列存储中的最小值,而每个行集合(称为行组)最多可以达到约 1,024,000 行。 行组更少但更饱满,这使得 SELECT 查询更高效,因为只需扫描更少的行组就可以检索请求的记录。 这些加载发生在内存中,并直接加载到索引中。 对于较小的卷,会将数据写入称为增量存储的 B 树结构中,并异步加载到索引中。
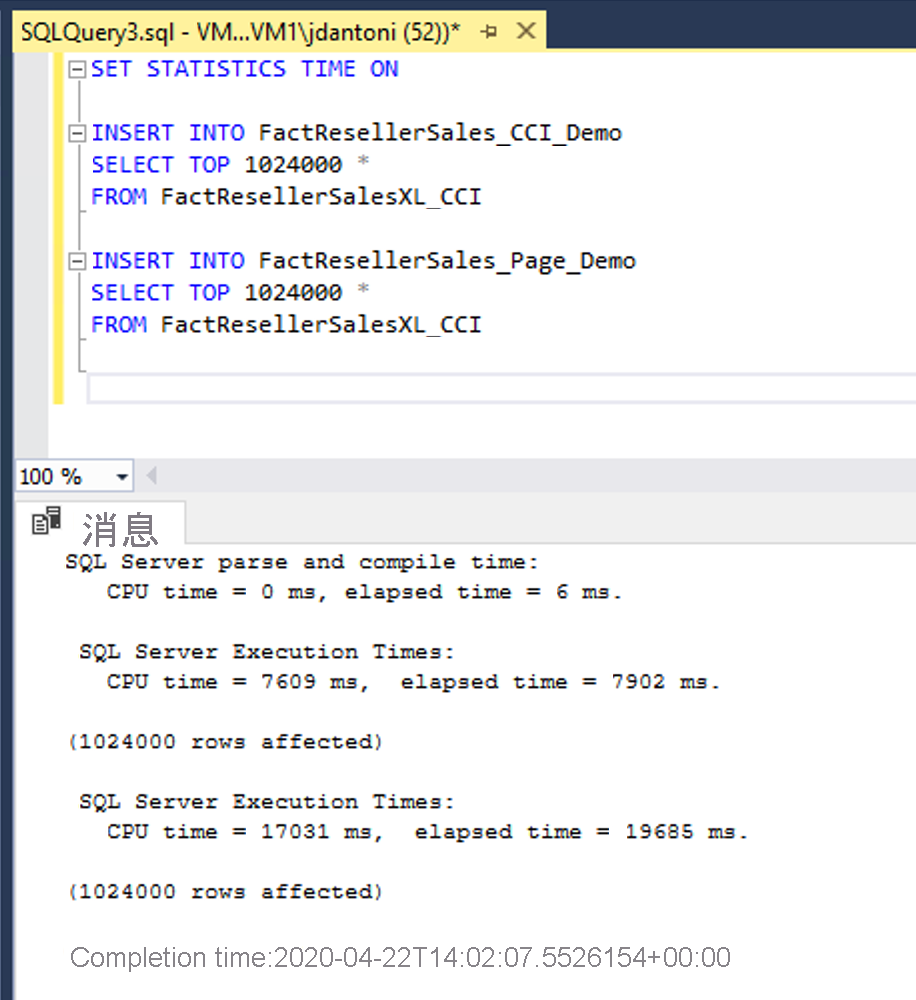
在此示例中,将相同的数据加载到 FactResellerSales_CCI_Demo 和 FactResellerSales_Page_Demo 这两个表中。 FactResellerSales_CCI_Demo 具有聚集列存储索引,而 FactResellerSales_Page_Demo 具有包含两列的聚集 B 树索引,并且已进行页压缩。 如你所见,每个表都从 FactResellerSalesXL_CCI 表中加载 1,024,000 行。 当 SET STATISTICS TIME 为 ON 时,SQL Server 可以跟踪查询执行的运行时间。 将数据加载到列存储表中大约花费了 8 秒钟,而将数据加载到页压缩的表中则花费了大约 20 秒。 在此示例中,进入列存储索引的所有行均被加载到单个行组中。
如果在单次操作中将少于 102,400 行的数据加载到列存储索引中,则会将其加载到称为增量存储的 B 树结构中。 数据库引擎使用称为元组移动器的异步过程将此数据移动到列存储索引中。 具有开放的增量存储会影响查询的性能,因为读取这些记录的效率要比从列存储中读取的效率低。 也可以使用 COMPRESS_ALL_ROW_GROUPS 选项重新组织索引,以便强制将增量存储添加并压缩到列存储索引中。