以組織規模管理 Azure Machine Learning 的預算、成本和配額
當您管理從 Azure 機器學習 產生的計算成本時,在具有許多工作負載、許多小組和使用者的組織規模上,有許多管理和優化挑戰需要解決。
在本文中,我們會提供最佳做法,以將成本優化、管理預算,以及與 Azure 機器學習 共用配額。 它反映了在 Microsoft 內部執行機器學習小組所學到的經驗和教訓,同時與客戶合作。 您將了解如何:
- 將計算資源優化以符合工作負載需求。
- 推動小組預算的最佳使用。
- 在企業級規劃、管理和共用預算、成本和配額。
將計算優化以符合工作負載需求
當您開始新的機器學習專案時,可能需要探索工作才能了解計算需求。 本節提供如何判斷定型的正確虛擬機 (VM) SKU 選擇、推斷,或做為工作站來運作的建議。
判斷定型的計算大小
定型工作負載的硬體需求可能會因項目而異。 為了符合這些需求,Azure 機器學習 計算提供各種類型的 VM:
- 一般用途: 平衡的CPU與記憶體比率。
- 記憶體優化: 高記憶體與CPU比率。
- 計算優化: 高 CPU 與記憶體比率。
- 高效能計算: 為各種真實世界的 HPC 工作負載提供領先階層的效能、延展性和成本效益。
- 具有 GPU 的實例: 以大量圖形轉譯和視訊編輯為目標的特製化虛擬機,以及具有深度學習的模型定型和推斷(ND)。
您可能還不知道計算需求是什麼。 在此案例中,我們建議從下列其中一個符合成本效益的默認選項開始。 這些選項適用於輕量型測試和定型工作負載。
| 類型 | 虛擬機器大小 | 規格 |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 個核心、14 GB 的 RAM、28 GB 的記憶體 |
| GPU | Standard_NC6 | 6 個核心、56 GB (GB) RAM、380 GB 記憶體、NVIDIA Tesla K80 GPU |
若要取得案例的最佳 VM 大小,它可能包含試用和錯誤。 以下是幾個需要考慮的層面。
- 如果您需要 CPU:
- 如果您要訓練大型數據集,請使用記憶體優化 VM。
- 如果您正在執行即時推斷或其他延遲敏感性工作,請使用計算優化的 VM。
- 使用具有更多核心和 RAM 的 VM,以加速定型時間。
- 如果您需要 GPU,請參閱 GPU 優化 VM 大小 ,以取得選取 VM 的相關信息。
- 如果您要進行分散式定型,請使用具有多個 GPU 的 VM 大小。
- 如果您要在多個節點上執行分散式定型,請使用具有NVLink 連線的 GPU。
當您選取最符合工作負載的 VM 類型和 SKU 時,請將可比較的 VM SKU 評估為 CPU 和 GPU 效能與定價之間的取捨。 從成本管理的觀點來看,作業可能會在數個 SKU 上執行得相當良好。
某些 GPU,例如 NC 系列,特別是NC_Promo SKU,與其他 GPU 有類似的能力,例如低延遲,而且能夠平行管理多個運算工作負載。 相較於其他一些 GPU,它們以折扣價格提供。 考慮選取工作負載的 VM SKU,最終可能會大幅節省成本。
使用率重要性的提醒是註冊較多的 GPU 不一定以更快的結果執行。 相反地,請確定 GPU 已完全使用。 例如,仔細檢查 NVIDIA CUDA 的需求。 雖然可能需要執行高效能 GPU,但您的作業可能不相依於它。
判斷推斷的計算大小
推斷案例的計算需求與定型案例不同。 可用選項會根據您的案例需要批次離線推斷,或需要即時在線推斷而有所不同。
針對即時推斷案例,請考慮下列建議:
- 在模型上使用分析功能搭配 Azure 機器學習,以判斷將模型部署為 Web 服務時,需要配置多少 CPU 和記憶體。
- 如果您要進行即時推斷,但不需要高可用性,請部署至 Azure 容器執行個體(沒有 SKU 選取專案)。
- 如果您要進行即時推斷,但需要高可用性,請部署至 Azure Kubernetes Service。
- 如果您使用傳統機器學習模型並接收 < 10 個查詢/秒,請從 CPU SKU 開始。 F 系列 SKU 通常運作良好。
- 如果您使用深度學習模型並接收 > 10 個查詢/秒,請嘗試 NVIDIA GPU SKU(NCasT4_v3通常適用於 Triton)。
針對批次推斷案例,請考慮下列建議:
- 當您使用 Azure 機器學習 管線進行批次推斷時,請遵循判斷定型的計算大小以選擇初始 VM 大小的指引。
- 水平調整來優化成本和效能。 優化成本和效能的主要方法之一,是在 Azure 機器學習 中平行執行步驟的協助下,平行處理工作負載。 此管線步驟可讓您使用許多較小的節點平行執行工作,這可讓您水平調整。 不過,平行處理會有額外負荷。 視工作負載和可達到的平行處理原則程度而定,平行執行步驟可能或可能不是選項。
判斷計算實例的大小
若要進行互動式開發,建議使用 Azure 機器學習 的計算實例。 計算實例 (CI) 供應專案帶來系結至單一使用者的單一節點計算,並可作為雲端工作站使用。
某些組織不允許在本機工作站上使用生產數據、對工作站環境強制執行限制,或限制在公司 IT 環境中安裝套件和相依性。 計算實例可作為工作站,以克服限制。 它提供具有生產數據存取的安全環境,並在預安裝數據科學熱門套件和工具的映像上執行。
當計算實例執行時,系統會針對 VM 計算、標準 Load Balancer(包括 lb/輸出規則及已處理的數據)、OS 磁碟(進階版 SSD 受控 P10 磁碟)、暫存磁碟(暫存磁碟類型取決於所選的 VM 大小)和公用 IP 位址計費。 若要節省成本,我們建議用戶考慮:
- 當計算實例不在使用中時啟動和停止。
- 使用計算實例上的數據範例,並相應放大至計算叢集以使用完整的數據集
- 在開發或測試時, 或在完整提交作業時切換至共用計算容量時,在計算實例上以本機 計算目標模式提交實驗作業。 例如,許多 epoch、完整數據集和超參數搜尋。
如果您停止計算實例,它會停止 VM 計算時數、暫存磁碟和標準 Load Balancer 數據已處理成本的計費。 請注意,即使計算實例停止,使用者仍需支付OS磁碟和標準Load Balancer隨附的 lb/輸出規則。 儲存在OS磁碟上的任何資料都會透過停止和重新啟動來保存。
藉由監視計算使用率來調整所選的 VM 大小
您可以透過 Azure 監視器來檢視 Azure 機器學習 計算使用量和使用率的相關信息。 您可以檢視模型部署和註冊的詳細數據、使用中和閑置節點等配額詳細數據、執行詳細數據,例如已取消和已完成的執行,以及 GPU 和 CPU 使用率的計算使用率。
根據監視詳細數據的深入解析,您可以更妥善地規劃或調整整個小組的資源使用量。 例如,如果您在過去一周注意到許多閑置節點,您可以與對應的工作區擁有者合作來更新計算叢集設定,以避免產生額外的成本。 分析使用率模式的優點有助於預測成本和預算改善。
您可以直接從 Azure 入口網站 存取這些計量。 移至您的 Azure 機器學習 工作區,然後選取左側面板上 [監視] 區段底下的 [計量]。 然後,您可以選取您想要檢視的詳細數據,例如計量、匯總和時間週期。 如需詳細資訊,請參閱監視 Azure 機器學習 文件頁面。
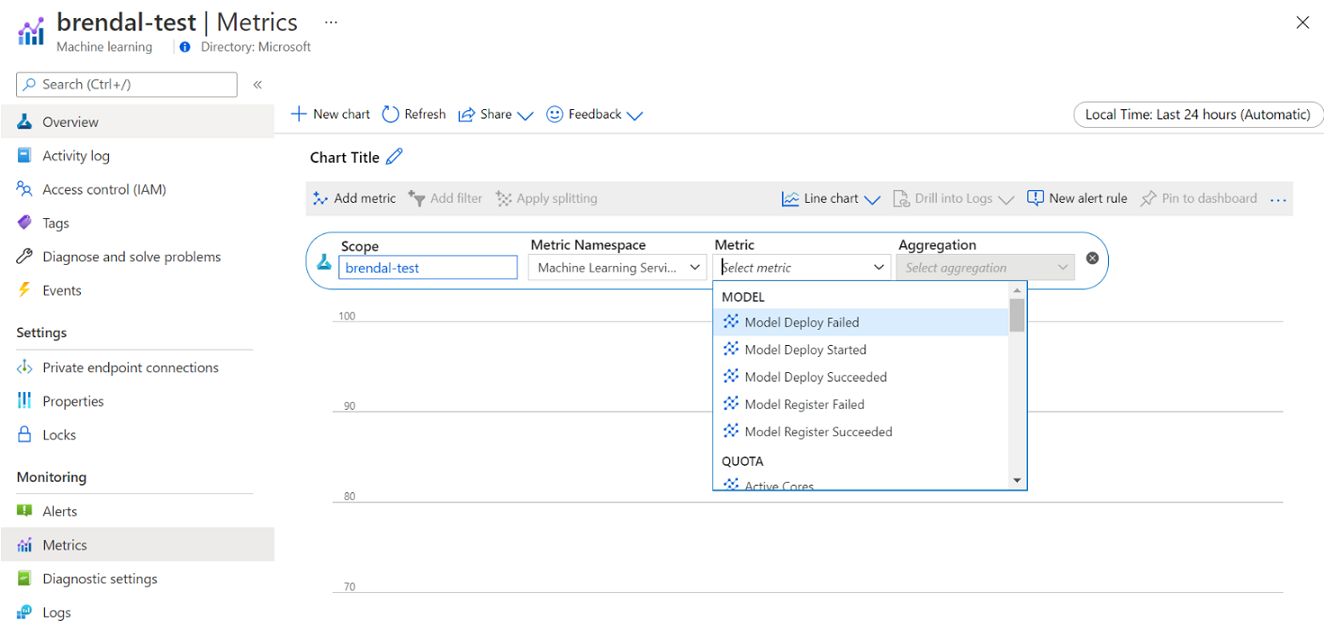
開發時,在本機、單一節點和多節點雲端計算之間切換
機器學習生命週期中有不同的計算和工具需求。 Azure 機器學習 可透過 SDK 和 CLI 介面,從幾乎任何慣用的工作站組態進行介面,以符合這些需求。
若要節省成本並提高生產力,建議您:
- 使用 Git 在本機複製實驗程式代碼基底,並使用 Azure 機器學習 SDK 或 CLI 將作業提交至雲端計算。
- 如果您的數據集很大,請考慮在本機工作站上管理數據的範例,同時將完整數據集保留在雲端記憶體上。
- 將實驗程式代碼基底參數化,讓您可以設定作業以不同數目的 epoch 或不同大小的數據集執行。
- 請勿將數據集的資料夾路徑硬式編碼。 然後,您可以輕鬆地重複使用相同程式代碼基底與不同的數據集,然後在本機和雲端執行內容下。
- 當您開發或測試時,或當您以完整規模提交作業時切換到共用計算叢集容量時,在本機計算目標模式中啟動測試作業。
- 如果您的數據集很大,請使用本機或計算實例工作站上的數據範例,同時調整為 Azure 中的雲端計算 機器學習 以使用完整的數據集。
- 當您的工作需要很長的時間才能執行時,請考慮優化您的程式代碼基底以進行分散式定型,以允許水平相應放大。
- 設計節點彈性的分散式定型工作負載,以允許彈性地使用單一節點和多節點計算,並簡化可優先使用的計算。
使用 Azure 機器學習 管線合併計算類型
當您協調機器學習工作流程時,您可以使用多個步驟來定義管線。 管線中的每個步驟都可以在其自己的計算類型上執行。 這可讓您優化效能和成本,以符合機器學習生命週期的各種計算需求。
推動小組預算的最佳使用
雖然預算配置決策可能無法控制個別小組,但小組通常能夠將其配置預算用於其最佳需求。 藉由以明智方式權衡作業優先順序與效能和成本,小組可以達到較高的叢集使用率、降低整體成本,以及從相同預算使用較多的計算時數。 這可能會導致小組生產力提升。
優化共用計算資源的成本
優化共用計算資源成本的關鍵是確保其已用於其完整容量。 以下是優化共享資源成本的一些秘訣:
- 當您使用計算實例時,只有當您有程式代碼可執行時,才會開啟它們。 未使用時將其關閉。
- 當您使用計算叢集時,請將節點計數下限設定為0,並將節點計數上限設定為根據預算條件約束評估的數位。 使用 Azure 定價計算機來計算所選 VM SKU 中一個 VM 節點的完整使用率成本。 當沒有人使用它時,自動調整將會相應減少所有計算節點。 它只會相應增加至您擁有預算的節點數目。 您可以設定 自動調整 以相應減少所有計算節點。
- 在定型模型時監視您的資源使用率,例如CPU使用率和 GPU 使用率。 如果資源未完全使用,請修改您的程序代碼,以更妥善地使用資源,或相應減少為較小或更便宜的 VM 大小。
- 評估您是否可以為小組建立共用計算資源,以避免叢集調整作業所造成的計算效率不佳。
- 根據使用計量優化計算叢集自動調整逾時原則。
- 使用工作區配額來控制個別工作區可存取的計算資源數量。
藉由建立多個 VM SKU 的叢集來引進排程優先順序
在配額和預算限制下運作,小組必須權衡作業與成本的及時執行,以確保重要的作業能及時執行,並盡可能以最佳方式使用預算。
為了支援最佳的計算使用率,建議小組建立各種大小且 優先順序 低且 具有專用 VM 優先順序的叢集。 低優先順序計算會利用 Azure 中的剩餘容量,因此會隨附折扣費率。 在缺點,只要有更高的優先順序要求進來,這些機器就可以先佔。
使用不同大小和優先順序的叢集,可以引進排程優先順序的概念。 例如,當實驗性和生產作業競爭相同的 NC GPU 配額時,生產作業可能會偏好執行實驗性作業。 在此情況下,請在專用計算叢集上執行生產作業,以及在低優先順序計算叢集上執行實驗性作業。 當配額不足時,實驗性工作將優先於生產工作。
在 VM 優先順序旁邊,請考慮在各種 VM SKU 上執行作業。 作業可能需要比 V100 GPU 更長的時間,才能在具有 P40 GPU 的 VM 實例上執行。 不過,由於 V100 VM 實例可能會佔用或完全使用配額,因此從作業輸送量的觀點來看,P40 上完成的時間可能仍然較快。 您也可以從成本管理的觀點考慮在效能較低且較便宜的 VM 實例上執行優先順序較低的作業。
定型未聚合時提早終止執行
當您持續實驗以針對其基準改善模型時,您可能會執行各種實驗回合,每個執行都有稍微不同的組態。 針對一次執行,您可以調整輸入數據集。 針對另一個執行,您可能會進行超參數變更。 並非所有變更都可能與其他變更一樣有效。 您提早偵測到變更對模型定型質量沒有預期的效果。 若要偵測定型是否不聚合,請在執行期間監視定型進度。 例如,藉由記錄每個定型 epoch 之後的效能計量。 請考慮提前終止工作,以釋出另一個試用版的資源和預算。
規劃、管理和共享預算、成本和配額
隨著組織成長機器學習使用案例和小組的數目,它需要IT與財務的作業成熟度增加,以及個別機器學習小組之間的協調,以確保有效率的作業。 公司規模容量和配額管理對於解決計算資源的稀缺性,並克服管理額外負荷非常重要。
本節討論在企業級規劃、管理和共用預算、成本和配額的最佳做法。 其以管理 Microsoft 內部機器學習的許多 GPU 訓練資源為基礎的學習。
瞭解 Azure 機器學習 的資源支出
作為規劃計算需求的系統管理員,最大的挑戰之一是開始新的,沒有歷程記錄資訊作為基準估計。 從實際意義上說,大多數專案將從小型預算開始,作為第一步。
若要了解預算的所在位置,請務必瞭解 Azure 機器學習 成本的來源:
- Azure 機器學習 只會收取所使用的計算基礎結構費用,而且不會增加計算成本的附加費。
- 建立 Azure 機器學習 工作區時,也會建立一些其他資源來啟用 Azure 機器學習:金鑰保存庫、Application Insights、Azure 儲存體 和 Azure Container Registry。 這些資源會用於 Azure 機器學習,您將支付這些資源的費用。
- 有與受控計算相關聯的成本,例如定型叢集、計算實例和受控推斷端點。 使用這些受控計算資源,有下列基礎結構成本可考慮:虛擬機、虛擬網路、負載平衡器、頻寬和記憶體。
追蹤消費模式,並透過標記達成更佳的報告
管理員 管理員通常想要能夠追蹤 Azure 機器學習 中不同資源的成本。 標記是此問題的自然解決方案,與 Azure 和其他許多雲端服務提供者所使用的一般方法一致。 透過標籤支援,您現在可以在計算層級看到成本明細,因此可讓您存取更細微的檢視,以協助進行更好的成本監視、改善的報告和更高的透明度。
標記可讓您在工作區和計算上放置自定義標籤(從 Azure Resource Manager 範本和 Azure Machine Learning 工作室),根據這些標籤進一步篩選 Microsoft 成本管理中的這些資源,以觀察支出模式。 此功能最適合用於內部計費案例。 此外,卷標對於擷取與計算相關聯的元數據或詳細數據很有用,例如專案、小組或特定計費程序代碼。 這可讓標記非常有利於測量您在不同資源上花費多少資金,因此,深入瞭解您的成本,以及跨小組或項目花費模式。
此外,還有系統插入的標記放在計算上,可讓您依 [計算類型] 標籤在 [成本分析] 頁面中篩選,以查看總支出的計算明智分解,並判斷計算資源類別可能歸結到大部分的成本。 這特別適用於深入瞭解定型與推斷成本模式。
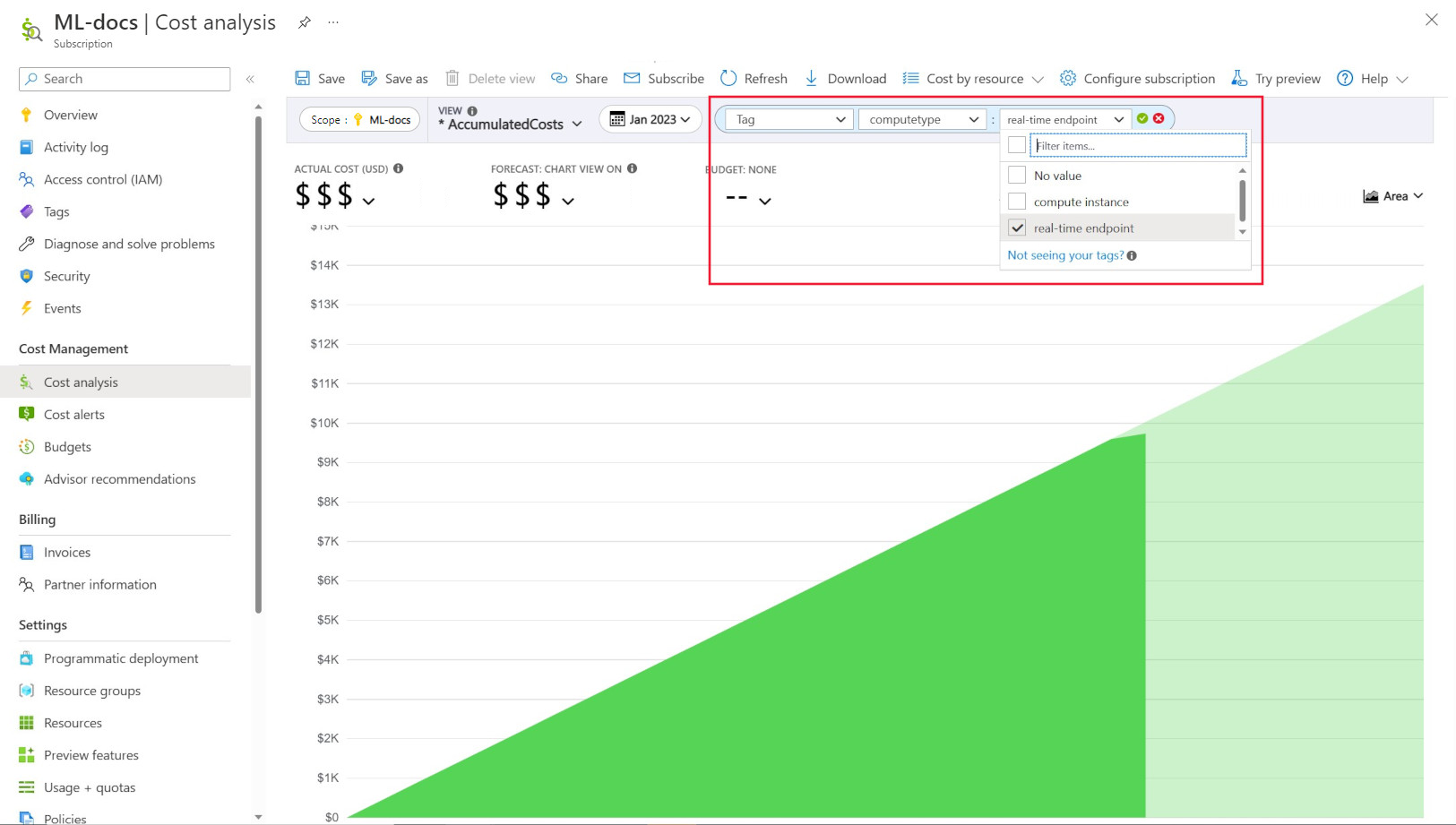
依原則控管和限制計算使用量
當您管理具有許多工作負載的 Azure 環境時,保持資源支出概觀可能會是一項挑戰。 Azure 原則 可藉由限制整個 Azure 環境中的特定使用模式,協助控制和管理資源支出。
針對 Azure 機器學習,建議您設定原則,只允許使用特定的 VM SKU。 原則有助於防止和控制選取昂貴的 VM。 原則也可用來強制執行低優先順序 VM SKU 的使用方式。
根據商務優先順序配置和管理配額
Azure 可讓您在訂用帳戶和 Azure 機器學習 工作區層級上設定配額配置限制。 限制可透過 Azure 角色型存取控制 (RBAC) 管理配額的人員,有助於確保資源使用率和成本可預測性。
GPU 配額的可用性在您的訂用帳戶中可能很少。 為了確保工作負載之間的配額使用率很高,建議您監視配額是否最適合使用,並指派給工作負載。
在 Microsoft 中,它會定期判斷 GPU 配額是否最適合用於機器學習小組,並藉由根據商務優先順序評估容量需求來配置。
預先認可容量
如果您對明年或未來幾年會使用多少計算有很好的估計,您可以以折扣成本購買 Azure 保留的 VM 實例。 有一年或三年的購買條款。 因為 Azure 保留的 VM 實例會折扣,因此相較於隨用隨付價格,可能會節省大量成本。
Azure 機器學習 支援保留的計算實例。 折扣會自動套用至 Azure 機器學習 受控計算。
管理資料保留
每次執行機器學習管線時,每個管線步驟都可以產生中繼數據集,以便進行數據快取和重複使用。 數據成長為這些機器學習管線的輸出,可能會成為執行許多機器學習實驗之組織的痛點。
數據科學家通常不會花時間清除產生的中繼數據集。 經過一段時間后,產生的數據量將會加總。 Azure 儲存體 隨附增強數據生命週期管理的功能。 使用 Azure Blob 儲存體 生命週期管理,您可以設定一般原則,以將未使用的數據移至較冷的儲存層,並節省成本。
基礎結構成本優化考慮
網路
Azure 網路成本是由來自 Azure 資料中心的輸出頻寬所產生。 所有 Azure 資料中心的輸入數據都是免費的。 降低網路成本的關鍵是盡可能在相同的數據中心區域中部署所有資源。 如果您可以在具有相同數據的相同區域中部署 Azure 機器學習 工作區和計算,您可以享有較低的成本和更高的效能。
您可能想要在內部部署網路與 Azure 網路之間建立私人連線,以擁有混合式雲端環境。 ExpressRoute 可讓您這麼做,但考慮到 ExpressRoute 的高成本,移出混合式雲端設定並將所有資源移至 Azure 雲端可能更有成本效益。
Azure Container Registry
針對 Azure Container Registry,成本優化的決定因素包括:
- 從容器登錄下載至 Azure 機器學習 Docker 映射所需的輸送量
- 企業安全性功能的需求,例如 Azure Private Link
針對需要高輸送量或企業安全性的生產案例,建議使用 Azure Container Registry 進階版 SKU。
對於輸送量和安全性較不重要的開發/測試案例,我們建議使用標準 SKU 或 進階版 SKU。
Azure Container Registry 的基本 SKU 不建議用於 Azure 機器學習。 不建議這麼做,因為其低輸送量和低內含記憶體,Azure 機器學習 相對大型的 Docker 映像可快速超過此記憶體。
選擇 Azure 區域時,請考慮計算類型可用性
當您 挑選計算的區域時,請記住計算配額可用性。 美國東部、美國西部和西歐等熱門和較大的區域,相較於某些其他具有更嚴格容量限制的區域,默認配額值和多數 CPU 的可用性通常會較高。
深入了解
下一步
若要深入瞭解如何組織和設定 Azure 機器學習 環境,請參閱組織和設定 Azure 機器學習 環境。
若要瞭解搭配 Azure 機器學習 機器學習 DevOps 的最佳做法,請參閱機器學習 DevOps 指南。