对 AlwaysOn 可用性组中的日志发送队列进行故障排除
本文提供与日志发送队列相关的问题的解决方案。
什么是日志发送队列?
对主副本(例如 INSERT, UPDATE和 DELETE)上可用性组数据库所做的更改将写入事务日志,并发送到可用性组次要副本。 日志 发送队列 定义尚未发送到次要副本的主数据库的日志文件中的日志记录数。
日志发送队列的症状和效果
日志发送队列存储所有易受攻击的数据
如果主副本在突然灾难中丢失,并且你故障转移到尚未到达这些更改的次要副本,这些更改将不会显示在数据库的新主副本副本中。 这不包括运行完整数据库和日志备份时存储的任何更改。
增加日志发送队列会导致事务日志文件增长
对于在可用性组中定义的数据库,Microsoft SQL Server 必须在主副本中保留尚未传递到次要副本的事务日志中的所有事务。 日志发送队列表示主副本的记录更改数量,这些更改在正常日志截断事件(例如,在数据库日志备份期间)无法截断。 大型且不断增长的日志发送队列可能会耗尽托管数据库日志文件的驱动器上的可用空间,或者可能超出配置的最大事务日志文件大小。 有关详细信息,请参阅 事务日志较大时的错误 9002。
各种诊断功能报告可用性组日志发送队列
SQL Server Management Studio 中的 AlwaysOn 仪表板报告日志发送队列。 它可能会报告可用性组不正常。
如何检查日志发送队列
日志发送队列是每数据库度量值。 可以使用主副本上的 Always On 仪表板或使用 主要副本或辅助副本上的sys.dm_hadr_database_replica_states 动态管理视图(DMV)来检查此值。 性能监视器计数器用于检查针对次要副本的日志发送队列。
接下来的几个部分提供了主动监视可用性组数据库日志发送队列的方法。
查询sys.dm_hadr_database_replica_state
sys.dm_hadr_database_replica_states DMV 为每个可用性组数据库报告一行。 该报表中的一列是 log_send_queue_size。 此值是日志发送队列大小(KB)。 可以设置查询,例如以下查询来监视日志发送队列大小中的任何趋势。 查询在主要副本上运行。 它使用 is_local=0 谓词报告次要副本的数据,其中 log_send_queue_size 和 log_send_rate 相关。
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
下面是输出的效果。

在 AlwaysOn 仪表板中查看日志发送队列
若要查看日志发送队列,请执行以下步骤:
通过右键单击 SSMS 对象资源管理器中的可用性组,在 SQL Server Management Studio 中打开 Always On 仪表板。
选择“ 显示仪表板”。
可用性组数据库最后列出,并且报告了一些有关数据库的数据。 尽管 默认情况下未列出日志发送队列大小(KB) 和 日志发送速率(KB/秒), 但可以将它们添加到此视图,如下一步的屏幕截图所示。
若要添加这些列,请右键单击可用性组数据库列标题,然后从可用列列表中选择。
若要 添加日志发送队列大小,请右键单击如以下屏幕截图中红色突出显示的标头。

默认情况下,AlwaysOn 仪表板每 60 秒自动刷新一次此数据。



查看性能监视器中的日志发送队列
日志发送队列特定于每个辅助副本数据库。 因此,若要查看可用性组数据库的日志发送队列,请执行以下步骤:
在次要副本上打开性能监视器。
选择“添加”(计数器)按钮。
在“可用计数器”下,选择“SQLServer:数据库副本”和“日志发送队列”计数器。
在 “实例 列表”框中,选择要检查日志发送队列的可用性组数据库。
选择“添加”和“确定”。
下面是增加日志发送队列的外观。


解释日志发送队列值
本部分介绍如何解释日志发送队列大小的值。
日志发送队列何时不正确? 应容忍多少日志发送队列?
你可能假设日志发送队列报告值 0,这意味着该报告时不会发生日志发送队列。 但是,当生产环境繁忙时,应该会看到日志发送队列经常报告非零的值,即使在正常的 AlwaysOn 环境中也是如此。 在典型生产期间,应会看到此值在 0 与非零值之间波动。
如果观察到日志发送队列随时间推移增加,需要进一步调查。 此额外活动指示某些内容已更改。 如果在日志发送队列中观察到突然增长,以下度量值可用于故障排除:
- 日志发送速率 (KB/秒) (AlwaysOn 仪表板)
- sys.dm_hadr_database_replica_states (DMV)
- 数据库副本::镜像事务数/秒(性能监视器)
获取日志发送速率和镜像事务的基线速率/秒
在正常的 AlwaysOn 性能期间,监视 繁忙可用性组数据库的日志发送速率 和 镜像事务数/秒 值。 在通常繁忙的工作时间,他们看起来是什么样子? 在维护期间,当大型事务驱动系统上更高的事务吞吐量时,它们看起来是什么样子? 观察日志发送队列增长时,可以比较这些值,以帮助确定已更改的内容。 工作负荷可能大于平常。 如果日志发送速率低于平常,可能需要进一步调查来确定原因。
工作负荷卷很重要
如果工作负荷较大(例如 UPDATE 针对 100 万行的语句),索引会重新生成 1 TB 表,甚至插入数百万行的 ETL 批处理),则应该会看到一些日志发送队列增长(即立即或随着时间的推移)。 当可用性组数据库中突然发生大量更改时,这一点是预期的。
如何诊断日志发送队列
确定特定可用性组数据库的日志发送队列后,应按照以下各节中所述检查此问题的几个可能的根本原因。
重要
对于有意义的等待类型输出,请使用在监视以下条件时,使用前面部分所述的方法之一检查日志发送队列的增加情况。
系统太忙
检查主副本上的工作负荷是否重载系统的 CPU。 如果日志发送队列增加,请查询 sys.dm_os_schedulers DMV 并监视 high runnable_tasks_count。 此计数表示当时运行的未完成任务。
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
下表是结果示例。 值增加 runnable_tasks_count 表示大量任务正在等待 CPU 时间。
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | 可见脱机 | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE ONLINE | 104 | 16 | 116 | 103 |
解决方案:如果检测到高 runnable_task_count,请减少系统上的工作负荷或增加系统可用的 CPU 数。
网络延迟
如果次要副本在物理上与主要副本远程,则这种情况尤其常见。 多站点可用性组允许客户跨多个站点部署业务数据的副本,以便进行灾难恢复和报告。 这使得对远程位置的生产数据副本进行近乎实时的更改。
如果辅助副本托管在远离主副本的远端,则日志发送队列可能是网络延迟造成的,并且无法像在主副本数据库中生成一样快地将更改发送到远程辅助副本。
重要
SQL Server 使用单个连接将主副本的更改同步到次要副本。 因此,如果次要副本是远程副本,管道的宽度不会影响 SQL Server 可以发送的数据量。 相反,此数量更依赖于管道中的网络延迟(连接速度)。
测试网络延迟
检查流控制设置是否导致网络延迟
Microsoft SQL Server 可用性组使用流控制门,以避免在所有可用性副本上过度消耗网络资源、内存和其他资源。 这些流控制门不会影响可用性副本的同步运行状况状态。 但是,它们可能会影响可用性数据库的整体性能,包括 RPO。
更高版本的 SQL Server 会更改输入流控制的阈值。 这有助于缓解流控制对日志发送队列等症状的影响。 有关流控制以及流控制阈值更改的历史记录的详细信息,请参阅 流控制入口。
可以使用性能监视器捕获主要副本上的数据来监视流控制。 若要监视数据库流控制,请添加 SQLServer:Database Replica 计数器,然后选择 数据库流控制延迟 和 数据库流控制/秒 计数器。 在 “实例 ”对话框中,选择要检查数据库流控制的可用性组数据库。 若要检测和监视可用性副本流控制,请添加 SQLServer:Availability Replica 计数器,然后选择 “流控制时间”(ms/秒) 和 “流控制/秒 ”计数器。
检查拥塞 Windows 重启是否导致网络延迟
导致日志发送队列的网络性能问题可以通过将 拥塞 Windows 重启 TCP 设置设置为 True 来触发。 这是 Windows Server 2016 中的默认设置。 请确保 在观察到日志发送队列的主机可用性组副本的 Windows 服务器上将“拥塞窗口重启 ”设置为 False 。
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart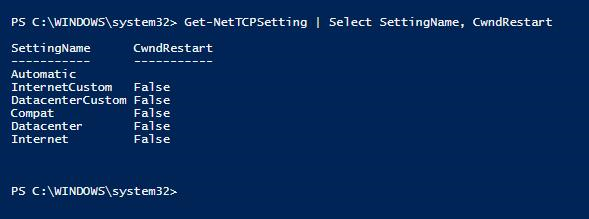
有关如何将 TCP 拥塞 Windows 重启属性设置为 False 的详细信息,请参阅 Set-NetTCPSetting (NetTCPIP)。
另请参阅 AlwaysOn 可用性组 的监视性能,了解有关同步过程的信息。 本文还介绍如何计算一些关键指标,并提供指向某些常见性能故障排除方案的链接。
使用 ping 获取延迟示例
在 node1(主副本)上的命令行上,ping node2(次要副本):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101ms使用独立工具测试从主数据库到辅助数据库的网络吞吐量
使用 NTttcp 等工具通过单个连接独立检测主要副本和辅助副本之间的网络吞吐量。 网络延迟是日志发送队列的常见原因。 以下步骤演示如何使用独立的工具(如 NTttcp)来度量网络吞吐量。
重要
SQL Server 使用单个连接将主要副本的更改发送到辅助副本。 在下一部分中,我们将配置并运行 NTttcp 以使用单个连接(与 SQL Server 相同的方式)准确比较吞吐量。
可以从 Github 下载 NTttcp - microsoft/ntttcp。
若要运行 NTttcp,请执行以下步骤:
下载该工具并将其复制到基于 SQL Server 的主服务器和辅助服务器。
在辅助副本服务器上,打开提升的命令提示符窗口,将目录更改为 NTttcp 工具文件夹,然后运行以下命令:
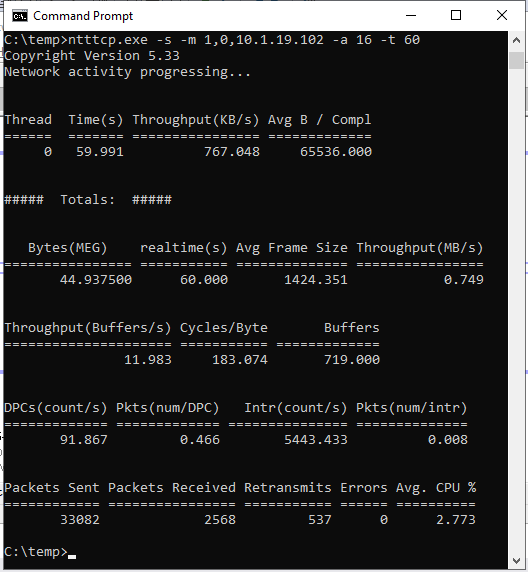
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60注意
在此命令中,
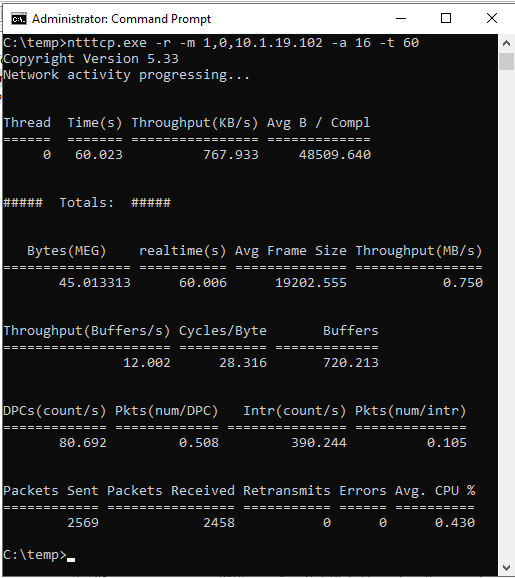
<secondaryipaddress>是辅助副本服务器的实际 IP 地址的占位符。在主副本服务器上,打开提升的命令提示符窗口,将目录更改为 NTttcp 工具文件夹,然后再次指定辅助副本服务器的实际 IP 地址,运行以下命令:
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60以下屏幕截图显示了在辅助副本和主要副本上运行的 NTttcp。 由于网络延迟,该工具只能发送 739 KB/秒的数据。 这就是你期望 SQL Server 能够发送的内容。
次要副本上的 NTttcp
主副本上的 NTttcp
查看性能监视器计数器
验证 NTttcp 报告的内容。 大型事务在主副本上的 SQL Server 中运行。 在主副本上启动性能监视器后,添加网络接口::字节发送/秒计数器。 此计数器确认主副本可以发送大约 777 KB/秒的数据。 这类似于 NTttcp 测试报告的 739 KB/秒的值。

将主副本上的 SQL Server::D atabases::Log Bytes Flushed/sec 值与辅助副本上同一数据库的 SQL Server::D atabase Replica::Log Bytes Received/sec 进行比较也很有用。 平均而言,我们观察到在“agdb”数据库中创建的更改数约为 20 MB/秒。 但是,次要副本平均只接收 5.4 MB 的更改。 这将导致日志在尚未发送到辅助副本的数据库事务日志中未完成更改的主副本上发送队列。
“agdb”数据库的主要副本日志字节刷新/秒

数据库 agdb 接收的次要副本日志字节数/秒
