多类分类
多类分类用于预测观察结果属于多个可能的类中的哪一个。 作为一种监督式机器学习技术,它遵循与回归和二元分类相同的训练、验证和评估迭代过程,保留一部分训练数据来验证训练的模型。
示例 - 多类分类
多类分类算法用于计算多个类标签的概率值,使模型能够预测给定观察结果最有可能属于哪个类。
让我们来探讨这样一个示例:我们对企鹅进行了一些观察,记录了每只企鹅的鳍状肢长度 (x)。 每次观察的数据都包括企鹅的物种 (y),其编码如下:
- 0: Adelie
- 1:白眉企鹅
- 2:帽带企鹅
注意
与本模块中前面的示例一样,真实场景中包含多个特征 (x) 值。 我们使用单个特征来简化操作。
 |
 |
|---|---|
| 鳍状肢长度 (x) | 物种 (y) |
| 167 | 0 |
| 172 | 0 |
| 225 | 2 |
| 197 | 1 |
| 189 | 1 |
| 232 | 2 |
| 158 | 0 |
训练多类分类模型
若要训练多类分类模型,需要使用一种算法将训练数据拟合到计算每个可能的类的概率值的函数。 可以使用两种类型的算法来执行此操作:
- 一对其他 (OvR) 算法
- 多项式算法
一对其他 (OvR) 算法
一对其他算法为每个类训练一个二元分类函数,每个函数计算观察结果属于目标类示例的概率。 每个函数计算观察结果与任何其他类相比属于特定类的概率。 对于企鹅物种分类模型,该算法实质上会创建三个二元分类函数:
- f0(x) = P(y=0 | x)
- f1(x) = P(y=1 | x)
- f2(x) = P(y=2 | x)
每个算法都会生成一个 sigmoid 函数,用于计算概率值(介于 0.0 和 1.0 之间)。 使用这种算法训练的模型可以预测生成最高概率输出的函数的类。
多项式算法
另一种方法是使用多项式算法,该算法创建一个返回多值输出的函数。 输出是一个向量(值数组),其中包含所有可能的类的概率分布 - 每个类的概率得分总和为 1.0:
f(x) =[P(y=0|x), P(y=1|x), P(y=2|x)]
此类函数的一个示例是 softmax 函数,它可以生成如下所示的输出:
[0.2, 0.3, 0.5]
向量中的元素分别表示属于类 0、1 和 2 的概率;因此,在这种情况下,概率最高的类为 2。
无论使用哪种类型的算法,模型都使用生成的函数来确定一组给定特征 (x) 最可能属于哪个类,并预测相应的类标签 (y)。
评估多类分类模型
可以通过计算每个单独类的二元分类指标来评估多类分类器。 或者,可以计算将所有类都考虑在内的聚合指标。
假设我们已验证多类分类器,并得到了以下结果:
| 鳍状肢长度 (x) | 实际物种 (y) | 预测物种 (ŷ) |
|---|---|---|
| 165 | 0 | 0 |
| 171 | 0 | 0 |
| 205 | 2 | 1 |
| 195 | 1 | 1 |
| 183 | 1 | 1 |
| 221 | 2 | 2 |
| 214 | 2 | 2 |
多类分类器的混淆矩阵与二元分类器的混淆矩阵类似,只不过前者显示 预测类标签 (ŷ) 和实际类标签 (y) 的每个组合的预测数:
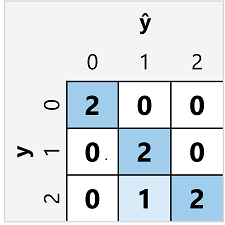
在此混淆矩阵中,可以确定每个单独类的指标,如下所示:
| 类 | TP | TN | FP | FN | 准确性 | Recall | 精度 | F1 分数 |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 5 | 0 | 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 2 | 4 | 1 | 0 | 0.86 | 1.0 | 0.67 | 0.8 |
| 2 | 2 | 4 | 0 | 1 | 0.86 | 0.67 | 1.0 | 0.8 |
若要计算整体准确度、召回率和精准率指标,请使用 TP、TN、FP 和 FN 指标的总和:
- 整体准确度 = (13+6) ÷ (13+6+1+1) = 0.90
- 整体召回率 = 6÷(6+1) = 0.86
- 整体精准率 = 6÷(6+1) = 0.86
整体 F1 分数是使用整体召回率和精准率指标计算的:
- 整体 F1 分数 = (2x0.86x0.86)÷(0.86+0.86) = 0.86