使用以虛擬核心為基礎的 Azure Cosmos DB for MongoDB 擷取增強世代 (RAG)
在產生 AI 的快速進化領域,GPT-3.5 等大型語言模型 (LLM) 已轉換自然語言處理。 不過,AI 中的新興趨勢是使用向量存放區,這在增強 AI 應用程式方面發揮著關鍵作用。
本教學課程將探討如何使用 Azure Cosmos DB for MongoDB (vCore)、LangChain 和 OpenAI 來實作擷取擴增生成 (RAG),以提升 AI 效能,同時討論 LLM 及其限制。 我們會探索「儲存體擷取擴增生成」(RAG) 的快速採用範例,並簡短討論 LangChain 架構 Azure OpenAI 模型。 最後,我們會將這些概念整合到真實世界的應用程式。 最後,讀者將對這些概念有紮實的理解。
了解大型語言模型 (LLM) 及其限制
大型語言模型 (LLM) 是針對大量文字資料集定型的進階深度類神經網路模型,可讓他們了解並產生類似人類文字的模型。 雖然在自然語言處理方面具有革命性,但 LLM 有固有的限制:
- 幻覺:LLM 有時會產生事實不正確或非前景的資訊,稱為「幻覺」。
- 過時資料:LLM 會在可能不包含最新資訊的靜態資料集上定型,並限制其目前相關性。
- 無法存取使用者的本機資料:LLM 無法直接存取個人或當地語系化資料,限制其提供個人化回應的能力。
- 權杖限制:LLM 每個互動都有最大權杖限制,限制他們可以一次處理的文字數量。 例如,OpenAI 的 gpt-3.5-turbo 的權杖限製為 4096。
利用擷取擴增生成 (RAG)
儲存體擷取擴增生成 (RAG) 是一種架構,旨在克服 LLM 限制。 RAG 會使用向量搜尋,根據輸入查詢擷取相關文件,提供這些文件做為 LLM 的內容,以產生更精確的回應。 RAG 不只依賴預先定型的模式,而是藉由納入最新的相關資訊來增強回應。 此方法有助於:
- 最小化幻覺:以事實資訊為基礎回應。
- 確保目前的資訊:擷取最新的資料,以確保最新的回應。
- 利用外部資料庫:雖然這不會授與個人資料的直接存取權,但 RAG 允許與外部使用者特定的知識庫整合。
- 最佳化權杖使用:藉由專注於最相關的文件,RAG 可讓權杖使用更有效率。
本教學課程示範如何使用 Azure Cosmos DB for MongoDB (vCore) 實作 RAG,以建置專為您的資料量身打造的問答應用程式。
應用程式架構概觀
下圖說明 RAG 實作的主要元件:
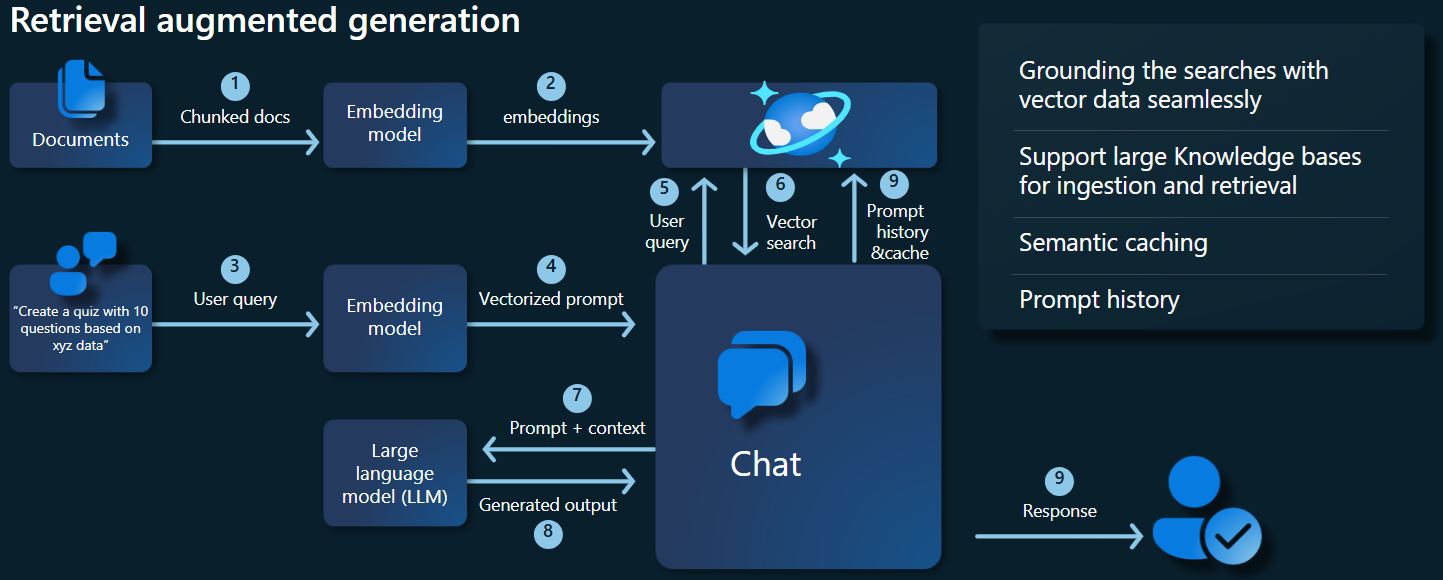
重要元件和架構
我們現在將討論本教學課程中使用的各種架構、模型和元件,強調其角色和細微差別。
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (vCore) 支援語意相似性搜尋,對於 AI 支援的應用程式而言至關重要。 允許以各種格式的資料表示為向量內嵌,可以與源資料和中繼資料一起儲存。 使用近似鄰近演算法,例如階層式導覽小型世界 (HNSW),可以查詢這些內嵌以快速的語意相似性搜尋。
LangChain 架構
LangChain 為常見工作提供鏈結、多個工具整合和端對端鏈結的標準介面,藉此簡化 LLM 應用程式的建立。 可讓 AI 開發人員建置利用外部資料源的 LLM 應用程式。
LangChain 的主要層面:
- 鏈結:解決特定工作的元件序列。
- 元件:LLM 包裝函式、向量存放區包裝函式、提示範本、資料載入器、文字分隔器和擷取器等模組。
- 模組化:簡化開發、偵錯和維護。
- 熱門:開放原始碼專案可快速獲得採用並不斷演進,以符合使用者需求。
Azure 應用程式服務介面
應用程式服務提供強大的平台,可建置適用於 Gen-AI 應用程式的易用 Web 介面。 本教學課程會使用 Azure 應用程式服務來建立應用程式的互動式 Web 介面。
OpenAI 模型
OpenAI 是 AI 研究的龍頭,提供各種用於語言產生、文字向量化、影像建立和音訊到文字轉換的模型。 在本教學課程中,我們將使用 OpenAI 的內嵌和語言模型,這對於了解和產生以語言為基礎的應用程式至關重要。
內嵌模型與語言生成模型
| 類別 | 文字內嵌模型 | 語言模型 |
|---|---|---|
| 用途 | 將文字轉換成向量內嵌。 | 了解並產生自然語言。 |
| Function | 將文字資料轉換成數位的高維度陣列,擷取文字的語意意義。 | 根據指定的輸入,理解並產生類似人類文字的文字。 |
| 輸出 | 數字陣列 (向量內嵌)。 | 文字、答案、翻譯、程式碼等。 |
| 範例輸出 | 每個內嵌都以數值形式代表文字的語意意義,而模型所決定的維度。 例如,text-embedding-ada-002 會產生具有 1536 個維度的向量。 |
根據提供的輸入產生的內容相關且連貫的文字。 例如,gpt-3.5-turbo 可以產生問題響應、翻譯文字、撰寫程式碼等等。 |
| 一般使用案例 | - 語意搜尋 | - 聊天機器人 |
| - 建議系統 | - 自動化內容建立 | |
| - 文字資料的群集和分類 | - 語言翻譯 | |
| - 資訊擷取 | - 摘要 | |
| 資料表示法 | 數值表示法 (內嵌) | 自然語言文字 |
| 維度性 | 陣列的長度會對應至內嵌空間中的維度數目,例如 1536 個維度。 | 通常以權杖序列表示,內容會決定長度。 |
應用程式的主要元件
- Azure Cosmos DB for MongoDB vCore:儲存和查詢向量內嵌。
- LangChain:建構應用程式的 LLM 工作流程。 使用的工具例如:
- 文件載入器:用於從目錄載入及處理文件。
- 向量存放區整合:用於儲存和查詢 Azure Cosmos DB 中的向量內嵌。
- AzureCosmosDBVectorSearch:Cosmos DB 向量搜尋的包裝函式
- Azure 應用程式服務:建置 Cosmic Food 應用程式的使用者介面。
- Azure OpenAI:提供 LLM 和內嵌模型,包括:
- text-embedding-ada-002:文字內嵌模型,可將文字轉換成具有 1536 維度的向量內嵌。
- gpt-3.5-turbo:用於理解和產生自然語言的語言模型。
設定環境
若要開始使用 Azure Cosmos DB for MongoDB (vCore) 來最佳化擷取擴增生成 (RAG),請遵循下列步驟:
- 在 Microsoft Azure 上建立下列資源:
- Azure Cosmos DB for MongoDB vCore叢集:請參閱 快速入門指南。
- Azure OpenAI 資源:
- 內嵌模型部署 (例如
text-embedding-ada-002)。 - 聊天模型部署 (例如
gpt-35-turbo)。
- 內嵌模型部署 (例如
範例文件
在本教學課程中,我們將使用文件載入單一文字檔。 這些檔案應該儲存在 src 資料夾中名為資料的目錄中。 其中內容如下:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
載入文件
設定適用於 MongoDB 的 Cosmos DB (vCore) 連接字串、資料庫名稱、集合名稱和索引:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]初始化內嵌用戶端。
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )從資料建立內嵌,儲存至資料庫,並傳回與向量存放區 Cosmos DB for MongoDB (vCore) 的連線。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )在集合上建立下列 HNSW 向量 Index (請注意索引的名稱與上述名稱相同)。
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
使用 Cosmos DB for MongoDB (vCore) 執行向量搜尋
連線到您的向量存放區。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )定義在查詢上使用 Cosmos DB 向量搜尋來執行語意相似性搜尋的函式 (請注意,此代碼段只是測試函式)。
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)初始化 Chat Client 以實作 RAG 函式。
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )建立 RAG 函式。
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )將向量存放區轉換成擷取器,以根據指定的參數搜尋相關文件。
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )建立了解交談歷程記錄的擷取器鏈結,確保使用 azure_openai_chat 模型和 vector_store_retriever 的內容相關文件擷取。
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)使用語言模型 (azure_openai_chat) 和指定的提示 (context_prompt),建立鏈結,將擷取的文件結合成一致的回應。
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)建立處理整個擷取程序的鏈結,整合記錄感知擷取器鏈結和文件組合鏈結。 您可以執行此 RAG 鏈結來擷取並產生內容正確的回應。
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
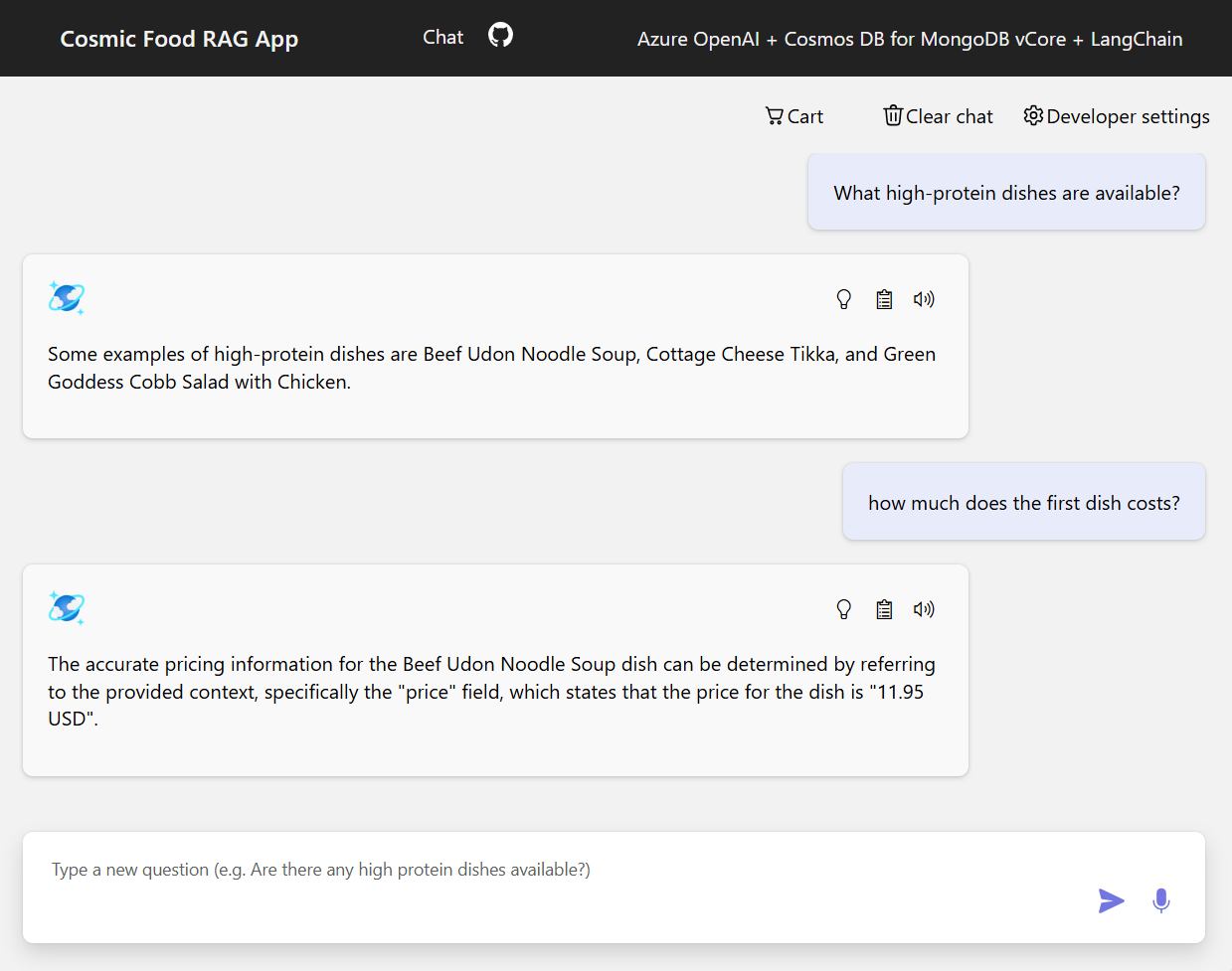
範例輸出
下列螢幕擷取畫面說明各種問題的輸出。 純粹的語意相似性搜尋會從來源文件傳回原始文字,而使用RAG架構的問答應用程式會藉由結合擷取的文件內容與語言模型來產生精確的個人化答案。
結論
在本教學課程中,我們探索如何使用 Cosmos DB 作為向量存放區,建置與私人資料互動的問答應用程式。 藉由利用 LangChain 和 Azure OpenAI 的擷取擴增生成 (RAG) 架構,我們示範向量存放區對於 LLM 應用程式而言非常重要。
RAG 是 AI 的顯著進步,特別是在自然語言處理中,結合這些技術可針對各種使用案例建立強大的 AI 驅動應用程式。