建置及訓練自訂分類模型
此內容適用於: v4.0 (GA) | 舊版:![]()
![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
自定義分類模型可以將輸入檔中的每個頁面分類,以識別內的一或多個檔。 分類器模型也可以識別輸入檔中單一文件的多個文件或多個執行個體。 Document Intelligence 自訂模型需要每個文件類別至少有五個訓練文件才能開始使用。 若要開始訓練自訂分類模型,每個類別需要至少有五個文件和兩個類別的文件。
自訂分類模型輸入需求
確定訓練資料集遵 Document Intelligence 的輸入需求。
支援的檔案格式:
模型 PDF 影像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML參閱 ✔ ✔ ✔ 版面配置 ✔ ✔ ✔ 一般文件 ✔ ✔ 預建 ✔ ✔ 自訂擷取 ✔ ✔ 自訂分類 ✔ ✔ ✔ 若要得到最佳結果,請為每個文件提供一張清晰的照片或高畫質的掃描檔案。
若使用 PDF 和 TIFF,最多可處理 2,000 頁 (若使用免費層訂閱,則只會處理前兩頁)。
付費 (S0) 層分析文件的檔案大小為 500 MB,免費 (F0) 層則為
4MB。影像維度必須介於 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之間。
如果您的 PDF 有密碼鎖定,則必須先移除鎖定才能提交。
針對 1024 x 768 像素影像的擷取文字高度下限為 12 像素。 此維度在 150 點/英吋 (DPI) 時大約相當於
8點文字。針對自訂模型定型,自訂範本模型的定型資料頁數上限為 500,而自訂神經網路模型的上限則為 50,000。
對於自訂擷取模型定型,範本模型的定型資料大小總計為 50 MB,而神經模型的大小總計則為
1GB。針對自訂分類模型定型,定型資料的大小總計為
1GB (上限為 10,000 頁)。 對於 2024-11-30 (GA),訓練數據的總大小為2GB,最多 10,000 頁。
定型資料秘訣
請遵循下列秘訣進一步最佳化資料集,以便進行定型:
可能的話,使用以文字為基礎的 PDF 文件,而非以影像為基礎的文件。 掃描的 PDF 將視為影像處理。
如果您的表單影像品質較低,請使用較大的資料集 (例如 10-15 影像)。
上傳定型資料集
彙整用於定型的表單集或文件集之後,您必須將其上傳至 Azure Blob 儲存體容器。 如果您不知道如何使用容器建立 Azure 儲存體帳戶,請遵循適用於 Azure 入口網站的 Azure 儲存體快速入門。 您可以使用免費定價層 (F0) 來試用服務,之後可升級至付費層以用於生產環境。 如果您的資料集組織為資料夾,請保留該結構,因為 Studio 可以使用標籤的資料夾名稱來簡化標記流程。
在 Document Intelligence Studio 中建立分類專案
Document Intelligence Studio 提供並協調完成資料集和訓練模型所需的所有 API 呼叫。
首先,瀏覽至 Document Intelligence Studio。 首次使用工作室時,您必須初始化訂閱、資源群組和資源。 然後,依照自訂專案的必要條件來設定工作室,以存取您的定型資料集。
在 Studio 中選取 [自訂分類模型] 圖格,然後在頁面上的自訂模型區段上選取 [建立專案] 按鈕。
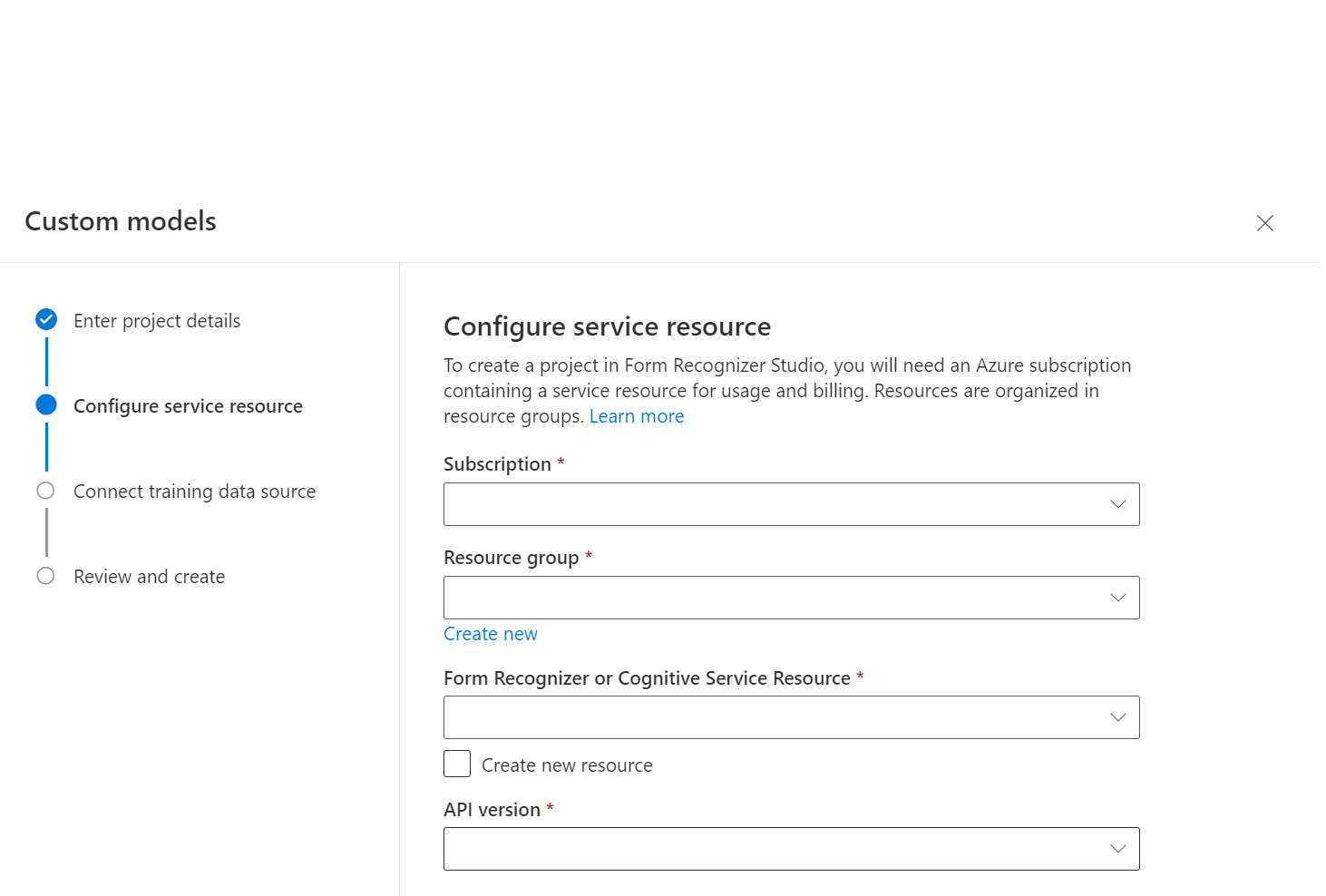
在
Create Project對話方塊中,提供專案名稱、提供描述 (選擇性),然後選取繼續。接下來,選擇或選取 [建立文件智慧] 資源,再繼續。
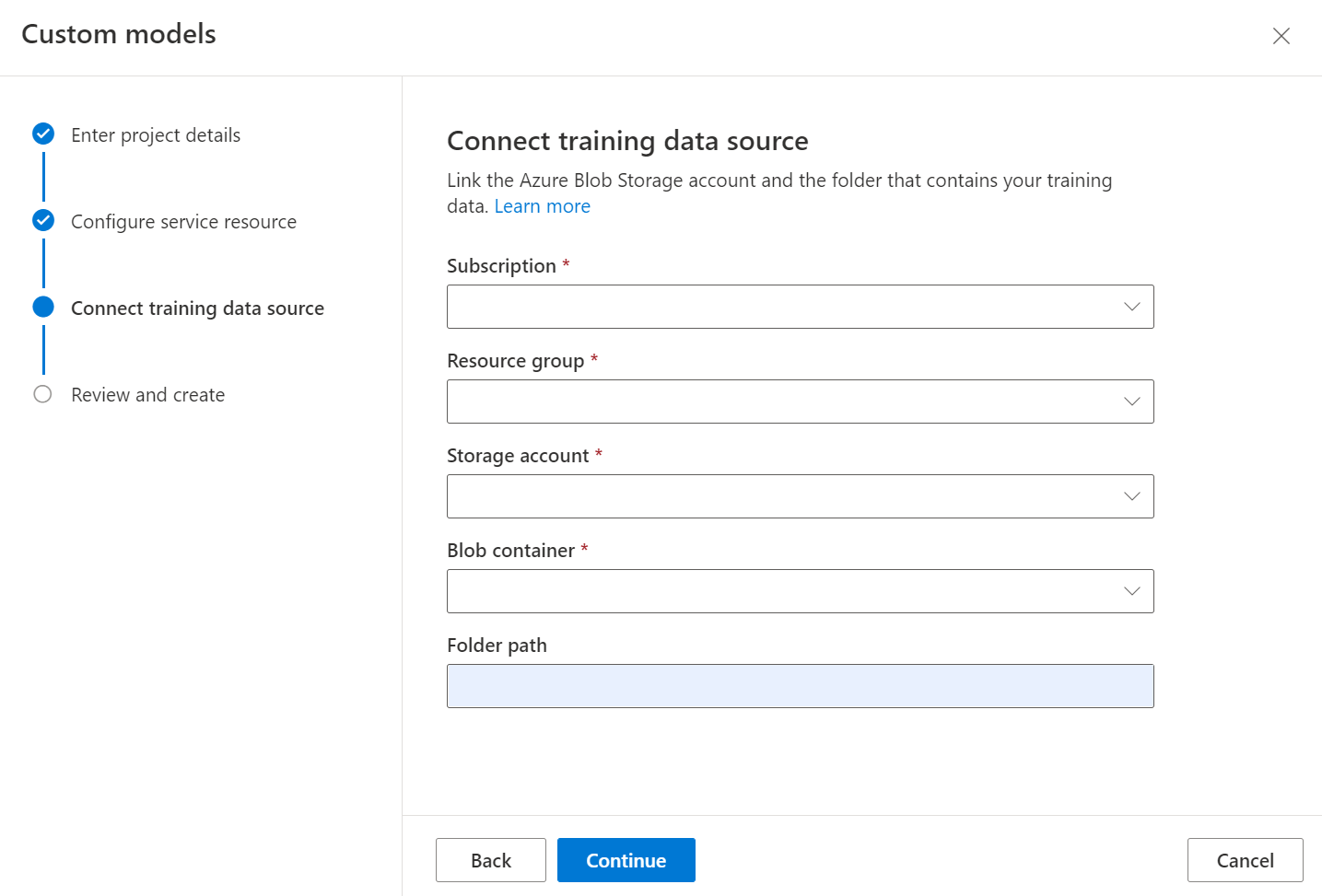
接下來,選取您上傳自訂模型定型資料集時使用的儲存體帳戶。 如果您的定型文件在容器的根目錄中,則資料夾路徑應該是空的。 如果文件位於子資料夾中,請在 [資料夾路徑] 欄位中輸入容器根目錄的相對路徑。 設定儲存體帳戶後,請選取 [繼續]。
重要
您可按資料夾來整理訓練資料集,其中資料夾名稱是文件的標籤或分類,或建立可在 Studio 中為其指派標籤的文件一般清單。
訓練自訂分類器需要資料集內每個文件的配置模型輸出。 在模型定型程式之前,對所有文件執行版面配置。
最後,檢閱您的專案設定,然後選取 [建立專案] 以建立新的專案。 您現在應該位於標記視窗中,並看見您資料集中的檔案列出。
標記您的資料
在您的專案中,您只需要使用適當的類別標籤來標記每個文件。
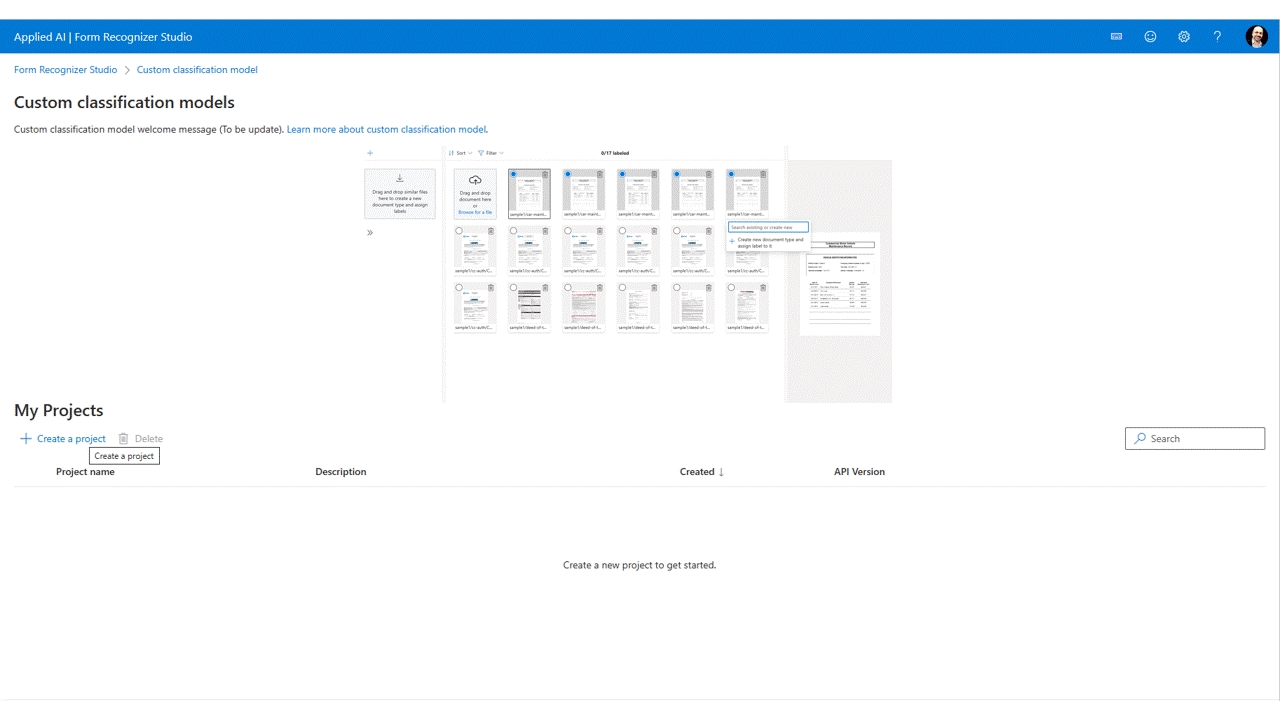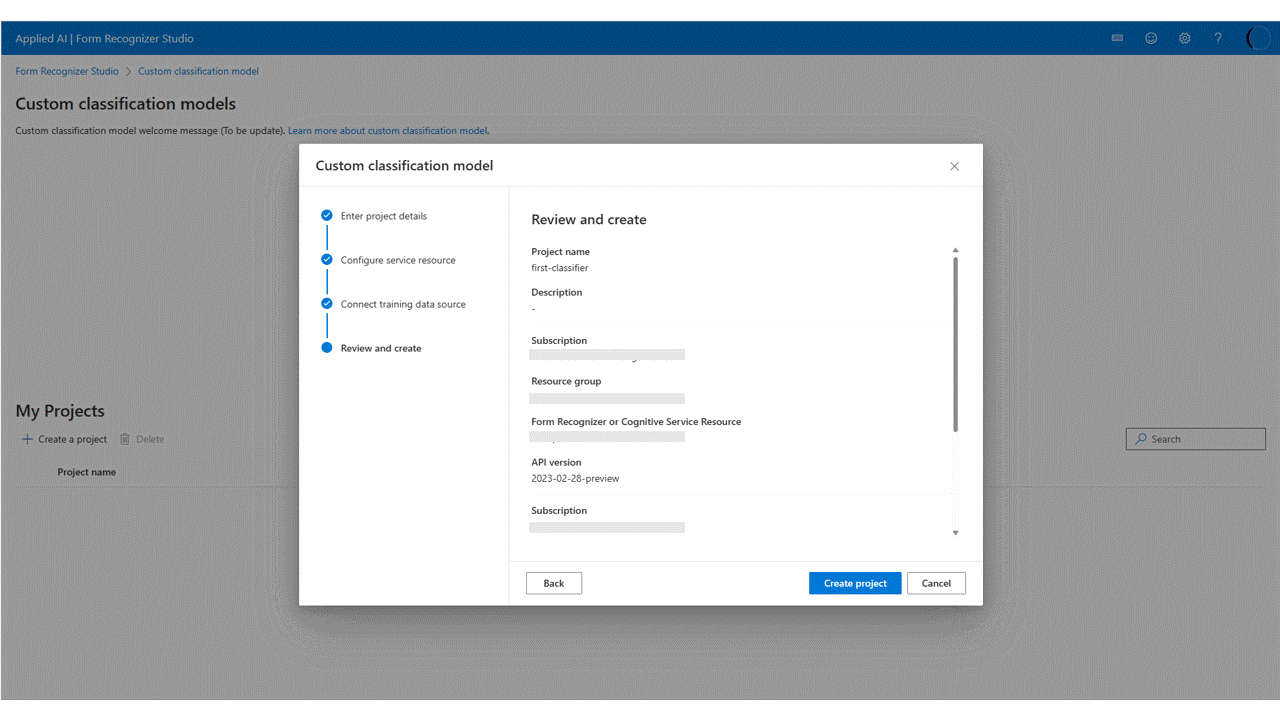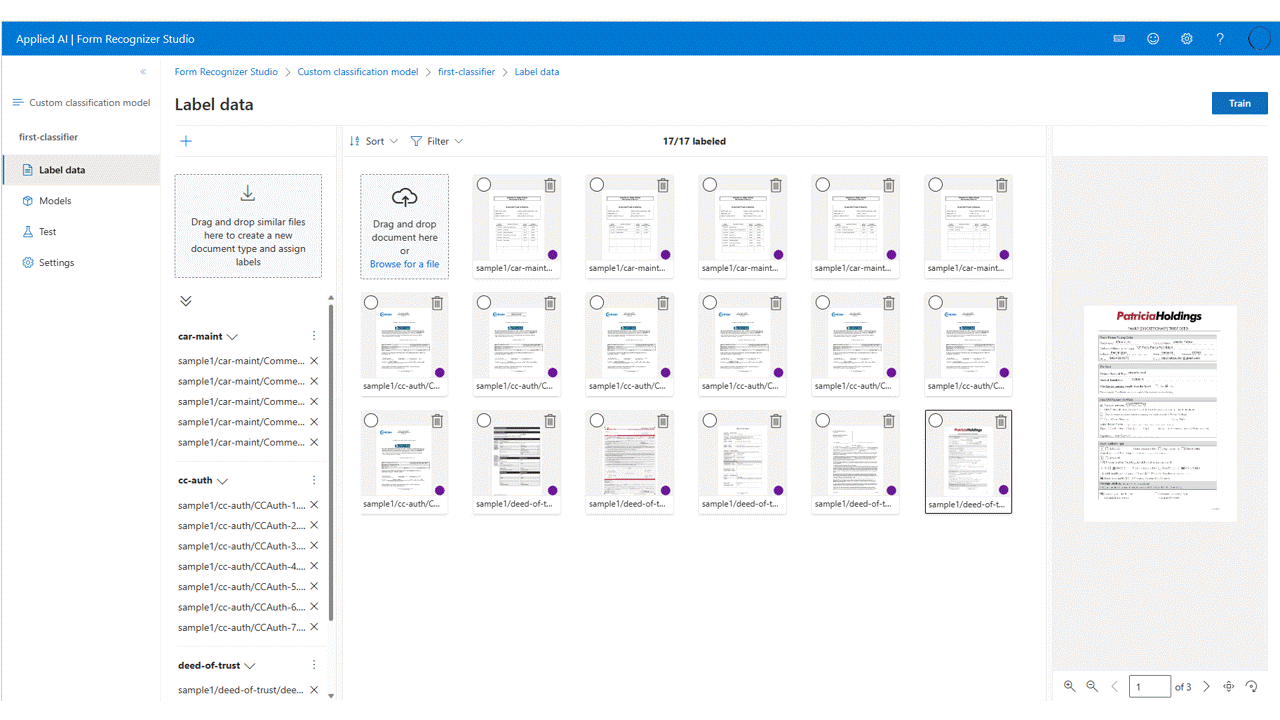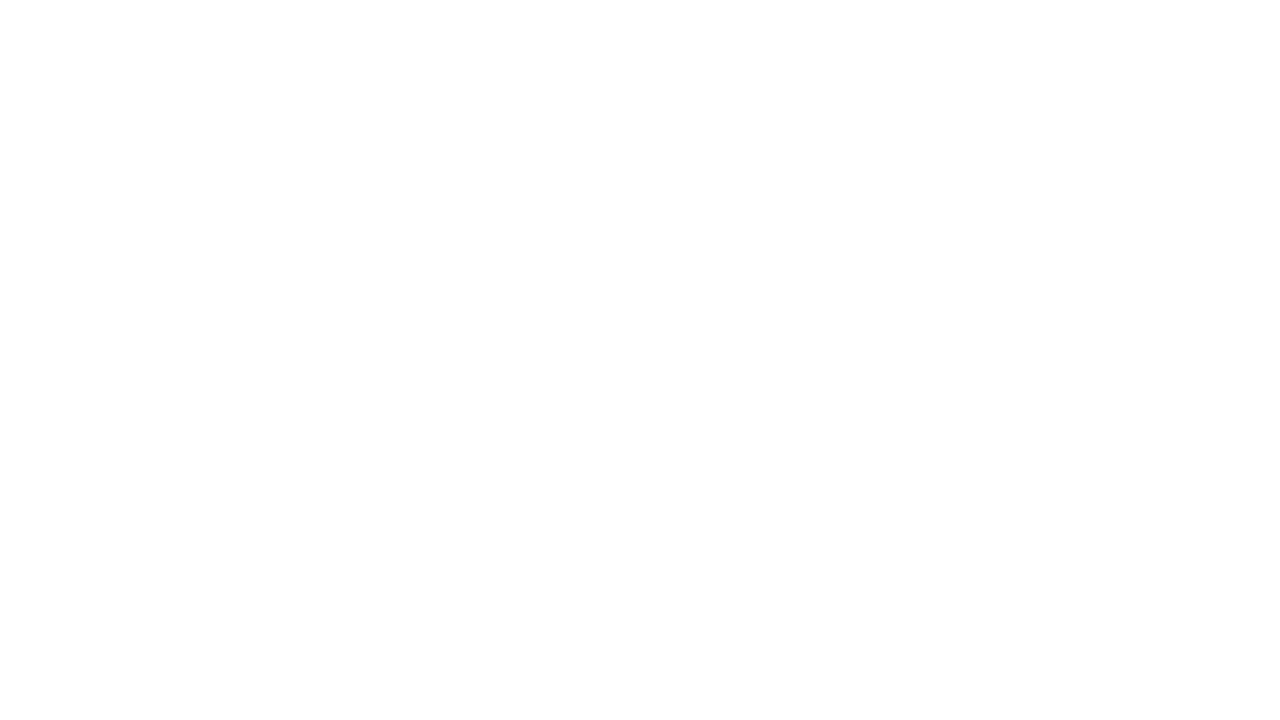
檔案清單會顯示已上傳至儲存體的文件,準備好進行標記。 您有幾個選項可以標記資料集。
如果文件組織在資料夾中,Studio 會提示您使用資料夾名稱做為標籤。 此步驟可將標記簡化為單一選取。
若要將標籤指派給檔,請選取
add label selection mark以指派標籤。控制選取多重選取文件以指派標籤
您現在應已標示資料集中的所有文件。 如果查看儲存體帳戶,您會發現對應至訓練資料集中每個文件的 .ocr.json 檔案,以及每個已標記類別的新 class-name.jsonl 檔案。 系統會提交此訓練資料集來訓練模型。
定型您的模型
標記資料集後,您現在已準備好定型模型。 選取右上方的 [定型] 按鈕。
在訓練模型對話方塊中,提供唯一的分類器識別碼,並可選擇是否提供描述。 分類器識別碼接受字串資料類型。
選取 [定型] 以起始定型流程。
分類器模型會在幾分鐘內訓練。
瀏覽至 [模型] 功能表,以檢視定型作業的狀態。
測試模型
模型定型完成後,您可以在模型清單頁面上選取模型以測試模型。
選取模型,然後選取 [測試] 按鈕。
瀏覽檔案或將檔案卸載至文件選取器,以新增檔案。
選取檔案後,選擇 [分析] 按鈕以測試模型。
模型結果會顯示為已識別的文件清單、所識別每個文件的信賴分數,以及所識別每個文件的頁面範圍。
藉由評估每個已識別的文件的結果,驗證您的模型。
使用 SDK 或 API 定型自訂分類器
工作室會協調 API 呼叫,讓您定型自訂分類器。 分類器定型資料集需要來自版面配置 API 的輸出,以符合用於定型模型的 API 版本。 使用舊版 API 的版面配置結果可能會導致模型正確性偏低。
如果資料集不包含版面配置結果,工作室會產生定型資料集的版面配置結果。 使用 API 或 SDK 來定型分類器時,您必須將版面配置結果新增至包含個別文件的資料夾。 直接呼叫版面配置時,版面配置結果的格式應為 API 回應的格式。 SDK 物件模型不同。 請確定 layout results 是 API 結果,而不是 SDK response。
疑難排解
分類模型需要每個訓練文件的配置模型結果。 如果您沒有提供版面配置結果,Studio 會先嘗試執行每個檔的版面配置模型,然後再將分類器定型。 此流程會受到節流處理,而且可能會導致 429 回應。
在 Studio 中,使用分類模型進行定型之前,請在每份文件上執行 版面配置模型 ,並將它上傳至與源檔相同的位置。 新增配置結果之後,即可使用文件來訓練分類器模型。