文件智慧服務一般文件模型
重要
從 Document Intelligence 4.0 版預覽版 開始,未來會淘汰一般檔模型(prebuilt-document)。 若要從文件中擷取索引鍵值組、選取標記、文字、資料表和結構,請使用下列模型:
| 功能 | version | Model ID |
|---|---|---|
啟用了選用查詢字串參數 features=keyValuePairs 的 Layout 模型。 |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| 一般文件模型 | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
此內容適用於: v3.1 (GA) | 最新版本: ![]()
![]() v4.0 (GA) | 舊版:
v4.0 (GA) | 舊版: ![]() v3.0
v3.0
此內容適用於: v3.0 (GA) | 最新版本:![]()
![]() v4.0 (GA)
v4.0 (GA)![]() v3.1
v3.1
一般文件模型結合了功能強大的光學字元辨識 (OCR) 功能與深度學習模型,可從文件中擷取機碼值組、資料表和選取標記。 一般文件可透過 v3.1 和 v3.0 API 取得。 如需詳細資訊,請參閱我們的移轉指南。
一般文件功能
一般文件模型是預先定型的模型;不需要標籤或定型。
單一 API 會從文件擷取機碼值組、選取標記、文字、資料表和結構。
一般文件模型支援結構化、半結構化和非結構化文件。
選取標記會識別為值為
:selected:或:unselected:的欄位。
文件智慧服務工作室中處理的範例文件
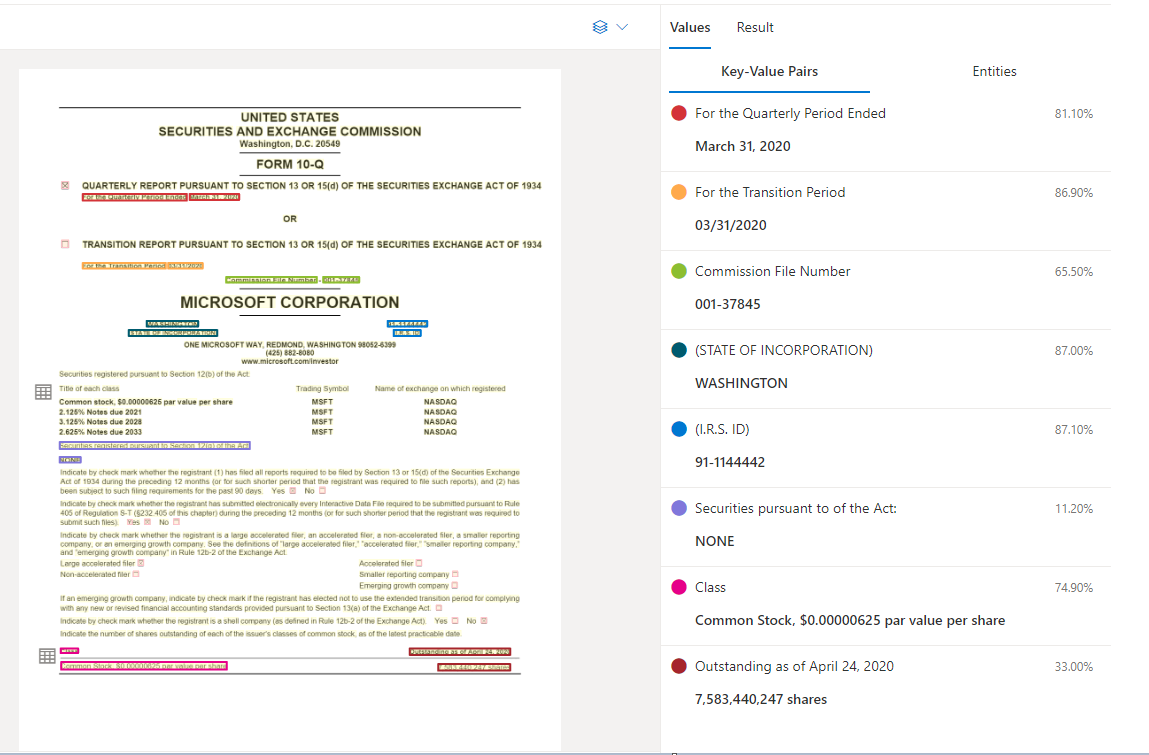
機碼值組擷取
一般文件 API 支援大部分的表單類型,將分析文件並擷取索引鍵和相關值。 它非常適合從文件擷取常見的索引鍵/值組。 您可以使用一般文件模型來替代不使用標籤來定型的自訂模型。
開發選項
文件智慧服務 v3.1 支援下列工具、應用程式和程式庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 一般文件模型 | • 文件智慧服務工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
文件智慧服務 v3.0 支援下列工具、應用程式和程式庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 一般文件模型 | • 文件智慧服務工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
輸入需求
支援的檔案格式:
模型 PDF 影像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML參閱 ✔ ✔ ✔ 版面配置 ✔ ✔ ✔ 一般文件 ✔ ✔ 預建 ✔ ✔ 自訂擷取 ✔ ✔ 自訂分類 ✔ ✔ ✔ 若要得到最佳結果,請為每個文件提供一張清晰的照片或高畫質的掃描檔案。
若使用 PDF 和 TIFF,最多可處理 2,000 頁 (若使用免費層訂閱,則只會處理前兩頁)。
付費 (S0) 層分析文件的檔案大小為 500 MB,免費 (F0) 層則為
4MB。影像維度必須介於 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之間。
如果您的 PDF 有密碼鎖定,則必須先移除鎖定才能提交。
針對 1024 x 768 像素影像的擷取文字高度下限為 12 像素。 此維度在 150 點/英吋 (DPI) 時大約相當於
8點文字。針對自訂模型定型,自訂範本模型的定型資料頁數上限為 500,而自訂神經網路模型的上限則為 50,000。
對於自訂擷取模型定型,範本模型的定型資料大小總計為 50 MB,而神經模型的大小總計則為
1GB。針對自訂分類模型定型,定型資料的大小總計為
1GB (上限為 10,000 頁)。 對於 2024-11-30 (GA),訓練數據的總大小為2GB,最多 10,000 頁。
一般文件模型資料擷取
請嘗試使用文件智慧服務工作室來擷取表單和文件中的資料。
您需要下列資源:
一個 Azure 訂用帳戶 - 您可以建立一個免費訂用帳戶。
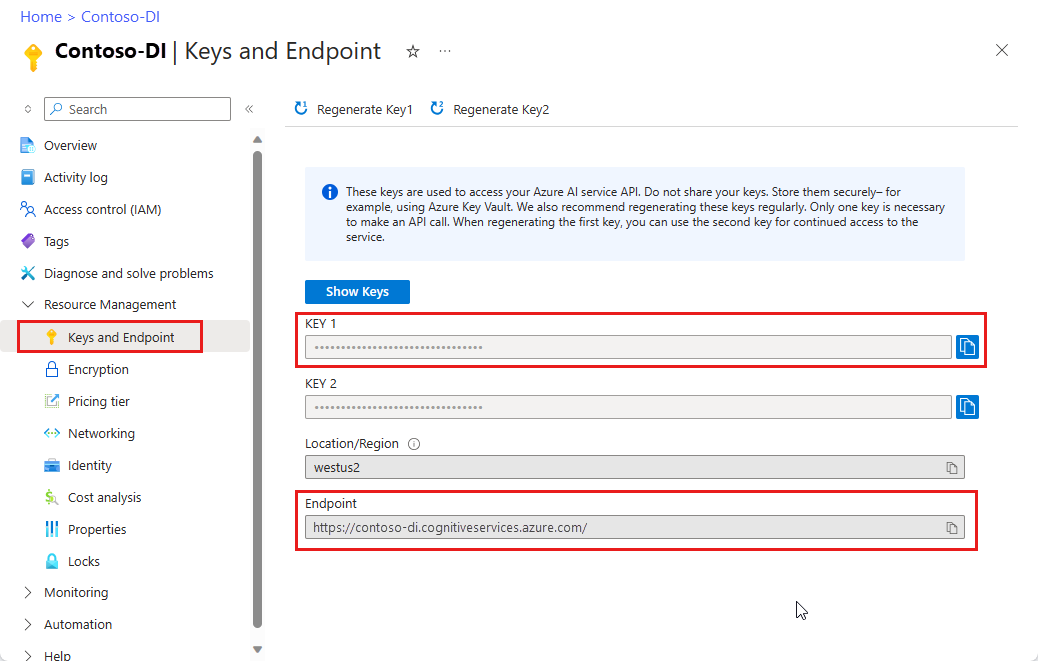
Azure 入口網站中的 Document Intelligence 執行個體。 您可以使用免費定價層 (
F0) 來試用服務。 部署資源後,選取 [前往資源] 以取得金鑰和端點。
注意
文件智慧服務工作室和一般文件模型可透過 v3.0 API 取得。
在文件智慧服務工作室首頁上,選取 [一般文件]。
您可以分析範例文件,或上傳您自己的檔案。
選取 [執行分析] 按鈕,如有必要,設定 [分析選項]:
![文件智慧服務工作室中 [執行分析] 和 [分析選項] 按鈕的螢幕擷取畫面。](../media/studio/run-analysis-analyze-options.png?view=doc-intel-3.0.0)
索引鍵/值組
索引鍵/值組是文件內的特定範圍,其識別標籤或索引鍵,及其相關的回應或值。 在結構化表單中,這些組別可能是標籤,以及使用者為該欄位輸入的值。 在非結構化文件中,它們可能是根據段落中文字內容而得的合約執行日期。 AI 模型已經過定型,可以根據各種不同的文件類型、格式和結構來擷取可識別的索引鍵和值。
若模型偵測到索引鍵存在,且沒有相關聯的值或處理選用欄位時,索引鍵也可以單獨存在。 例如,在某些情況下,表單上的中間名欄位可以留空。 索引鍵/值組是文件中所包含的文字範圍。 若是文件對相同的值有不同的描述方式,例如客戶/使用者,則相關聯的關鍵為客戶或使用者,視前後文而定。
資料擷取
| 模型 | 文字擷取 | 索引鍵/值組 | 選取標記 | 表格 | 一般名稱 |
|---|---|---|---|---|---|
| 一般文件 | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - 僅適用於 2023-07-31 (v3.1 GA) 及更新版本的 API。
支援的語言和地區設定
如需支援語言的完整清單,請參閱我們的語言支援—文件分析模型頁面。
考量
因為索引鍵是從文件中擷取的文字範圍,所以對於半結構化文件,索引鍵需要對應到現有的索引鍵字典。
預期會看到帶有索引鍵的索引鍵/值組,但沒有值。 例如,如果使用者選擇不在表單上提供電子郵件地址。
下一步
請遵循我們的文件智慧服務 v3.1 移轉指南 (部分機器翻譯),了解如何在應用程式和工作流程中使用 v3.1 版本。
探索我們的 REST API。