快取是改善系統的效能和可擴縮性的常用技術。 它會將經常存取的數據暫時複製到靠近應用程式的快速記憶體,以快取數據。 如果這個快速資料儲存體比原始來源的位置更接近應用程式,則快取可以透過更快速地提供資料,大幅改善用戶端應用程式的回應時間。
當客戶端實例重複讀取相同的數據時,快取最有效,特別是當下列所有條件都套用至原始資料存放區時:
- 它仍然相對靜態。
- 相較於快取的速度是緩慢的。
- 高度受限於競爭。
- 當網路等待時間可能會造成存取速度變慢時,就很遙遠了。
分散式應用程式中的快取
分散式應用程式通常會在快取數據時實作下列其中一種或兩種策略:
- 他們會使用私用快取,其中數據會保留在執行應用程式或服務實例的計算機上本機。
- 它們會使用共用快取,做為多個進程和機器可存取的通用來源。
在這兩種情況下,快取都可以執行用戶端和伺服器端。 用戶端快取是由提供系統使用者介面的程式所完成,例如網頁瀏覽器或桌面應用程式。 伺服器端快取是由提供遠端執行之商務服務的程式所完成。
私人快取
最基本的快取類型是記憶體內部存放區。 它會保留在單一進程的位址空間中,並由在該進程中執行的程式代碼直接存取。 這種類型的快取可快速存取。 它也可以提供儲存少量靜態數據的有效方法。 快取的大小通常會受限於裝載進程之計算機上可用的記憶體數量。
如果您需要快取比記憶體中實際可能更多的資訊,您可以將快取的數據寫入本機文件系統。 此程式存取速度會比記憶體中保留的數據慢,但應該比跨網路擷取數據更快且更可靠。
如果您有多個使用此模型同時執行的應用程式實例,則每個應用程式實例都有自己的獨立快取,並保存自己的數據複本。
將快取視為過去某個時間點原始數據的快照集。 如果此數據不是靜態的,則不同的應用程式實例可能會在其快取中保存不同版本的數據。 因此,這些實例所執行的相同查詢可以傳回不同的結果,如圖 1 所示。
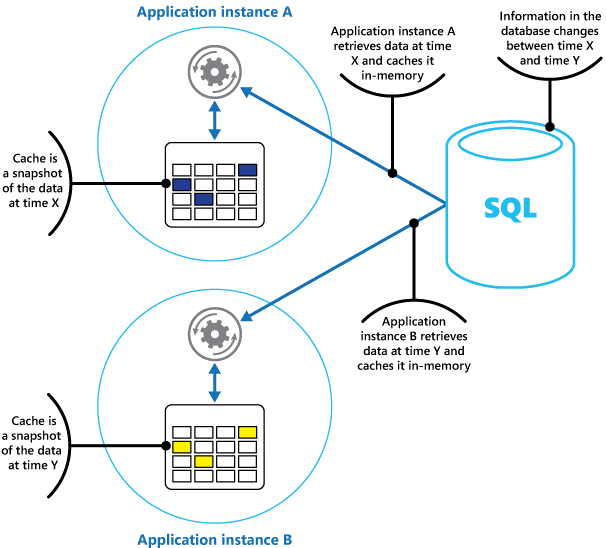
圖 1:在不同的應用程式實例中使用記憶體內部快取。
共用快取
如果您使用共用快取,可協助緩解每個快取中數據可能不同的擔憂,這可能會隨著記憶體內部快取而發生。 共用快取可確保不同的應用程式實例看到相同的快取數據檢視。 它會在個別的位置中找出快取,通常裝載為個別服務的一部分,如圖 2 所示。
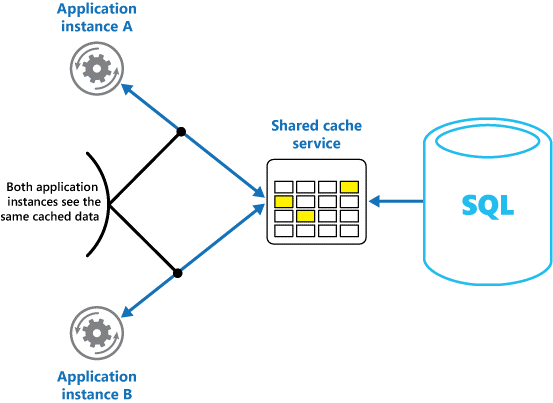
圖 2:使用共用快取。
共用快取方法的重要優點是其提供的延展性。 許多共用快取服務都是使用伺服器叢集來實作,並使用軟體以透明方式將數據分散到叢集。 應用程式實例只會將要求傳送至快取服務。 基礎結構會決定叢集中快取數據的位置。 您可以藉由新增更多伺服器,輕鬆地調整快取。
共用快取方法有兩個主要缺點:
- 快取存取速度較慢,因為它不再保留在本機的每個應用程式實例。
- 實作個別快取服務的需求可能會為解決方案增加複雜性。
使用快取的考慮
下列各節將詳細說明設計和使用快取的考慮。
決定何時快取數據
快取可以大幅改善效能、延展性和可用性。 您擁有的數據越多,需要存取此數據的用戶數目愈多,快取的優點就越大。 快取可減少與處理原始數據存放區中大量並行要求相關聯的延遲和爭用。
例如,資料庫可能支援有限數目的並行連線。 不過,從共用快取擷取數據,而不是基礎資料庫,可讓用戶端應用程式存取此數據,即使目前可用的連線數目已用盡也一樣。 此外,如果資料庫變得無法使用,用戶端應用程式可能會繼續使用快取中保存的數據。
請考慮快取經常讀取但不常修改的數據(例如,讀取作業比例高於寫入作業的數據)。 不過,我們不建議您使用快取作為重要資訊的權威存放區。 相反地,請確定應用程式無法承受遺失的所有變更一律會儲存至永續性數據存放區。 如果快取無法使用,您的應用程式仍然可以使用資料存放區繼續運作,而且不會遺失重要資訊。
判斷如何有效地快取數據
有效使用快取的索引鍵在於判斷要快取的最適當數據,並在適當的時間快取它。 數據可以在應用程式第一次擷取數據時視需要新增至快取。 應用程式只需要從數據存放區擷取數據一次,而且可以使用快取滿足後續存取。
或者,快取可以事先部分或完整填入數據,通常是在應用程式啟動時(稱為植入的方法)。 不過,不建議實作大型快取的植入,因為此方法可能會在應用程式開始執行時,對原始數據存放區造成突然、高負載。
使用模式的分析通常可協助您決定是否要完整或部分預先填入快取,以及選擇要快取的數據。 例如,您可以為定期使用應用程式的客戶植入靜態使用者配置檔數據快取,但對於每周只使用應用程式一次的客戶來說,則不會植入快取。
快取通常適用於不可變或不常變更的數據。 範例包括電子商務應用程式中的產品和定價資訊,或成本高昂的共用靜態資源等參考資訊。 部分或全部的數據都可以在應用程式啟動時載入快取,以將對資源的需求降到最低,並改善效能。 您可能也想要有一個背景程式,定期更新快取中的參考數據,以確保其為最新狀態。 或者,背景進程可以在參考數據變更時重新整理快取。
雖然此考慮有一些例外狀況,但快取對動態數據不太有用(如需詳細資訊,請參閱本文稍後的快取高度動態數據一節)。 當原始數據定期變更時,快取的資訊會很快過時,或同步處理快取與原始數據存放區的額外負荷會降低快取的效率。
快取不需要包含實體的完整數據。 例如,如果數據項代表多重值物件,例如具有名稱、地址和帳戶餘額的銀行客戶,其中一些元素可能會保持靜態,例如名稱和位址。 其他元素,例如帳戶餘額,可能更動態。 在這些情況下,快取數據的靜態部分,並在需要時只擷取其餘資訊(或計算)會很有用。
建議您執行效能測試和使用分析,以判斷預先填入或隨選載入快取,或兩者的組合是否適當。 決策應以數據的波動性和使用模式為基礎。 快取使用率和效能分析在遇到大量負載且必須高度可調整的應用程式中很重要。 例如,在可高度擴充的案例中,您可以植入快取,以減少尖峰時間的數據存放區負載。
快取也可以用來避免在應用程式執行時重複計算。 如果作業轉換數據或執行複雜的計算,它可以將作業的結果儲存在快取中。 如果之後需要相同的計算,應用程式可以直接從快取擷取結果。
應用程式可以修改快取中保存的數據。 不過,我們建議將快取視為隨時可能消失的暫時性數據存放區。 請勿只將寶貴的數據儲存在快取中;請確定您也維護原始資料存放區中的資訊。 這表示如果快取變得無法使用,您可以將遺失數據的機會降到最低。
快取高度動態數據
當您將快速變更的資訊儲存在持續性數據存放區時,可能會對系統造成額外負荷。 例如,請考慮持續報告狀態或某些其他度量的裝置。 如果應用程式選擇不要根據快取的信息幾乎一律過期來快取此數據,則從數據存放區儲存和擷取此資訊時,相同的考慮可能成立。 在儲存和擷取此資料所需的時間中,它可能已變更。
在此情況下,請考慮將動態資訊直接儲存在快取中,而不是在持續性數據存放區中的優點。 如果數據不具關鍵性,且不需要稽核,則偶爾會遺失變更並不重要。
管理快取中的數據到期
在大部分情況下,快取中保存的數據是保留在原始數據存放區中的數據複本。 原始數據存放區中的數據在快取之後可能會變更,導致快取的數據變得過時。 許多快取系統可讓您將快取設定為過期數據,並減少數據可能過期的期間。
當快取的數據過期時,它會從快取中移除,而且應用程式必須從原始數據存放區擷取數據(它可以將新擷取的資訊放回快取中)。 您可以在設定快取時設定預設到期原則。 在許多快取服務中,您也可以在以程序設計方式將個別物件儲存在快取中時,規定個別物件的到期期間。 某些快取可讓您將到期期間指定為絕對值,或做為滑動值,如果專案未在指定時間記憶體取,就會從快取中移除。 此設定會覆寫所有快取範圍的到期原則,但僅適用於指定的物件。
注意
請考慮快取的到期期間及其包含的物件。 如果您讓它太短,物件將會太快過期,而且會降低使用快取的優點。 如果您讓期間過長,則可能會使數據變得過時。
如果允許數據長時間保留居民,快取也可能填滿。 在此情況下,任何將新專案新增至快取的要求都可能會導致某些專案在稱為收回的進程中強制移除。 快取服務通常會以最近使用最少的 (LRU) 為基礎收回數據,但您通常可以覆寫此原則,並防止專案被收回。 不過,如果您採用此方法,則有可能超過快取中可用的記憶體。 嘗試將專案新增至快取的應用程式將會失敗,但發生例外狀況。
某些快取實作可能會提供額外的收回原則。 收回原則有數種類型。 包括:
- 最近使用的原則(預期數據不會再次需要)。
- 先出先出的原則(最舊的數據會先收回)。
- 以觸發事件為基礎的明確移除原則(例如正在修改的數據)。
使用戶端快取中的數據失效
在用戶端快取中保存的數據通常被視為在提供數據給客戶端的服務主持之外。 服務無法直接強制用戶端從用戶端快取新增或移除資訊。
這表示用戶端可以使用設定不佳的快取,繼續使用過時的資訊。 例如,如果快取的到期原則未正確實作,當原始數據源中的資訊變更時,用戶端可能會使用本機快取的過期資訊。
如果您建置可透過 HTTP 連線提供資料的 Web 應用程式,您可以隱含地強制 Web 用戶端(例如瀏覽器或 Web Proxy)擷取最新的資訊。 如果資源是由該資源的 URI 變更所更新,您可以執行此動作。 Web 用戶端通常會使用資源的 URI 作為用戶端快取中的金鑰,因此如果 URI 變更,Web 用戶端會忽略任何先前快取的資源版本,並改為擷取新版本。
管理快取中的並行存取
快取通常設計成由應用程式的多個實例共用。 每個應用程式實例都可以讀取和修改快取中的數據。 因此,任何共用數據存放區所發生的相同並行問題也會套用至快取。 在應用程式需要修改快取中保存的數據的情況下,您可能需要確保應用程式某個實例所做的更新不會覆寫另一個實例所做的變更。
視數據的性質和衝突的可能性而定,您可以採用下列兩種方法之一來並行存取:
- 開放式。 在更新數據之前,應用程式會檢查快取中的數據自擷取後是否已變更。 如果數據仍然相同,可以進行變更。 否則,應用程式必須決定是否要更新它。 (驅動此決定的商業規則將是應用程式特定的。此方法適用於更新不常發生的情況,或不太可能發生衝突的情況。
- 悲觀。 擷取數據時,應用程式會將它鎖定在快取中,以防止另一個實例變更它。 此程式可確保無法發生衝突,但也可以封鎖其他需要處理相同數據的實例。 悲觀並行存取可能會影響解決方案的延展性,而且只建議用於短期作業。 這個方法可能適用於較可能發生衝突的情況,特別是當應用程式更新快取中的多個專案時,而且必須確保這些變更會一致地套用。
實作高可用性和延展性,並改善效能
避免使用快取作為數據的主要存放庫;這是填入快取的來源原始數據存放區角色。 原始數據存放區負責確保數據的持續性。
請小心不要將共用快取服務可用性的重要相依性引入您的解決方案。 如果提供共用快取的服務無法使用,應用程式應該能夠繼續運作。 應用程式不應該在等候快取服務繼續時變得沒有回應或失敗。
因此,應用程式必須準備好偵測快取服務的可用性,並在無法存取快取時回復至原始數據存放區。 斷路器 模式 對於處理此案例很有用。 提供快取的服務可以復原,而且一旦可供使用,快取就可以在從原始數據存放區讀取數據時重新填入快取,並遵循快取保留模式等策略。
不過,如果應用程式暫時無法使用快取時回復至原始數據存放區,系統延展性可能會受到影響。 當數據存放區正在復原時,原始數據存放區可能會被數據要求淹沒,導致逾時和失敗的連線。
請考慮在應用程式的每個實例中實作本機私用快取,以及所有應用程式實例存取的共用快取。 當應用程式擷取專案時,它可以先簽入其本機快取,然後在共用快取中,最後在原始數據存放區中。 如果共用快取無法使用,則可以使用共用快取中的數據,或在資料庫中填入本機快取。
此方法需要謹慎的設定,以防止本機快取在共用快取方面變得太過時。 不過,如果無法連線到共用快取,本機快取會作為緩衝區。 圖 3 顯示此結構。

圖 3:搭配共用快取使用本機私人快取。
為了支援保存相對長期數據的大型快取,某些快取服務會提供高可用性選項,以在快取變成無法使用時實作自動故障轉移。 這種方法通常牽涉到將儲存在主要快取伺服器上的快取數據復寫至次要快取伺服器,並在主伺服器失敗或連線中斷時切換至輔助伺服器。
若要減少與寫入至多個目的地相關聯的延遲,當數據寫入主伺服器上的快取時,可能會以異步方式將復寫至輔助伺服器。 相較於快取的整體大小,此方法會導致某些快取資訊遺失的可能性,但相較於快取的整體大小,此數據的比例應該很小。
如果共用快取很大,則可能有利於跨節點分割快取的數據,以減少爭用的機會並改善延展性。 許多共用快取都支援動態新增(和移除)節點,並在分割區之間重新平衡數據的能力。 這種方法可能牽涉到叢集,其中節點集合會以無縫的單一快取形式呈現給用戶端應用程式。 不過,在內部,數據會分散在節點之間,並遵循預先定義的散發策略,以平均平衡負載。 如需可能分割策略的詳細資訊,請參閱 數據分割指引。
叢集也可以增加快取的可用性。 如果節點失敗,仍可存取其餘的快取。 叢集經常與復寫和故障轉移搭配使用。 每個節點都可以復寫,如果節點失敗,複本可以快速上線。
許多讀取和寫入作業都可能牽涉到單一數據值或物件。 不過,有時可能需要快速儲存或擷取大量數據。 例如,植入快取可能牽涉到將數百或數千個專案寫入快取。 應用程式可能也需要從快取擷取大量的相關專案,做為相同要求的一部分。
許多大型快取會針對這些用途提供批次作業。 這可讓用戶端應用程式將大量專案封裝成單一要求,並減少與執行大量小型要求相關聯的額外負荷。
快取和最終一致性
若要讓快取保留模式運作,填入快取的應用程式實例必須能夠存取最新且一致的數據版本。 在實作最終一致性(例如復寫數據存放區)的系統中,這種情況可能並非如此。
應用程式的一個實例可以修改數據項,並使該專案的快取版本失效。 應用程式的另一個實例可能會嘗試從快取讀取此專案,這會導致快取遺漏,因此它會從數據存放區讀取數據,並將它新增至快取。 不過,如果數據存放區尚未與其他複本完全同步處理,則應用程式實例可以使用舊值讀取並填入快取。
如需處理數據一致性的詳細資訊,請參閱 數據一致性入門。
保護快取的數據
不論您使用的快取服務為何,請考慮如何保護快取中保存的數據免於未經授權的存取。 有兩個主要考慮:
- 快取中數據的隱私權。
- 數據在快取與使用快取的應用程式之間流動時,數據的隱私權。
為了保護快取中的數據,快取服務可能會實作驗證機制,要求應用程式指定下列專案:
- 哪些身分識別可以存取快取中的數據。
- 允許這些身分識別執行的作業(讀取和寫入)。
若要降低與讀取和寫入數據相關聯的額外負荷,在將身分識別授與快取的寫入或讀取許可權之後,該身分識別可以使用快取中的任何數據。
如果您需要限制對快取資料子集的存取,您可以執行下列其中一項動作:
- 將快取分割區分割成分割區(使用不同的快取伺服器),並只授與應允許其使用之分割區的身分識別存取權。
- 使用不同的金鑰來加密每個子集中的數據,並將加密金鑰只提供給應具有每個子集存取權的身分識別。 用戶端應用程式仍可擷取快取中的所有數據,但只能解密具有密鑰的數據。
您也必須在數據進出快取時保護數據。 若要這樣做,您必須視用戶端應用程式用來連線到快取的網路基礎結構所提供的安全性功能而定。 如果快取是使用裝載用戶端應用程式的相同組織內的月臺伺服器來實作,則網路本身的隔離可能不需要您採取其他步驟。 如果快取位於遠端,且需要透過公用網路進行 TCP 或 HTTP 連線(例如因特網),請考慮實作 SSL。
在 Azure 中實作快取的考慮
Azure Cache for Redis 是 開放原始碼 Redis 快取的實作,可在 Azure 數據中心以服務的形式執行。 它提供可從任何 Azure 應用程式存取的快取服務,不論應用程式是實作為雲端服務、網站或 Azure 虛擬機內部。 具有適當存取金鑰的用戶端應用程式可以共用快取。
Azure Cache for Redis 是一種高效能快取解決方案,可提供可用性、延展性和安全性。 它通常會以分散在一或多部專用機器上的服務的形式執行。 它會嘗試將盡可能多的資訊儲存在記憶體中,以確保快速存取。 此架構旨在藉由減少執行緩慢 I/O 作業的需求,來提供低延遲和高輸送量。
Azure Cache for Redis 與用戶端應用程式所使用的許多各種 API 相容。 如果您有現有的應用程式已使用在內部部署執行的 Azure Cache for Redis,Azure Cache for Redis 會提供快速移轉路徑來快取雲端中的快取。
Redis 的功能
Redis 不僅僅是簡單的快取伺服器。 它提供分散式記憶體內部資料庫,其中包含支援許多常見案例的廣泛命令集。 本檔稍後會在使用 Redis 快取一節中說明這些內容。 本節摘要說明 Redis 提供的一些重要功能。
Redis 作為記憶體內部資料庫
Redis 同時支援讀取和寫入作業。 在 Redis 中,寫入可以定期儲存在本機快照集檔案或僅附加記錄檔中,以保護系統失敗。 這種情況在很多快取中都不是這種情況,這應該被視為暫時性數據存放區。
所有寫入都是異步的,而且不會封鎖用戶端讀取和寫入數據。 當 Redis 開始執行時,它會從快照集或記錄檔讀取數據,並使用它來建構記憶體內部快取。 如需詳細資訊,請參閱 Redis 網站上的 Redis 持續性 。
注意
Redis 不保證如果發生重大失敗,所有寫入都會儲存,但最糟糕的是,您可能只遺失幾秒的數據。 請記住,快取並非用來做為權威數據源,而應用程式會負責使用快取來確保重要數據已成功儲存至適當的數據存放區。 如需詳細資訊,請參閱另行快 取模式。
Redis 數據類型
Redis 是索引鍵/值存放區,其中值可以包含簡單類型或複雜的數據結構,例如哈希、清單和集合。 它支援這些數據類型的一組不可部分完成作業。 索引鍵可以永久或標記有有限的存留時間,此時索引鍵及其對應的值會自動從快取中移除。 如需 Redis 索引鍵和值的詳細資訊,請流覽 Redis 網站上的 Redis 數據類型和抽象概念簡介頁面。
Redis 複寫和叢集
Redis 支援主要/次級復寫,以協助確保可用性和維護輸送量。 將寫入作業複寫至 Redis 主要節點會複寫到一或多個次級節點。 讀取作業可由主要或任何從屬提供。
如果您有網路分割區,次級可以繼續提供數據,然後在重新建立連線時,以透明方式與主要複本重新同步處理。 如需進一步的詳細數據,請流覽 Redis 網站上的復寫頁面。
Redis 也提供叢集,可讓您以透明方式將數據分割成跨伺服器分區並分散負載。 這項功能可改善延展性,因為可以新增新的 Redis 伺服器,而且隨著快取大小增加而重新分割的數據。
此外,叢集中的每個伺服器都可以使用主要/次級複寫來複寫。 這可確保叢集中每個節點的可用性。 如需叢集和分區化的詳細資訊,請流覽 Redis 網站上的 Redis 叢集教學課程頁面 。
Redis 記憶體使用量
Redis 快取的大小有限,取決於主計算機上可用的資源。 當您設定 Redis 伺服器時,您可以指定其可使用的最大記憶體數量。 您也可以在 Redis 快取中設定金鑰,使其有到期時間,之後它會自動從快取中移除。 這項功能有助於防止記憶體內部快取填滿舊或過時的數據。
當記憶體填滿時,Redis 可以遵循一些原則來自動收回索引鍵及其值。 默認值為 LRU(最近最少使用),但您也可以選取其他原則,例如隨機收回密鑰或完全關閉收回密鑰(在此情況下,如果快取已滿,則嘗試將專案新增至快取失敗)。 使用 Redis 作為 LRU 快取的頁面會提供詳細資訊。
Redis 交易和批次
Redis 可讓用戶端應用程式提交一系列作業,以不可部分完成的交易在快取中讀取和寫入數據。 交易中的所有命令都保證會循序執行,而其他並行用戶端所發出的命令之間不會交織在一起。
不過,這些不是真正的交易,因為關係資料庫會執行它們。 事務處理包含兩個階段:第一個階段是在命令排入佇列時,而第二個階段是命令執行時。 在命令佇列階段期間,由用戶端提交組成交易的命令。 如果此時發生某種錯誤(例如語法錯誤或參數數目錯誤),則 Redis 會拒絕處理整個交易並捨棄它。
在執行階段期間,Redis 會依序執行每個佇列命令。 如果命令在此階段失敗,Redis 會繼續進行下一個已排入佇列的命令,而且不會回復任何已執行之命令的效果。 這種簡化的交易形式有助於維護效能,並避免爭用所造成的效能問題。
Redis 會實作開放式鎖定形式,以協助維護一致性。 如需使用 Redis 交易和鎖定的詳細資訊,請流覽 Redis 網站上的 [交易] 頁面 。
Redis 也支援要求的非交易批處理。 用戶端用來將命令傳送至 Redis 伺服器的 Redis 通訊協定可讓用戶端在相同要求中傳送一系列作業。 這有助於減少網路上的封包分散。 處理批次時,會執行每個命令。 如果其中任何一個命令的格式不正確,則會遭到拒絕(交易不會發生此情況),但會執行其餘命令。 也不能保證批次中命令的處理順序。
Redis 安全性
Redis 純粹著重於提供數據的快速存取,且設計目的是在只能由信任用戶端存取的受信任環境中執行。 Redis 支援以密碼驗證為基礎的有限安全性模型。 (雖然不建議這麼做,但可以完全移除驗證。
所有已驗證的用戶端都會共用相同的全域密碼,而且可以存取相同的資源。 如果您需要更全面的登入安全性,您必須在 Redis 伺服器前面實作自己的安全性層,而且所有用戶端要求都應該通過這個額外的層。 Redis 不應該直接公開給未受信任的或未經驗證的用戶端。
您可以藉由停用命令或重新命名命令來限制對命令的存取權(以及只提供具有新名稱的特殊許可權用戶端)。
Redis 不會直接支援任何形式的數據加密,因此所有編碼都必須由用戶端應用程式執行。 此外,Redis 不提供任何形式的傳輸安全性。 如果您需要保護數據在網路上流動時,建議您實作 SSL Proxy。
如需詳細資訊,請流覽 Redis 網站上的 Redis 安全性 頁面。
注意
Azure Cache for Redis 提供用戶端連線的專屬安全性層。 基礎 Redis 伺服器不會公開至公用網路。
Azure Redis 快取
Azure Cache for Redis 可讓您存取裝載於 Azure 資料中心的 Redis 伺服器。 它可作為提供訪問控制和安全性的外牆。 您可以使用 Azure 入口網站 來布建快取。
入口網站提供一些預先定義的組態。 這些範圍從以專用服務的形式執行的 53 GB 快取,支援 SSL 通訊(適用於隱私權)和具有服務等級協定 (SLA) 99.9% 可用性的主要/次級復寫,到 250 MB 快取,而不需要復寫(無可用性保證)在共用硬體上執行。
使用 Azure 入口網站,您也可以設定快取的收回原則,以及將使用者新增至提供的角色來控制快取的存取。 這些角色會定義成員可執行的作業,包括擁有者、參與者和讀者。 例如,擁有者角色的成員可以完全控制快取(包括安全性)及其內容,參與者角色的成員可以在快取中讀取和寫入資訊,而讀取者角色的成員只能從快取擷取數據。
大部分的系統管理工作都是透過 Azure 入口網站 來執行。 基於這個理由,許多在標準版本的 Redis 中可用的系統管理命令都無法使用,包括能夠以程式設計方式修改設定、關閉 Redis 伺服器、設定其他次級,或強制將數據儲存至磁碟。
Azure 入口網站 包含方便的圖形顯示,可讓您監視快取的效能。 例如,您可以檢視所要建立的連接數目、正在執行的要求數目、讀取和寫入的磁碟區,以及快取叫用次數與快取遺漏數目。 使用這項資訊,您可以判斷快取的有效性,如有必要,請切換至不同的組態或變更收回原則。
此外,如果一或多個重要計量落在預期的範圍內,您可以建立警示,以將電子郵件訊息傳送給系統管理員。 例如,如果快取遺漏數目在過去一小時內超過指定的值,您可能會想要向系統管理員發出警示,因為這表示快取可能太小,或數據可能太快被收回。
您也可以監視快取的CPU、記憶體和網路使用量。
如需示範如何建立和設定 Azure Cache for Redis 的進一步資訊和範例,請流覽 Azure 部落格上關於 Azure Cache for Redis 的頁面。
快取工作階段狀態和 HTML 輸出
如果您建置 ASP.NET 使用 Azure Web 角色執行的 Web 應用程式,您可以在 Azure Cache for Redis 中儲存工作階段狀態資訊和 HTML 輸出。 Azure Cache for Redis 的工作階段狀態提供者可讓您在 ASP.NET Web 應用程式的不同實例之間共用會話資訊,而且在用戶端-伺服器親和性無法使用且快取記憶體中的會話數據不適合的 Web 伺服器陣列狀況中非常有用。
搭配 Azure Cache for Redis 使用會話狀態提供者可提供數個優點,包括:
- 與大量 ASP.NET Web 應用程式的實例共用會話狀態。
- 提供改善的延展性。
- 針對多個讀取器和單一寫入器,支援對相同會話狀態數據的受控制並行存取。
- 使用壓縮來節省記憶體並改善網路效能。
如需詳細資訊,請參閱 ASP.NET Azure Cache for Redis 的會話狀態提供者。
注意
請勿將 Azure Cache for Redis 的工作階段狀態提供者與在 Azure 環境外部執行的 ASP.NET 應用程式搭配使用。 從 Azure 外部存取快取的延遲,可以消除快取數據的效能優點。
同樣地,Azure Cache for Redis 的輸出快取提供者可讓您儲存 ASP.NET Web 應用程式所產生的 HTTP 回應。 使用輸出快取提供者搭配 Azure Cache for Redis 可以改善呈現複雜 HTML 輸出的應用程式回應時間。 產生類似回應的應用程式實例可以使用快取中的共享輸出片段,而不是重新產生此 HTML 輸出。 如需詳細資訊,請參閱 ASP.NET Azure Cache for Redis 的輸出快取提供者。
建置自定義 Redis 快取
Azure Cache for Redis 可作為基礎 Redis 伺服器的外觀。 如果您需要 Azure Redis 快取未涵蓋的進階設定(例如快取大於 53 GB),您可以使用 Azure 虛擬機器 來建置及裝載自己的 Redis 伺服器。
這是一個潛在的複雜程序,因為如果您想要實作複寫,您可能需要建立數個 VM 作為主要和次級節點。 此外,如果您想要建立叢集,則需要多個主要和次級伺服器。 提供高度可用性和延展性的最小叢集復寫拓撲,至少包含六部以三對主要/次級伺服器組織的 VM(叢集必須包含至少三個主要節點)。
每個主要/次級配對都應該放在一起,以將延遲降到最低。 不過,如果您想要找出最可能使用它的應用程式附近的快取數據,每個配對可以在位於不同區域的不同 Azure 資料中心執行。 如需建置和設定以 Azure VM 身分執行的 Redis 節點範例,請參閱 在 Azure 中的 CentOS Linux VM 上執行 Redis。
注意
如果您以此方式實作自己的 Redis 快取,您必須負責監視、管理和保護服務。
分割 Redis 快取
分割快取牽涉到跨多部計算機分割快取。 此結構提供使用單一快取伺服器數個優點,包括:
- 建立比儲存在單一伺服器上大得多的快取。
- 將數據分散到伺服器,以改善可用性。 如果一部伺服器失敗或無法存取,則保存的數據無法使用,但仍然可以存取其餘伺服器上的資料。 對於快取而言,這並不重要,因為快取的數據只是資料庫中所保存數據的暫時性複本。 無法存取之伺服器上的快取數據可以改為在不同的伺服器上快取。
- 將負載分散到伺服器,進而改善效能和延展性。
- 將數據定位在接近存取數據的使用者附近,進而降低延遲。
對於快取,最常見的分割形式是分區化。 在此策略中,每個分割區(或分區)都是其本身的 Redis 快取。 數據會使用分區化邏輯導向至特定分割區,其可以使用各種不同的方法來散發數據。 分區 化模式 提供有關實作分區化的詳細資訊。
若要在 Redis 快取中實作數據分割,您可以採用下列其中一種方法:
- 伺服器端查詢路由。 在這項技術中,用戶端應用程式會將要求傳送至組成快取的任何 Redis 伺服器(可能是最接近的伺服器)。 每個 Redis 伺服器都會儲存描述其保留之分割區的元數據,也包含其他伺服器上哪些分割區的相關信息。 Redis 伺服器會檢查用戶端要求。 如果可以在本機解析,則會執行要求的作業。 否則,它會將要求轉送至適當的伺服器。 此模型是由 Redis 叢集實作,並在 Redis 網站上的 Redis 叢集教學課程頁面上更詳細地說明。 Redis 叢集對用戶端應用程式而言是透明的,其他 Redis 伺服器可以新增至叢集(以及重新分割的數據),而不需要重新設定用戶端。
- 用戶端數據分割。 在此模型中,用戶端應用程式包含邏輯(可能以連結庫的形式)將要求路由傳送至適當的 Redis 伺服器。 此方法可與 Azure Cache for Redis 搭配使用。 建立多個 Azure Cache for Redis (每個數據分割都有一個),並實作客戶端邏輯,以將要求路由傳送至正確的快取。 如果分割配置變更(例如,如果建立其他 Azure Cache for Redis,則可能需要重新設定用戶端應用程式。
- Proxy 輔助的數據分割。 在此配置中,用戶端應用程式會將要求傳送至中繼 Proxy 服務,以了解數據分割的方式,然後將要求路由傳送至適當的 Redis 伺服器。 此方法也可以與 Azure Cache for Redis 搭配使用;Proxy 服務可以實作為 Azure 雲端服務。 此方法需要額外的複雜度才能實作服務,而且要求可能需要比使用用戶端數據分割更久才能執行。
數據分割頁面 :如何在 Redis 網站上的多個 Redis 實例 之間分割數據,提供有關使用 Redis 實作數據分割的進一步資訊。
實作 Redis 快取用戶端應用程式
Redis 支援以許多程式設計語言撰寫的用戶端應用程式。 如果您使用 .NET Framework 建置新的應用程式,建議您使用 StackExchange.Redis 用戶端連結庫。 此連結庫提供 .NET Framework 物件模型,以抽象化連線到 Redis 伺服器、傳送命令及接收回應的詳細數據。 它可在Visual Studio中以 NuGet 套件的形式提供。 您可以使用這個相同的連結庫來連線到 Azure Cache for Redis,或裝載在 VM 上的自定義 Redis 快取。
若要連線到 Redis 伺服器,請使用 類別的ConnectionMultiplexer靜態Connect方法。 這個方法所建立的連接是設計成在用戶端應用程式的整個存留期內使用,而且多個並行線程可以使用相同的連線。 每次執行 Redis 作業時,請勿重新連線並中斷連線,因為這可能會降低效能。
您可以指定連線參數,例如 Redis 主機的地址和密碼。 如果您使用 Azure Cache for Redis,則密碼是使用 Azure 入口網站 為 Azure Cache for Redis 產生的主要或次要密鑰。
連線到 Redis 伺服器之後,您可以在作為快取的 Redis 資料庫上取得句柄。 Redis 連線提供 GetDatabase 執行這項操作的方法。 接著,您可以使用 和 StringSet 方法,從快取擷取專案,並將數據儲存在快取StringGet中。 這些方法預期索引鍵為參數,並傳回快取中具有相符值 (StringGet) 的專案,或使用這個索引鍵將專案加入快取中。StringSet
根據 Redis 伺服器的位置,許多作業可能會在要求傳輸至伺服器並傳回回應給客戶端時產生一些延遲。 StackExchange 連結庫提供其公開的許多方法的異步版本,以協助用戶端應用程式保持回應。 這些方法支援 .NET Framework 中以工作為基礎的異步模式 。
下列代碼段顯示名為 RetrieveItem的方法。 它說明以 Redis 和 StackExchange 連結庫為基礎的快取暫存模式實作。 方法會採用字串索引鍵值,並嘗試呼叫 StringGetAsync 方法從 Redis 快取擷取對應的專案(異步版本的 StringGet)。
如果找不到專案,則會使用 GetItemFromDataSourceAsync 方法從基礎數據源擷取專案(這是本機方法,而不是 StackExchange 連結庫的一部分)。 接著會使用 StringSetAsync 方法將它新增至快取,以便下次更快速地擷取它。
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringGet和 StringSet 方法不限於擷取或儲存字串值。 它們可以接受串行化為位元組數位的任何專案。 如果您需要儲存 .NET 物件,您可以將它串行化為位元組數據流,並使用 StringSet 方法將它寫入快取。
同樣地,您可以使用 方法從快取 StringGet 讀取物件,並將它還原串行化為 .NET 物件。 下列程式代碼顯示一組 IDatabase 介面的擴充方法( GetDatabase Redis 連接的方法會 IDatabase 傳回 物件),以及一些使用這些方法將物件讀取和寫入 BlogPost 快取的範例程式代碼:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
下列程式代碼說明名為 RetrieveBlogPost 的方法,這個方法會使用這些擴充方法來讀取和寫入可串行化的物件,並遵循快取保留模式將可 BlogPost 串行化物件寫入快取:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
如果用戶端應用程式傳送多個異步要求,Redis 支援命令管線處理。 Redis 可以使用相同的連線來多任務處理要求,而不是以嚴格的順序接收和回應命令。
這種方法有助於降低延遲,方法是更有效率地使用網路。 下列代碼段顯示可同時擷取兩個客戶詳細數據的範例。 程序代碼會提交兩個要求,然後在等候接收結果之前執行一些其他處理(未顯示)。 快 Wait 取物件的 方法類似於 .NET Framework Task.Wait 方法:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
如需撰寫可使用 Azure Cache for Redis 之用戶端應用程式的其他資訊,請參閱 Azure Cache for Redis 檔。 如需詳細資訊, 請參閱 StackExchange.Redis。
相同網站上的管線和多任務器頁面提供有關異步操作和管線搭配 Redis 和 StackExchange 連結庫的詳細資訊。
使用 Redis 快取
Redis 用於快取考慮的最簡單用法是索引鍵/值組,其中值是任意長度的未解譯字串,可包含任何二進位數據。 (基本上是可以視為字串的位元組陣列)。 本文稍早實作 Redis 快取用戶端應用程式一節說明此案例。
請注意,索引鍵也包含未解譯的數據,因此您可以使用任何二進位資訊作為索引鍵。 不過,索引鍵越長,儲存所需的空間越多,執行查閱作業所需的時間就越長。 為了方便使用和維護,請仔細設計您的密鑰空間,並使用有意義的(但不是詳細資訊)金鑰。
例如,使用結構化密鑰,例如 「customer:100」 來代表標識碼為 100 的客戶密鑰,而不只是 「100」。 此配置可讓您輕鬆地區分儲存不同數據類型的值。 例如,您也可以使用金鑰 「orders:100」 來代表識別碼為 100 之訂單的索引鍵。
除了一維二進位字串之外,Redis 索引鍵/值組中的值也可以保存更多結構化資訊,包括清單、集合(已排序和未排序),以及哈希。 Redis 提供可操作這些類型的完整命令集,而且許多這些命令都可透過 StackExchange 等用戶端連結庫提供給 .NET Framework 應用程式。 Redis 網站上的 Redis 數據類型和抽象概觀頁面提供更詳細的這些類型概觀,以及可用來操作它們的命令。
本節摘要說明這些數據類型和命令的一些常見使用案例。
執行不可部分完成和批次作業
Redis 支援字串值的一系列不可部分完成的 get-and-set 作業。 這些作業會移除使用個別 GET 和 SET 命令時可能發生的競爭危害。 可用的作業包括:
INCR、INCRBY、DECR和DECRBY,在整數數值數據值上執行不可部分完成的遞增和遞減作業。 StackExchange 連結庫提供 和IDatabase.StringDecrementAsync方法的多IDatabase.StringIncrementAsync載版本來執行這些作業,並傳回儲存在快取中的結果值。 下列代碼段說明如何使用這些方法:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET,它會擷取與索引鍵相關聯的值,並將它變更為新的值。 StackExchange 連結庫可透過IDatabase.StringGetSetAsync方法提供這項作業。 下列代碼段顯示這個方法的範例。 此程式代碼會從上一個範例傳回與索引鍵 「data:counter」 相關聯的目前值。 然後,它會將此機碼的值重設為零,全部都重設為相同作業的一部分:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGET和MSET,可以傳回或變更一組字串值做為單一作業。IDatabase.StringGetAsync和IDatabase.StringSetAsync方法會多載以支援這項功能,如下列範例所示:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
您也可以將多個作業合併成單一 Redis 交易,如本文稍早的 Redis 交易和批次一節所述。 StackExchange 連結庫支援透過 ITransaction 介面的交易。
您可以使用 方法建立 ITransaction 物件 IDatabase.CreateTransaction 。 您可以使用物件所提供的 ITransaction 方法來叫用命令至交易。
介面 ITransaction 提供一組方法的存取權,與介面所 IDatabase 存取的方法類似,但所有方法都是異步的。 這表示只有在叫用 方法時 ITransaction.Execute ,才會執行它們。 方法所 ITransaction.Execute 傳回的值表示交易是否成功建立 (true) 或是否失敗 (false)。
下列代碼段顯示一個範例,會將兩個計數器遞增和遞減為相同交易的一部分:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
請記住,Redis 交易與關係資料庫中的交易不同。 方法 Execute 只會將組成要執行之交易的所有命令排入佇列,如果其中任一個命令格式不正確,則會停止交易。 如果所有命令都已成功排入佇列,則每個命令都會以異步方式執行。
如果有任何命令失敗,其他命令仍會繼續處理。 如果您需要確認命令已順利完成,您必須使用 對應工作的 Result 屬性來擷取命令的結果,如上述範例所示。 讀取 Result 屬性會封鎖呼叫線程,直到工作完成為止。
如需詳細資訊,請參閱 Redis 中的交易。
執行批次作業時,您可以使用 IBatch StackExchange 連結庫的介面。 這個介面提供一組類似 介面所 IDatabase 存取的方法存取權,但所有方法都是異步的。
您可以使用 方法建立 IBatch 對象 IDatabase.CreateBatch ,然後使用 方法執行批次 IBatch.Execute ,如下列範例所示。 此程式代碼只會設定字串值、遞增和遞減上一個範例中使用的相同計數器,並顯示結果:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
請務必瞭解,不同於交易,如果批次中的命令因為格式不正確而失敗,其他命令仍可能會執行。 方法 IBatch.Execute 不會傳回任何成功或失敗的指示。
執行引發並忘記快取作業
Redis 支援使用命令旗標引發和忘記作業。 在此情況下,用戶端只會起始作業,但對結果沒有興趣,而且不會等待命令完成。 下列範例示範如何以引發和忘記作業的方式執行 INCR 命令:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
指定自動過期的金鑰
當您將項目儲存在 Redis 快取中時,您可以指定逾時,之後項目會自動從快取中移除。 您也可以使用 TTL 命令,查詢金鑰在到期之前有多少時間。 使用方法,StackExchange 應用程式 IDatabase.KeyTimeToLive 可以使用此命令。
下列代碼段示範如何在金鑰上設定 20 秒的到期時間,並查詢金鑰的剩餘存留期:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
您也可以使用 STACKExchange 連結庫中可用的 EXPIRE 命令,將到期時間設定為特定的日期和時間,做為 KeyExpireAsync 方法:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
提示
您可以使用 DEL 命令,透過 StackExchange 連結庫做為 IDatabase.KeyDeleteAsync 方法,手動從快取移除專案。
使用標記來交叉關聯快取的專案
Redis 集合是多個共享單一索引鍵的專案集合。 您可以使用 SADD 命令來建立集合。 您可以使用 SMEMBERS 命令來擷取集合中的專案。 StackExchange 連結庫使用 IDatabase.SetAddAsync 方法實作 SADD 命令,並使用 方法實作 SMEMBERS 命令 IDatabase.SetMembersAsync 。
您也可以使用 SDIFF (set difference)、SINTER(set 交集)和 SUNION (set union) 命令,結合現有的集合來建立新的集合。 StackExchange 連結庫會在 方法中 IDatabase.SetCombineAsync 統一這些作業。 這個方法的第一個參數會指定要執行的設定作業。
下列代碼段示範集合如何有助於快速儲存和擷取相關專案的集合。 此程式代碼會使用 BlogPost 本文稍早實作 Redis 快取用戶端應用程式一節中所述的類型。
BlogPost物件包含四個字段:標識符、標題、排名分數和標記集合。 下列第一個代碼段顯示用於填入物件 C# 清單的 BlogPost 範例資料:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
您可以將每個 BlogPost 對象的標記儲存為 Redis 快取中的集合,並將每個集合與的 BlogPost識別碼產生關聯。 這可讓應用程式快速尋找屬於特定部落格文章的所有標籤。 若要以相反的方向搜尋並尋找共用特定標籤的所有部落格文章,您可以建立另一個集合來保存參考索引鍵中標籤標識碼的部落格文章:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
這些結構可讓您非常有效率地執行許多常見的查詢。 例如,您可以尋找並顯示部落格文章 1 的所有標籤,如下所示:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
您可以藉由執行集合交集作業,找到部落格文章 1 和部落格文章 2 通用的所有標籤,如下所示:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
您可以找到包含特定標籤的所有部落格文章:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
尋找最近存取的專案
許多應用程式所需的常見工作是尋找最近存取的專案。 例如,部落格網站可能會想要顯示最近閱讀部落格文章的相關信息。
您可以使用 Redis 清單來實作這項功能。 Redis 清單包含多個共用相同索引鍵的專案。 此清單會做為雙端佇列。 您可以使用 LPUSH (左推) 和 RPUSH (右推) 命令,將專案推送至清單的任一端。 您可以使用 LPOP 和 RPOP 命令,從清單的任一端擷取專案。 您也可以使用 LRANGE 和 RRANGE 命令傳回一組元素。
下列代碼段示範如何使用 StackExchange 連結庫來執行這些作業。 此程式代碼會使用 BlogPost 先前範例中的類型。 當使用者讀取部落格文章時,方法 IDatabase.ListLeftPushAsync 會將部落格文章的標題推送至 Redis 快取中與密鑰 “blog:recent_posts” 相關聯的清單。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
隨著更多部落格文章的閱讀,其標題會推送至相同的清單。 清單會依已加入標題的順序排序。 最近閱讀的部落格文章位於清單的左端。 (如果多次閱讀相同的部落格文章,它就會在清單中有多個專案。
您可以使用 方法來顯示最近閱讀文章 IDatabase.ListRange 的標題。 這個方法會採用包含清單、起點和結束點的索引鍵。 下列程式代碼會擷取清單最左邊 10 篇部落格文章 (專案從 0 到 9) 的標題:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
請注意, ListRangeAsync 方法不會從清單中移除專案。 若要這樣做,您可以使用 IDatabase.ListLeftPopAsync 和 IDatabase.ListRightPopAsync 方法。
若要防止清單無限期成長,您可以修剪清單來定期擷取專案。 下列代碼段示範如何從清單中移除五個最左邊的專案:
await cache.ListTrimAsync(redisKey, 0, 5);
實作排行榜
根據預設,集合中的專案不會以任何特定順序保留。 您可以使用 ZADD 命令建立已排序的集合( IDatabase.SortedSetAdd StackExchange 連結庫中的 方法)。 專案是使用稱為分數的數值來排序,其會以命令的參數的形式提供。
下列代碼段會將部落格文章的標題新增至已排序的清單。 在此範例中,每個部落格文章也有一個分數位段,其中包含部落格文章的排名。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
您可以使用 方法,以遞增分數順序 IDatabase.SortedSetRangeByRankWithScores 擷取部落格文章標題和分數:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
注意
StackExchange 連結庫也提供 IDatabase.SortedSetRangeByRankAsync 方法,此方法會依分數順序傳回數據,但不會傳回分數。
您也可以依分數遞減順序擷取專案,並藉由提供其他參數給 IDatabase.SortedSetRangeByRankWithScoresAsync 方法來限制傳回的項目數目。 下一個範例會顯示前 10 個排名前 10 個部落格文章的標題和分數:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
下一個範例會 IDatabase.SortedSetRangeByScoreWithScoresAsync 使用 方法來限制傳回至指定分數範圍內的專案:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
使用通道的訊息
除了做為數據快取之外,Redis 伺服器還透過高效能發行者/訂閱者機制提供傳訊。 用戶端應用程式可以訂閱通道,而其他應用程式或服務可以將訊息發佈至通道。 訂閱應用程式接著會收到這些訊息,並可以處理這些訊息。
Redis 提供 SUBSCRIBE 命令,讓用戶端應用程式用來訂閱通道。 此命令預期應用程式將接受訊息的一或多個通道名稱。 StackExchange 連結庫包含 ISubscription 介面,可讓 .NET Framework 應用程式訂閱及發佈至通道。
ISubscription您可以使用與 Redis 伺服器連線的方法建立 物件GetSubscriber。 然後使用這個物件的 方法,接聽通道 SubscribeAsync 上的訊息。 下列程式代碼範例示範如何訂閱名為 “messages:blogPosts” 的通道:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
方法的第一個參數 Subscribe 是通道的名稱。 此名稱遵循快取中索引鍵所使用的相同慣例。 此名稱可以包含任何二進位數據,但建議您使用相對簡短且有意義的字元串,以協助確保良好的效能和可維護性。
另請注意,通道所使用的命名空間與索引鍵所使用的命名空間不同。 這表示您可以有具有相同名稱的通道和金鑰,不過這可能會讓您的應用程式程式代碼更難維護。
第二個參數是 Action 委派。 每當通道上出現新訊息時,此委派就會以異步方式執行。 此範例只會在控制台上顯示訊息(訊息將包含部落格文章的標題)。
若要發佈至通道,應用程式可以使用 Redis PUBLISH 命令。 StackExchange 連結庫提供 IServer.PublishAsync 執行這項作業的方法。 下一個代碼段示範如何將訊息發佈至 「messages:blogPosts」 通道:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
您應該瞭解發佈/訂閱機制的幾點:
- 多個訂閱者可以訂閱相同的通道,而且它們都會接收發佈至該通道的訊息。
- 訂閱者只會接收訂閱之後已發佈的訊息。 通道不會緩衝處理,一旦發佈訊息之後,Redis 基礎結構會將訊息推送至每個訂閱者,然後將其移除。
- 根據預設,訂閱者會依傳送的順序接收訊息。 在具有大量訊息和許多訂閱者和發行者的高度主動系統中,保證訊息的循序傳遞可能會降低系統的效能。 如果每個訊息都獨立且順序不重要,您可以啟用 Redis 系統的並行處理,這有助於改善回應性。 您可以在 StackExchange 用戶端中達到此目的,方法是將訂閱者所使用的連線 PreserveAsyncOrder 設定為 false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
串行化考慮
當您選擇串行化格式時,請考慮效能、互操作性、版本設定、與現有系統的相容性、數據壓縮和記憶體額外負荷之間的取捨。 當您評估效能時,請記住基準檢驗高度相依於內容。 它們可能不會反映您的實際工作負載,而且可能不會考慮較新的連結庫或版本。 所有案例都沒有單一「最快」串行化程式。
需要考慮的選項包括:
通訊協定緩衝區 (也稱為 protobuf)是由Google開發的串行化格式,可有效率地串行化結構化數據。 它會使用強型別定義檔案來定義訊息結構。 然後,這些定義檔案會編譯為語言特定的程序代碼,以便串行化和還原串行化訊息。 Protobuf 可以透過現有的 RPC 機制使用,也可以產生 RPC 服務。
Apache Thrift 使用類似的方法,搭配強型別定義檔案和編譯步驟來產生串行化程序代碼和 RPC 服務。
Apache Avro 提供與通訊協定緩衝區和 Thrift 類似的功能,但沒有編譯步驟。 相反地,串行化的數據一律包含描述 結構的架構。
JSON 是使用人類可讀取文字欄位的開放式標準。 它具有廣泛的跨平台支援。 JSON 不會使用訊息架構。 它是以文字為基礎的格式,它不是非常有效率的線路。 不過,在某些情況下,您可能會透過 HTTP 直接將快取專案傳回至用戶端,在此情況下,儲存 JSON 可以節省從另一種格式還原串行化的成本,然後串行化為 JSON。
二進位 JSON (BSON) 是二進位串行化格式,使用類似於 JSON 的結構。 BSON 的設計訴求是輕量型、易於掃描,以及快速串行化和還原串行化,相對於 JSON。 承載的大小與 JSON 相當。 視數據而定,BSON 承載可能小於或大於 JSON 承載。 BSON 有一些 JSON 中無法使用的其他數據類型,尤其是 BinData(適用於位元組數位)和 Date。
MessagePack 是二進位串行化格式,其設計目的是為了透過網路傳輸而壓縮。 沒有訊息架構或訊息類型檢查。
Bond 是一種跨平台架構,可用於使用架構化數據。 它支援跨語言串行化和還原串行化。 此處所列其他系統的顯著差異是繼承、類型別名和泛型的支援。
gRPC 是由Google開發的開放原始碼 RPC 系統。 根據預設,它會使用通訊協定緩衝區作為其定義語言和基礎訊息交換格式。
下一步
- Azure Cache for Redis 文件
- Azure Cache for Redis 常見問題集
- 以工作為基礎的異步模式
- Redis 文件
- StackExchange.Redis
- 數據分割指南
相關資源
當您在應用程式中實作快取時,下列模式也可能與您的案例相關:
另行快取模式:此模式描述如何視需要將數據從數據存放區載入快取。 此模式也有助於維護快取中保留的數據與原始數據存放區中的數據之間的一致性。
分區化模式提供實作水平數據分割的相關信息,以協助改善儲存和存取大量數據時的延展性。