在 Azure SQL Database 中微調應用程式和資料庫的效能
適用於:![]() Azure SQL 資料庫
Azure SQL 資料庫![]() Fabric 中的 SQL 資料庫
Fabric 中的 SQL 資料庫
識別出 Azure SQL 資料庫 或 Fabric SQL 資料庫所遇到的效能問題之後,本文的設計訴求是協助您:
- 微調您的應用程式,並套用一些可以改善效能的最佳做法。
- 變更索引和查詢來微調資料庫,更有效率地使用資料。
本文假設您已經透過 資料庫建議程序建議 和 自動調整建議,如果適用的話。 也假設您已檢閱監視與調整概觀、使用查詢存放區監視效能,以及與針對效能問題進行疑難排解相關的其他文章。 此外,本文還假設您沒有與 CPU 資源使用率相關的效能問題,若要解決此問題,可藉由增加計算大小或提高服務層級來提供更多資源給資料庫。
注意
如需 Azure SQL 受控執行個體中的類似指引,請參閱在 Azure SQL 受控執行個體中微調應用程式和資料庫的效能。
微調應用程式
在傳統的內部部署 SQL Server 中,初始容量規劃的程序通常會和在生產環境中執行應用程式的程序分開。 先購買硬體和產品授權,之後再微調效能。 當您使用 Azure SQL 時,最好是將執行和微調應用程式的程序交織在一起。 透過容量隨選的付費模型,您可以調整應用程式以使用目前需要的最少資源,而不是根據對應用程式未來成長計劃的猜測 (這通常是不正確的) 來過度佈建。
某些客戶可能會選擇不微調應用程式,而改為選擇過度佈建硬體資源。 若您不想在忙碌時期變更關鍵應用程式,這種方法可能很適合。 但是,微調應用程式可以將資源需求最小化,並降低每月計費。
Azure SQL 資料庫應用程式設計中的最佳做法和反模式
雖然 Azure SQL 資料庫服務層級的設計可以改善應用程式的效能穩定性和可預測性,但某些最佳做法可以協助您微調應用程式,以更充分利用某一計算大小的資源。 雖然許多應用程式只藉由切換至較高的計算大小或服務層級就能有顯著的效能提升,但是某些應用程式需要額外的微調才能從較高的服務等級獲益。 為了提高效能,請考慮為具有下列特性的應用程式進行額外的應用程式微調︰
因為「多對話」行為而使效能變差的應用程式
多對話應用程式會產生過多對網路延遲敏感的資料存取作業。 您可能需要修改這類應用程式以減少資料庫的資料存取作業數目。 比方說,您可以藉由使用某些技術來改善應用程式效能,例如批次處理特定查詢或將查詢移至預存程序。 如需詳細資訊,請參閱 批次查詢。
無法由整部單一電腦支援之具有大量工作負載的資料庫
具有次佳查詢的應用程式
未經適當微調的應用程式可能無法受益於較高的計算大小。 這包括缺少 WHERE 子句、具有遺漏的索引或具有過時統計資料的查詢。 這些應用程式會受益於標準查詢效能微調技術。 如需詳細資訊,請參閱遺漏索引和查詢微調和提示。
具有次佳資料存取設計的應用程式
具有內在資料存取並行問題的應用程式,例如死結,可能無法受益於較高的計算大小。 請考慮藉由使用 Azure 快取服務或其他快取技術來快取用戶端的資料,以減少對資料庫的往返作業。 請參閱 應用程式層快取。
若要避免在 Azure SQL Database 中重新發生死結,請參閱 分析並防止 Azure SQL Database 和 Fabric SQL Database 中的死結。
微調資料庫
在本節中,我們會討論一些技術,您可以用這些技術來微調資料庫以獲取應用程式的最佳效能,並且盡可能在最小的計算大小中執行。 其中有些技術符合傳統的 SQL Server 微調最佳做法,但是其他技術則是專屬於 Azure SQL 資料庫。 在某些情況下,您可以檢查資料庫已取用的資源來尋找要進一步微調的區域,並擴充傳統的 SQL Server 技術以使其適用於 Azure SQL 資料庫。
識別並新增遺漏索引
OLTP 資料庫效能中常見的問題與實體資料庫設計相關。 資料庫結構描述的設計和轉移通常不會經過大規模測試 (無論是在負載或資料數量)。 不幸的是,查詢計劃的效能可能只有小規模可以接受,但是在面臨實際執行等級的資料數量時會大幅降低。 此問題最常見的來源是缺少適當的索引來滿足篩選或查詢中的其他限制。 遺漏的索引通常會在索引搜尋可以滿足時,以資料表掃描的形式呈現。
在此範例中,選取的查詢計劃會在搜尋即可滿足需要時使用掃描︰
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
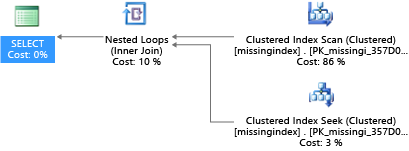
Azure SQL 資料庫可協助您尋找並修正常見的遺漏索引情況。 Azure SQL 資料庫內建的 DMV 會查看查詢編譯,其中的索引會大幅減少執行查詢的估計成本。 執行查詢期間,資料庫引擎會追蹤每個查詢計劃的執行頻率,並追蹤執行查詢計劃和其中存在該索引的假設查詢計劃之間的預估落差。 您可以使用這些 DMV 快速推測哪些實體資料庫設計變更可能會改善資料庫和其實際工作負載的整體工作負載成本。
您可以使用下列查詢來評估潛在的遺漏索引︰
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
在此範例中,查詢導致了這項建議︰
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
在其建立之後,同一個 SELECT 陳述式會挑選不同的計劃,其使用搜尋而不是掃描,然後更有效率地執行計劃:
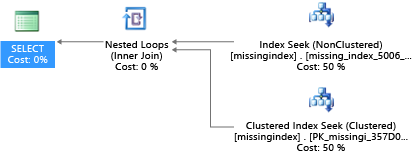
重要的觀念是共用商品系統的 IO 容量會比專用伺服器電腦的容量受到更多限制。 重點在於要最小化不必要的 IO,才能在服務層級中,於每個計算大小的資源內充分利用此系統。 適當的實體資料庫設計選項可以大幅改善個別查詢的延遲、改善每個縮放單位中可處理的並行要求輸送量,並最小化滿足查詢所需的成本。
如需使用遺漏索引要求調整索引的詳細資訊,請參閱使用遺漏索引建議調整非叢集索引。
查詢微調和提示
Azure SQL 資料庫內的查詢最佳化工具類似於傳統的 SQL Server 查詢最佳化工具。 微調查詢和了解查詢最佳化工具之推論模型限制的大多數最佳做法也適用於 Azure SQL 資料庫。 如果您微調 Azure SQL 資料庫中的查詢,您可以因為減少彙總資源需求而獲得額外好處。 您的應用程式能夠以低於未經調整之查詢的成本執行,因為它可以在較低的計算大小中執行。
SQL Server 中常見並且也適用於 Azure SQL 資料庫的範例是查詢最佳化工具如何「探查」參數。 在編譯期間,查詢最佳化工具會評估參數值以判斷該值是否可以產生較佳的查詢計劃。 雖然這個策略產生的查詢計劃通常在速度上明顯優於不知道參數值就編譯的計劃,但是此策略目前在 Azure SQL 資料庫中的運作狀況並不完美。 (自 SQL Server 2022 引進的名為參數敏感度計劃最佳化的智慧型查詢效能功能,可解決參數化查詢的單一快取計劃對於所有可能的連入參數值而言不是最佳的案例。目前,Azure SQL 資料庫中無法使用參數敏感度計劃最佳化。)
資料庫引擎支援查詢提示 (指示詞),因此您可以更刻意地指定意圖及覆寫參數探查的預設行為。 當特定工作負載的預設行為不完善時,您可以選擇使用提示。
下一個範例會示範查詢處理器如何產生對效能和資源需求都不盡理想的計劃。 此範例也會示範如果您使用查詢提示,則可以降低資料庫的查詢執行時間和資源需求:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
設定程式碼會在 t1 資料表中建立扭曲 (或不規則散發) 資料。 最佳的查詢計劃會根據選取的參數而有差異。 不幸的是,計劃快取行為並不一定會根據最常見的參數值重新編譯查詢。 因此,即使不同的計劃會是平均來說較好的計劃選項,仍有可能會快取不盡理想的計劃並用於許多值。 然後,查詢計劃會建立兩個完全相同的預存程序,唯一的差異是其中一個有特殊的查詢提示。
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
建議您先等待至少 10 分鐘再開始範例的第 2 部分,這樣一來,所產生之遙測資料的結果才會截然不同。
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
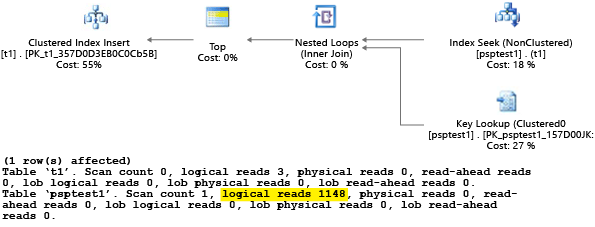
此範例中的每個部分都嘗試執行參數化的 insert 陳述式 1000 次 (以產生足夠的負載來做為測試資料集)。 當它執行預存程序時,查詢處理器會檢查第一次編譯 (參數「探查」) 期間傳遞至程序的參數值。 即使參數值不同,處理器還是會快取產生的計劃並用於稍後的叫用。 最佳的計劃可能不會用於所有情況。 有時候您必須引導最佳化工具挑選計劃,相較於第一次編譯查詢時的特定案例,此計劃較適合平均案例。 在此範例中,初始計劃會產生「掃描」計劃,此計劃會讀取所有資料列來尋找符合參數的每個值:

因為我們以值 1 執行此程序,所以產生的計劃會是值 1 的最佳選擇,但是對資料表中的其他值而言未必是最佳的。 如果您隨機挑選每個計劃,因為該計劃執行得更慢而且使用更多資源,因此結果可能不是您要的。
如果您以 SET STATISTICS IO 設為 ON 來執行測試,此範例會在幕後完成邏輯掃描工作。 您可以看到計劃完成了 1,148 次讀取 (如果平均案例是只傳回一個資料列,則此計劃是沒效率的):

此範例的第二個部分使用查詢提示告訴最佳化工具,在編譯處理程序期間使用特定值。 在此情況下,它會強制查詢處理器忽略傳遞做為參數的值,並改為假設 UNKNOWN。 這表示資料表中具有平均頻率的值 (忽略扭曲)。 產生的計劃是以搜尋為基礎的計劃,平均而言會比此範例第 1 部分的計劃更快速並使用較少資源:
您可以在專屬於 Azure SQL 資料庫的 sys.resource_stats 系統檢視表中看到效果。 執行測試的時間以及資料填入資料表的時間均有延遲。 在此範例中,第 1 部分會在 22:25:00 時間範圍期間執行,而第 2 部分會在 22:35:00 執行。 較早的時間範圍在該時間範圍內使用的資源比較晚的時間範圍還多 (因為計劃效率改善)。
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

注意
雖然此範例中的數量已刻意簡化,次佳參數的影響還是很明顯,尤其是對於較大型的資料庫。 在極端的情況下,快速案例之間的差異可達數秒,而緩慢案例之間的差異可達數小時。
您可以檢查 sys.resource_stats 來判斷測試使用的資源比另一個測試多或少。 在比較資料時,請將測試的時間隔開,讓它們不在 sys.resource_stats 檢視的同一個 5 分鐘時間範圍內。 練習的目標是要最小化使用的資源總量,而不是最小化尖峰資源。 一般而言,最佳化一段延遲的程式碼也可減少資源耗用量。 請確定您對應用程式所做的變更是必要的,而且這些變更不會讓使用應用程式的某人在使用查詢提示時對客戶體驗造成負面影響。
如果工作負載具有一組重複的查詢,擷取並驗證您計劃選項的最適化通常是合理的,因為這會讓主控資料庫所需的資源大小單位降到最低。 在驗證之後,請偶爾重新檢查計劃以確保它們不會降級。 您可以深入了解 查詢提示 (Transact-SQL)。
優化連線和連線共用
為了減少在 Azure SQL Database 中建立頻繁應用程式連線的額外負荷,數據提供者中提供連線共用。 例如,預設會在 ADO.NET 中啟用連線共用。 線上共用可讓應用程式重複使用連線,並將建立新連線的額外負荷降到最低。
線上共用可以改善輸送量、降低延遲,以及增強資料庫工作負載的整體效能。 請記住這些最佳做法:
根據工作負載的並行和延遲需求,設定聯機集區設定,例如連線上限、連線逾時或連線存留期。 如需詳細資訊,請參閱數據提供者檔。
雲端應用程式應該實作 重試邏輯,以正常方式處理暫時性連線失敗。 深入瞭解如何設計用於暫時性錯誤的重試邏輯
。 監視 Azure SQL Database 連線效能和資源使用量,以找出瓶頸,例如過度閑置連線或集區限制不足,並據以調整設定。 請考慮使用 資料庫監看員 或 Azure 監視器。
Azure SQL 資料庫中的大型資料庫架構的最佳做法
在 Azure SQL Database 發行單一資料庫的 超大規模服務層級 之前,客戶可能會遇到單個資料庫的 容量限制。 雖然超大規模資料庫彈性集區提供了高得多的儲存體限制,但其他服務層級中的彈性集區和集區資料庫仍可能會受到非超大規模資料庫服務層級中的儲存體容量限制所限制。
下列兩節討論兩個選項,用於解決當您無法使用超大規模資料庫服務層級時,Azure SQL 資料庫中的大型資料庫的問題。
注意
彈性集區不適用於 Azure SQL 受控執行個體、SQL Server 執行個體內部部署、Azure VM 上的 SQL Server 或 Azure Synapse Analytics。
跨資料庫分區化
因為 Azure SQL 資料庫會在商用硬體上執行,所以個別資料庫的容量限制會比傳統的內部部署 SQL Server 安裝更低。 有些客戶會在資料庫作業不符合 Azure SQL 資料庫中的個別資料庫限制時,使用分區化技術在多個資料庫散佈這些作業。 在 Azure SQL 資料庫中使用分區化技術的大部分客戶都會在跨多個資料庫的單一維度上分割其資料。 針對此方法,您必須了解 OLTP 應用程式通常會執行的交易只會套用到結構描述內的一個資料列或一小組資料列。
注意
Azure SQL Database 現在提供可協助分區化的程式庫。 如需詳細資訊,請參閱 彈性資料庫用戶端程式庫概觀。
例如,如果資料庫有客戶名稱、訂單及訂單詳細資料 (如 AdventureWorks 資料庫中),則您可以透過以相關訂單和訂單詳細資料等資訊來分組客戶,將這項資料分割至多個資料庫。 您可以保證客戶的資料會保留在個別資料庫內。 應用程式會跨資料庫分割不同的客戶,跨多個資料庫有效分配負載。 透過分區化,客戶不但可以避免資料庫大小上限,Azure SQL 資料庫也能處理明顯大於不同計算大小限制的工作負載,前提是每個個別資料庫符合其服務層級限制。
雖然資料庫分區化不會減少方案的彙整資源容量,但可以非常有效地支援分配到多個資料庫的非常大型方案。 每個資料庫可以在不同的計算大小執行以支援具有高資源需求且非常大型的「有效」資料庫。
功能資料分割
使用者通常會在個別資料庫內結合許多功能。 例如,如果應用程式有管理商店庫存的邏輯,該資料庫可能具有的邏輯會與庫存、追蹤訂單、預存程序和管理月底報告的索引或具體化檢視相關聯。 這項技術可以簡化備份等作業的資料庫管理,但也需要您調整硬體大小來跨應用程式的所有功能處理尖峰負載。
如果您在 Azure SQL 資料庫中使用相應放大架構,則最好將應用程式的不同功能分割至不同資料庫。 如果使用這項技術,每個應用程式都可以獨立縮放。 隨著應用程式變得更忙碌 (而且資料庫上的負載增加),系統管理員可為應用程式內的每個功能選擇獨立的計算大小。 此架構在達到限制時,應用程式會比單一商用電腦可處理的應用程式還大,因為負載會分配給多部電腦。
批次查詢
對於使用大量、頻繁的特定查詢存取資料的應用程式而言,大量的回應時間都花費在應用程式層和和資料庫層之間的網路通訊上。 即使應用程式和資料庫都位於相同的資料中心,兩者之間的網路延遲還是可能因為大量資料存取作業而放大。 若要減少資料存取作業的網路往返,請考慮選擇批次處理特定查詢或將其編譯成預存程序。 如果您批次處理特定查詢,您可以將多個查詢當做一個大型批次,在單一往返中傳送到資料庫。 如果您在預存程序中編譯特定查詢,您可以達到和對其進行批次處理時相同的結果。 使用預存程序也能讓您獲益,因為在資料庫中快取查詢計劃的機會增加,因此您可以再次使於預存程序。
某些應用程式是寫入密集型的。 有時候,您可以藉由考慮如何一併批次處理寫入來減少資料庫上的 IO 總負載。 這通常與在預存程序及臨機操作批次內使用明確交易而不是自動認可交易一樣簡單。 如需評估您可以使用的不同技術,請參閱 Azure 中資料庫應用程式的批次處理技術。 實驗您自己的工作負載來尋找正確的批次處理模型。 請務必了解,模型在交易一致性保證上可能稍有不同。 要尋找可最小化資源使用的適當工作負載,就必須找出一致性與效能權衡取捨的正確組合。
應用程式層快取
某些資料庫應用程式具有大量讀取工作負載。 對應用程式層進行快取可能會減少資料庫上的負載,並可能藉由使用 Azure SQL 資料庫而有機會降低支援資料庫所需的計算大小。 使用 Azure Cache for Redis時,如果您具有大量讀取工作負載,您可以讀取資料一次 (或可能每個應用程式層電腦讀取一次,取決於設定方式),然後將該資料儲存在您的資料庫之外。 此方式可減少資料庫負載 (CPU 和讀取 IO),但會對交易一致性造成影響,因為從快取讀取的資料可能會與資料庫中的資料不同步。 雖然許多應用程式可接受一定程度的不一致性,但並非所有工作負載都是如此。 您應該充分了解應用程式的任何需求,然後再實作應用程式層快取策略。
取得設定和設計秘訣
若使用 Azure SQL 資料庫,可以執行開放原始碼 T-SQL 指令碼,以改善 Azure SQL 資料庫中的資料庫設定與設計。 該指令碼會隨需分析您的資料庫,並提供可改善資料庫效能與健康狀態的提示。 某些秘訣會根據最佳做法來建議設定和操作變更,而其他秘訣則建議適合您工作負載的設計變更,例如啟用進階資料庫引擎功能。
若要深入了解指令碼並開始使用,請前往 Azure SQL 提示 Wiki 頁面。
若要掌握 Azure SQL 資料庫 的最新功能和更新,請參閱Azure SQL 資料庫 的新增功能?