使用資料流程將檔案寫入資料湖的最佳做法
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
如果您不熟悉 Azure Data Factory,請參閱 Azure Data Factory 簡介。
在本教學課程中,您將瞭解使用資料流程將檔案寫入 ADLS Gen2 或 Azure Blob 儲存體時可套用的最佳做法。 您需要存取 Azure Blob 儲存體帳戶或 Azure Data Lake Store Gen2 帳戶,才能讀取 parquet 檔案,然後將結果儲存在資料夾中。
必要條件
- Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費 Azure 帳戶。
- Azure 儲存體帳戶。 您使用 ADLS 儲存體作為「來源」和「接收」資料存放區。 如果您沒有儲存體帳戶,請參閱建立 Azure 儲存體帳戶,按照步驟建立此帳戶。
本教學課程中的步驟假設您有
建立資料處理站
在此步驟中,您可以建立資料處理站,並開啟 Data Factory UX,以在資料處理站中建立管線。
開啟 Microsoft Edge 或 Google Chrome。 目前僅 Microsoft Edge 和 Google Chrome 網頁瀏覽器支援 Data Factory UI。
在左側功能表上,選取 [建立資源]>[整合]>[Data Factory]
在 [新增資料處理站] 頁面的 [名稱] 下,輸入 ADFTutorialDataFactory
選取您要在其中建立資料處理站的 Azure 訂用帳戶。
針對 [資源群組],採取下列其中一個步驟︰
a. 選取 [使用現有的] ,然後從下拉式清單選取現有的資源群組。
b. 選取 [新建],然後輸入資源群組的名稱。若要了解資源群組,請參閱使用資源群組來管理您的 Azure 資源。
在 [版本] 下,選取 [V2]。
在 [位置] 下,選取資料處理站的位置。 只有受到支援的位置會顯示在下拉式清單中。 資料處理站使用的資料存放區 (例如 Azure 儲存體和 SQL Database) 和計算 (例如 Azure HDInsight) 可位於其他區域。
選取 建立。
建立完成後,您會在 [通知中心] 看到通知。 選取 [移至資源],以瀏覽至 Data Factory 頁面。
選取 [編寫與監視],以在個別索引標籤中啟動 Data Factory 使用者介面。
建立具有資料流程活動的管線
在此步驟中,您將建立包含資料流程活動的管線。
在 Azure Data Factory 的首頁上選取 [協調]。
![此螢幕擷取畫面顯示已醒目提示 [協調] 按鈕的資料處理站首頁。](media/tutorial-data-flow/orchestrate.png)
在管線的 [一般] 索引標籤中,輸入 DeltaLake 作為管線的 [名稱]。
在處理站頂端列中,將 [資料流程偵錯] 滑杆調到開啟。 偵錯模式可讓您對即時 Spark 叢集進行轉換邏輯的互動式測試。 資料流程叢集需要 5-7 分鐘的準備時間,如果使用者想要進行資料流程開發,建議使用者先開啟偵錯功能。 如需詳細資訊,請參閱偵錯模式。

在 [活動] 窗格中,展開 [移動和轉換] 摺疊式功能表。 將 [資料流程] 活動從窗格拖放到管線畫布。
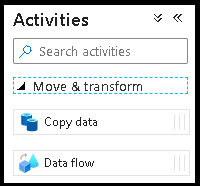
在 [新增資料流程] 快顯視窗中,選取 [建立新的資料流程],然後將資料流程命名為 DeltaLake。 完成時按一下 [完成]。
在資料流程畫布中建置轉換邏輯
您將採用任何來源資料 (在本教學課程中,我們將使用 Parquet 檔案來源) 並使用接收轉換且利用最有效的資料湖 ETL 機制以 Parquet 格式登陸資料。

教學課程目標
- 選擇新資料流程 1 中的任何來源資料集。使用資料流程有效地分割接接收器資料集
- 將分割的資料放在 ADLS Gen2 Lake 資料夾中
從空白資料流程畫布開始
首先,讓我們針對下述每個機制設定資料流程環境,以在 ADLS Gen2 中登陸資料
- 按一下來源轉換。
- 在底部面板中,按一下資料集旁的新建按鈕。
- 選擇資料集,或建立新的資料集。 在此示範中,我們將使用名為 User Data 的 Parquet 資料集。
- 加入衍生的資料行轉換。 我們將以此作為動態設定所需資料夾名稱的方式。
- 新增接收轉換。
階層式資料夾輸出
在您的資料中使用唯一值來建立資料夾階層,以分割資料湖中的資料是很常見的。 這是在 Lake 和 Spark (資料流程背後的計算引擎) 中組織和處理資料的最佳方式。 不過,以這種方式組織您輸出會有一小部分的效能成本。 預期在接收中使用這項機制,整體管道效能會稍微減少。
- 返回資料流程設計工具,並編輯上面建立的資料流程。 按一下接收轉換。
- 按一下 [最佳化] > [設定資料分割] > [索引鍵]
- 挑選您想要用來設定階層資料夾結構的資料行。
- 請注意,下列範例使用 year 和 month 作為資料夾命名的資料行。 結果將是
releaseyear=1990/month=8形式的資料夾。 - 存取資料流程來源中的資料分割區時,您只會指向
releaseyear上方的最上層資料夾,並針對每個後續資料夾使用萬用字元模式,例如:**/**/*.parquet - 若要操作資料值,或即使需要為資料夾名稱產生綜合值,請使用衍生的資料行轉換來建立您想要在資料夾名稱中使用的值。
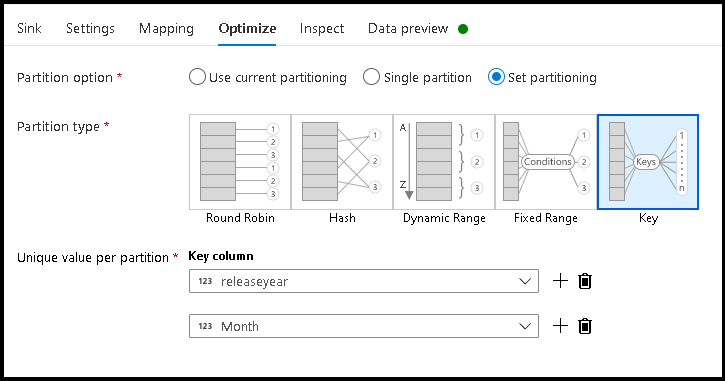
將資料夾命名為資料值
使用 ADLS Gen2 的資料湖效能較好一點的接收技術是 Name folder as column data,它不提供與索引鍵/值資料分割相同的優體。 雖然階層式結構的索引鍵資料分割樣式可讓您更輕鬆地處理資料配量,但這項技術是可更快速地寫入資料的扁平化資料夾結構。
- 返回資料流程設計工具,並編輯上面建立的資料流程。 按一下接收轉換。
- 按一下 [最佳化] > [設定資料分割] > [使用目前的資料分割]。
- 按一下 [設定] > [將資件夾命名為資料行資料]。
- 挑選您想要用來產生資料夾名稱的資料行。
- 若要操作資料值,或即使需要為資料夾名稱產生綜合值,請使用衍生的資料行轉換來建立您想要在資料夾名稱中使用的值。
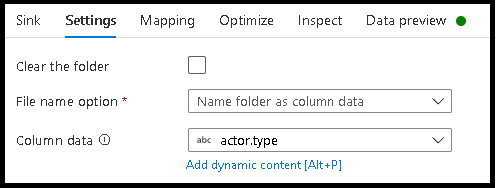
將檔案命名為資料值
上述教學課程中所列的技術是在您的資料湖中建立資料夾類別的良好使用案例。 這些技術採用的預設檔案命名配置是使用 Spark 執行程式作業識別碼。 有時候您可能想要在資料流程文字接收中設定輸出檔案的名稱。 這項技術僅建議用於小型檔案。 將分割區檔案合併到單一輸出檔案的流程是長時間執行的流程。
- 返回資料流程設計工具,並編輯上面建立的資料流程。 按一下接收轉換。
- 按一下 [最佳化] > [設定資料分割] > [分割單一分割區]。 正是這種單一分割區需求在檔案合併時的執行流程中產生瓶頸。 只有小型檔案才建議使用此選項。
- 按一下 [設定] > [將檔案命名為資料行資料]。
- 挑選您想要用來產生檔案名稱的資料行。
- 若要操作資料值,或即使需要為檔案名稱產生綜合值,請使用衍生的資料行轉換來建立您想要在檔案名稱中使用的值。
相關內容
深入了解資料流程接收。