使用 Azure Data Factory 或 Synapse Analytics 將資料複製到 Azure AI 搜尋服務索引
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
此文章概述如何使用 Azure Data Factory 或 Synapse Analytics 管線中的複製活動,將資料複製到 Azure AI 搜尋服務索引。 本文是根據複製活動概觀一文,該文提供複製活動的一般概觀。
支援的功能
下列功能支援此 Azure AI 搜尋服務連接器:
| 支援的功能 | IR | 受控私人端點 |
|---|---|---|
| 複製活動 (-/sink) | (1) (2) | ✓ |
① Azure 整合執行階段 ② 自我裝載整合執行階段
您可以將資料從任何支援的來源資料存放區複製到搜尋索引。 如需複製活動所支援作為來源/接收器的資料存放區清單,請參閱支援的資料存放區表格。
開始使用
若要透過管線執行複製活動,您可以使用下列其中一個工具或 SDK:
使用 UI 建立 Azure 搜尋連結服務
使用下列步驟,在 Azure 入口網站 UI 中建立 Azure 搜尋連結服務。
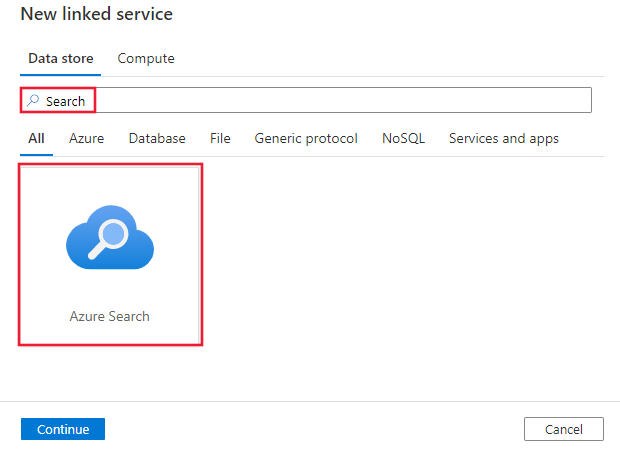
前往 Azure Data Factory 或 Synapse 工作區的 [管理] 索引標籤,選取 [連結服務],然後按一下 [新增]:
搜尋「搜尋」,然後選取 [Azure 搜尋服務] 連接器。
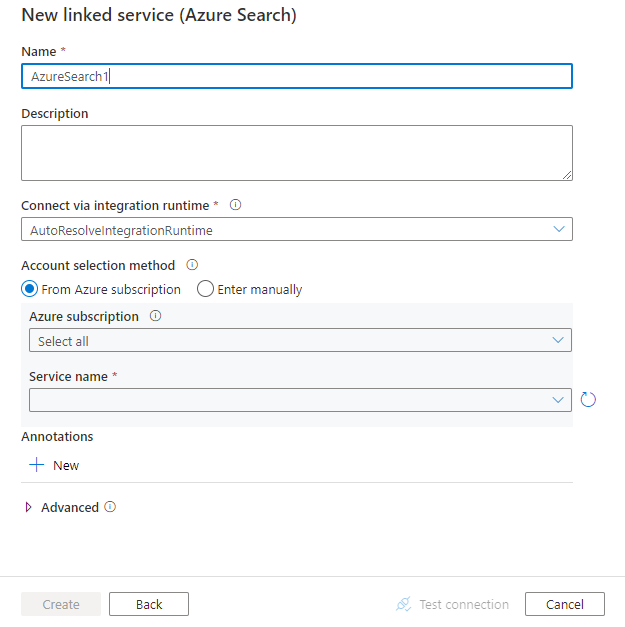
設定服務詳細資料,測試連線,然後建立新的連結服務。

連接器設定詳細資料
下列各節提供屬性的相關詳細資料,這些屬性是用來定義 Azure AI 搜尋服務連接器專屬的 Data Factory 實體。
連結服務屬性
以下是針對 Azure AI 搜尋服務連結服務支援的屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 類型屬性必須設定為:AzureSearch | Yes |
| URL | 搜尋服務的 URL。 | Yes |
| 索引鍵 | 搜尋服務的系統管理金鑰。 將此欄位標記為 SecureString 以便安全儲存,或參考 Azure Key Vault 中儲存的祕密。 | Yes |
| connectVia | 用於連線到資料存放區的 Integration Runtime。 您可以使用 Azure Integration Runtime 或「自我裝載 Integration Runtime」(如果您的資料存放區位於私人網路中)。 如果未指定,就會使用預設的 Azure Integration Runtime。 | No |
重要
從雲端數據存放區將數據複製到搜尋索引時,在 Azure AI 搜尋連結服務中,您需要在 connectVia 中參考具有明確區域的 Azure Integration Runtime。 請將區域設定為您搜尋服務所在的區域。 請參閱 Azure Integration Runtime 以深入了解。
範例:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
資料集屬性
如需可用來定義資料集的區段和屬性完整清單,請參閱資料集一文。 本節提供 Azure AI 搜尋服務資料集所支援的屬性清單。
若要將資料複製到 Azure AI 搜尋服務,則需支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的類型屬性必須設定為:AzureSearchIndex | Yes |
| IndexName | 搜尋索引的名稱。 服務不會建立索引。 索引必須存在於 Azure AI 搜尋服務中。 | Yes |
範例:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線一文。 本節提供 Azure AI 搜尋服務來源所支援的屬性清單。
Azure AI 搜尋服務作為接收器
若要將資料複製到 Azure AI 搜尋服務,請將複製活動中的來源類型設定為 AzureSearchIndexSink。 複製活動的 sink 區段支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的類型屬性必須設定為:AzureSearchIndexSink | Yes |
| writeBehavior | 指定若文件已經存在於索引中,是否要合併或取代。 請參閱 WriteBehavior 屬性。 允許的值為:Merge (預設值) 和 Upload。 |
No |
| writeBatchSize | 當緩衝區大小達到 writeBatchSize 時,系統會將資料上傳至搜尋索引。 如需詳細資訊,請參閱 WriteBatchSize 屬性。 允許的值為:整數 1 到 1,000;預設值為 1000。 |
No |
| maxConcurrentConnections | 在活動執行期間建立至資料存放區的同時連線上限。 僅在想要限制並行連線時,才需要指定值。 | No |
WriteBehavior 屬性
AzureSearchSink 會在寫入資料時更新插入。 換句話說,在撰寫文件時,如果文件索引鍵已經存在於搜尋索引中,Azure AI 搜尋服務就會更新現有的文件,而不是擲回衝突例外狀況。
AzureSearchSink (藉由使用 AzureSearch SDK) 提供下列兩種更新插入行為:
- 合併︰將新文件中的所有資料行與現有的文件相結合。 對於新文件中含有 null 值的資料行,則會保留現有文件中的值。
- 上傳:新的文件會取代現有的文件。 針對新文件中未指定的資料行,不論現有的文件中是否具有非 null 的值,都會將值設為 null。
預設行為是合併。
WriteBatchSize 屬性
Azure AI 搜尋服務支援批次寫入文件。 一個批次可包含 1 到 1,000 個動作。 一個動作可指示一份文件來執行上傳/合併作業。
範例:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
資料類型支援
下表指出是否支援 Azure AI 搜尋服務資料類型。
| Azure AI 搜尋服務資料類型 | 在 Azure AI 搜尋服務接收器中受到支援 |
|---|---|
| String | Y |
| Int32 | Y |
| Int64 | Y |
| Double | Y |
| 布林值 | Y |
| DataTimeOffset | Y |
| 字串陣列 | 否 |
| GeographyPoint | 否 |
目前不支援其他資料類型,例如 ComplexType。 如需 Azure AI 搜尋服務支援之資料類型的完整清單,請參閱支援的資料類型 (Azure AI 搜尋服務)。
相關內容
如需複製活動支援作為來源和接收器的資料存放區清單,請參閱支援的資料存放區。