作業系統數據表參考
注意
架構 lakeflow 先前稱為 workflow。 這兩個架構的內容都相同。 若要讓 lakeflow 架構可見,您必須個別啟用它。
本文作為使用 lakeflow 系統數據表來監控帳戶中作業的參考。 這些數據表包含您帳戶中部署於相同雲端區域之所有工作區的記錄。 若要查看來自另一個區域的記錄,您必須從部署於該區域的工作區檢視數據表。
要求
- 帳戶管理員必須啟用
system.lakeflow架構。請參閱 啟用系統數據表架構。 - 若要存取這些系統數據表,用戶必須:
- 同時為中繼存放區管理員和帳戶管理員,或
- 具有系統架構的
USE和SELECT許可權。 請參閱 授與系統資料表的存取權。
可用的作業數據表
所有作業相關的系統數據表都存在於架構中 system.lakeflow 。 目前,架構會裝載四個數據表:
| 桌子 | 描述 | 支援串流 | 免費保留期間 | 包含全域或區域數據 |
|---|---|---|---|---|
| 職位(公開預覽) | 追蹤帳戶中建立的所有工作 | 是的 | 365 天 | 區域性 |
| job_tasks (公開預覽版) | 追蹤在帳戶中執行的所有作業工作 | 是的 | 365 天 | 區域性 |
| job_run_timeline (公開預覽) | 追蹤作業的執行情況和相關的元數據 | 是的 | 365 天 | 地域 |
| job_task_run_timeline (公開預覽) | 記錄工作執行和相關元數據 | 是的 | 365 天 | 地域 |
詳細的架構參考
下列各節提供每個作業相關系統數據表的架構參考。
作業數據表架構
jobs 數據表是緩時變維度數據表 (SCD2)。 當數據列變更時,會發出新的數據列,以邏輯方式取代前一個數據列。
資料表路徑: system.lakeflow.jobs
| 資料行名稱 | 資料類型 | 描述 | 筆記 |
|---|---|---|---|
account_id |
字串 | 此作業所屬帳戶的ID標識碼 | |
workspace_id |
字串 | 此作業所屬工作區的ID | |
job_id |
字串 | 工作的識別碼 | 僅在單一工作區內具有唯一性 |
name |
字串 | 使用者提供的工作名稱 | |
description |
字串 | 使用者提供的工作描述 | 2024 年 8 月下旬之前發出的資料列未填入 |
creator_id |
字串 | 創建這項工作的負責人ID | |
tags |
字串 | 與此作業相關聯的使用者提供自定義標籤 | |
change_time |
timestamp | 上次修改作業的時間 | 時區記錄為 +00:00 (UTC) |
delete_time |
timestamp | 使用者刪除作業的時間 | 時區記錄為 +00:00 (UTC) |
run_as |
字串 | 用於作業執行的用戶或服務主體的 ID 及其許可權 |
範例查詢
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
作業工作數據表架構
"工作任務表是一個緩慢變化的維度表(SCD2)。" 當數據列變更時,會發出新的數據列,以邏輯方式取代前一個數據列。
資料表路徑: system.lakeflow.job_tasks
| 資料行名稱 | 資料類型 | 描述 | 筆記 |
|---|---|---|---|
account_id |
字串 | 此作業所屬帳戶的識別碼 | |
workspace_id |
字串 | 此作業所屬工作區的標識碼 | |
job_id |
字串 | 工作的標識碼 | 僅在單一工作區內是唯一的 |
task_key |
字串 | 一個工作中任務的參考鍵 | 僅在單一作業中唯一存在 |
depends_on_keys |
陣列 | 所有此工作上游依賴的任務鍵 | |
change_time |
timestamp | 上次修改任務的時間 | 時區記錄為 +00:00 (UTC) |
delete_time |
timestamp | 用戶刪除工作的時間 | 時區記錄為 +00:00 (UTC) |
範例查詢
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
作業執行時程表數據表架構
作業執行時間軸數據表在產生時是不可變且完成的。
資料表路徑: system.lakeflow.job_run_timeline
| 資料行名稱 | 資料類型 | 描述 | 筆記 |
|---|---|---|---|
account_id |
字串 | 此作業所屬帳戶的標識碼 | |
workspace_id |
字串 | 此工作所屬工作區的ID | |
job_id |
字串 | 工作的識別碼 | 此金鑰只在單一工作區內是唯一的 |
run_id |
字串 | 作業執行的識別碼 | |
period_start_time |
timestamp | 運行或時間段的開始時間 | 時區資訊會記錄在值結尾,+00:00 代表UTC |
period_end_time |
timestamp | 運行或時間週期的結束時間 | 時區資訊會記錄在值結尾,+00:00 代表UTC |
trigger_type |
字串 | 可以觸發執行的觸發器類型 | 如需可能的值,請參閱 觸發類型值 |
run_type |
字串 | 作業執行的類型 | 如需可能的值,請參閱 執行類型值 |
run_name |
字串 | 與此作業執行相關聯的用戶指定的執行名稱 | |
compute_ids |
陣列 | 陣列包含父作業執行的計算 ID | 用於識別 SUBMIT_RUN 和 WORKFLOW_RUN 執行類型所使用的作業叢集。 如需其他計算資訊,請參閱 job_task_run_timeline 數據表。未填入 2024 年 8 月下旬前發出的資料列 |
result_state |
字串 | 作業執行的結果 | 如需可能的值,請參閱 結果狀態值 |
termination_code |
字串 | 作業執行的終止碼 | 如需可能的值,請參閱 終止碼值。 在 2024 年 8 月下旬之前發出的列未進行填充。 |
job_parameters |
map | 作業執行中使用的作業層級參數 | 此欄位中不包含已棄用 notebook_params 設定。 未針對 2024 年 8 月下旬之前發出的行填入資料 |
範例查詢
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name={run_name}
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
作業工作執行時程表數據表架構
作業工作執行時程表數據表在產生時是不可變且完成的。
資料表路徑: system.lakeflow.job_task_run_timeline
| 資料行名稱 | 資料類型 | 描述 | 筆記 |
|---|---|---|---|
account_id |
字串 | 這個工作所屬帳戶的ID | |
workspace_id |
字串 | 此作業所屬工作區的標識碼 | |
job_id |
字串 | 工作的編號 | 僅在單一工作區內是唯一的 |
run_id |
字串 | 工作執行的標識碼 | |
job_run_id |
字串 | 作業執行的識別碼 | 未針對 2024 年 8 月下旬之前發出的數據列填入 |
parent_run_id |
字串 | 親執行的識別碼 | 未針對 2024 年 8 月下旬之前發出的行進行填充。 |
period_start_time |
timestamp | 任務的開始時間或時間週期 | 時區資訊會記錄在值結尾,+00:00 代表UTC |
period_end_time |
timestamp | 任務的結束時間,或時間週期的結束時間 | 時區資訊會記錄在值結尾,+00:00 代表UTC |
task_key |
字串 | 工作中任務的參考鍵 | 此金鑰在單一作業中是唯一的 |
compute_ids |
陣列 | compute_ids陣列包含作業工作所使用的作業叢集、互動式叢集和SQL倉儲標識碼 | |
result_state |
字串 | 作業工作執行的結果 | 如需可能的值,請參閱 結果狀態值 |
termination_code |
字串 | 工作執行的終止碼 | 如需可能的值,請參閱 終止碼值。 未填入 2024 年 8 月下旬之前發出的資料列 |
常見的聯結模式
下列各節提供範例查詢,說明常用於作業系統表的聯結模式。
合併工作和任務運行時間線資料表
豐富作業運行資訊,加入作業名稱
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
使用作業名稱擴充使用量
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
usage.*,
coalesce(usage_metadata.job_name, jobs.name) as job_name
FROM system.billing.usage
LEFT JOIN jobs ON usage.workspace_id=jobs.workspace_id AND usage.usage_metadata.job_id=jobs.job_id
WHERE
billing_origin_product="JOBS"
合併工作運行時間線和使用情況表
使用作業運行元數據豐富每個計費日誌
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
計算每個作業執行的成本
此查詢會與 billing.usage 系統數據表聯結,以計算每個作業執行的成本。
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
合併工作任務運行時間線和叢集表格
使用叢集元數據執行擴充作業工作
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
尋找在所有用途計算上執行的作業
此查詢會與 compute.clusters 系統數據表聯結,以傳回在所有用途計算上執行的最近作業,而不是作業計算。
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
作業監視儀錶板
下列儀錶板會使用系統數據表來協助您開始監視作業和作業健康情況。 其中包含常見的使用案例,例如作業效能追蹤、失敗監視和資源使用率。
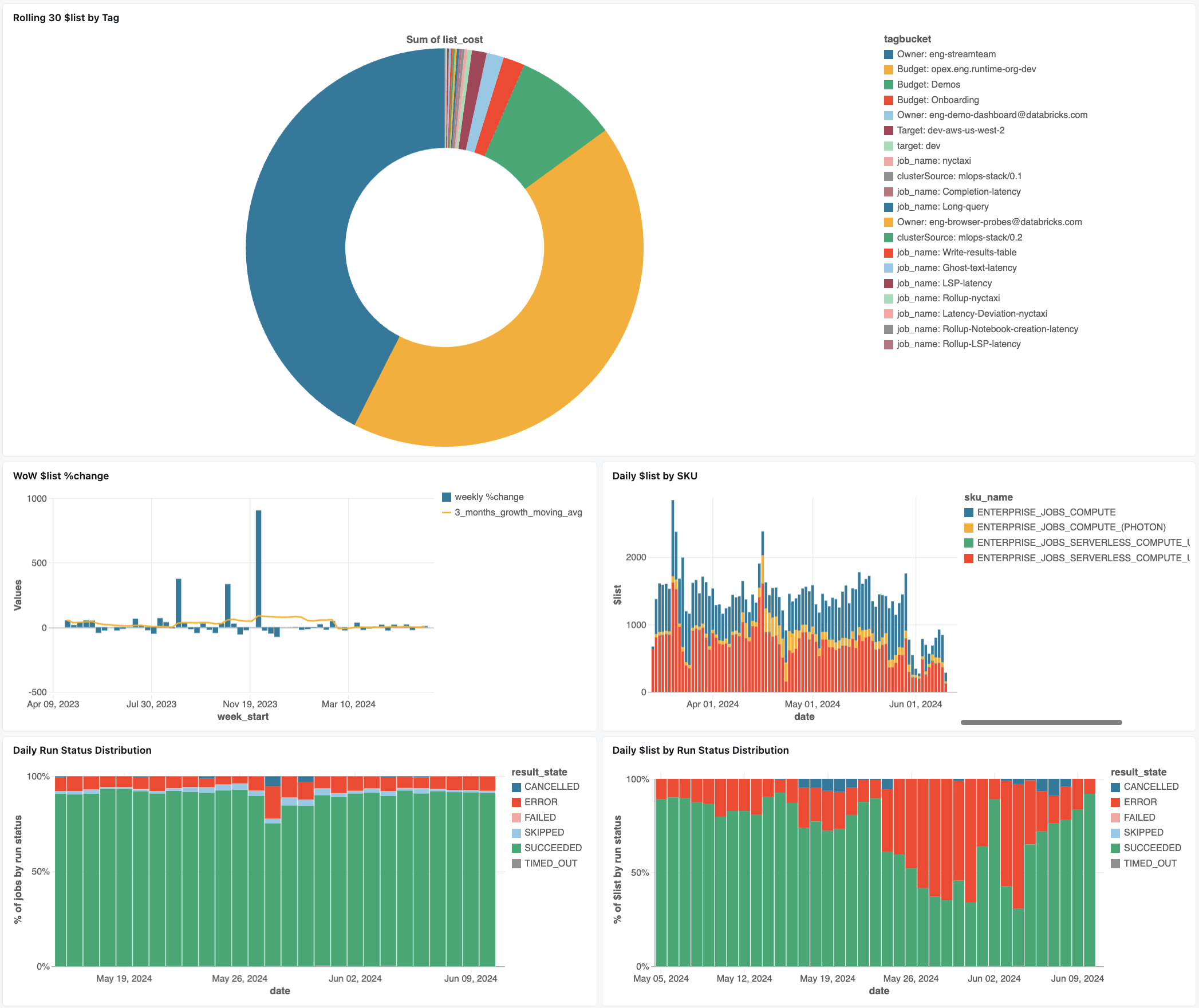
如需下載儀錶板的相關信息,請參閱 使用系統數據表監視作業成本 & 效能。
故障排除
作業未記錄在 lakeflow.jobs 數據表中
如果在系統資料表中無法看到工作:
- 在過去 365 天內,這份工作未被修改
- 職位是在不同的地區創建的
- 最近的就業創造(資料表延遲)
找不到在 job_run_timeline 數據表中看到的工作
並非所有作業執行都會在任何地方顯示。 雖然 JOB_RUN 項目出現在所有作業相關的數據表中,WORKFLOW_RUN(筆記本工作流程執行)和 SUBMIT_RUN(一次性提交的執行)只會記錄在 job_run_timeline 數據表中。 這些執行的項目不會填入其他作業系統資料表,例如 jobs 或 job_tasks。
如需查看每個執行類型的可見性與可存取性詳細明細,請參閱下表執行類型。
作業執行在 billing.usage 表格中看不到
在 system.billing.usage中,只會針對在作業計算或無伺服器計算上執行的作業填入 usage_metadata.job_id。
此外,WORKFLOW_RUN 作業在 system.billing.usage中沒有自己的 usage_metadata.job_id 或 usage_metadata.job_run_id 屬性。
相反地,其計算使用量會歸屬於觸發它們的父筆記本。
這表示當筆記本啟動工作流程執行時,所有計算資源成本都會顯示在父筆記本的使用量中,而不是作為個別的工作流程作業。
如需詳細資訊,請參閱 分析使用量元數據。
計算在全用途計算上執行之作業的成本
針對在目的計算上執行之作業的精確成本計算,無法達到 100% 精確度。 當作業在互動式(所有用途)計算上執行時,筆記本、SQL 查詢或其他作業等多個工作負載通常會在同一個計算資源上同時執行。 因為叢集資源是共用的,因此計算成本和個別作業執行之間沒有直接的 1:1 對應。
為了精確追蹤作業成本,Databricks 建議在專用作業計算或無伺服器計算上執行作業,在此環境中,usage_metadata.job_id 和 usage_metadata.job_run_id 使成本分配更為精確。
如果您必須使用通用計算,您可以:
- 根據
usage_metadata.cluster_id監視system.billing.usage的整體叢集使用量和成本。 - 分別追蹤作業執行時間的指標。
- 請考慮任何成本估計值都會因為共享資源而近似。
如需成本屬性的詳細資訊,請參閱 分析使用量元數據。
參考值
下一節包含工作相關表格中選定欄位的參考資料。
觸發程式類型值
資料列的可能值為 trigger_type :
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
執行類型值
資料列的可能值為 run_type :
| 類型 | 描述 | UI 位置 | API 端點 | 系統數據表 |
|---|---|---|---|---|
JOB_RUN |
標準作業執行 | 任務 & 任務執行介面 | /jobs 和 /jobs/runs endpoints | jobs、job_tasks、job_run_timeline、job_task_run_timeline |
SUBMIT_RUN |
透過 POST /jobs/runs/submit 進行一次性執行 | 僅限作業執行UI | 僅限於 /jobs/runs 的端點 | 工作執行時間線 |
WORKFLOW_RUN |
執行已從 Notebook 工作流程 開始. | 不可見 | 無法存取 | 工作運行時間線 |
結果狀態值
資料列的可能值為 result_state :
| 州 | 描述 |
|---|---|
SUCCEEDED |
執行成功完成 |
FAILED |
執行已完成,並出現錯誤 |
SKIPPED |
執行從未執行,因為不符合條件 |
CANCELLED |
已根據使用者的要求取消運行 |
TIMED_OUT |
到達超時之後,運行已停止 |
ERROR |
執行已完成,並出現錯誤 |
BLOCKED |
在上游依賴項被封鎖運行 |
終止碼值
資料列的可能值為 termination_code :
| 終止碼 | 描述 |
|---|---|
SUCCESS |
執行程式已順利完成 |
CANCELLED |
Databricks 平台在執行期間已取消執行;例如,如果超過執行持續時間上限 |
SKIPPED |
執行程序從未執行過,例如,若上游任務失敗,或不符合相依類型的條件,或沒有具體的任務需要執行。 |
DRIVER_ERROR |
執行與 Spark 驅動程式通訊時發生錯誤 |
CLUSTER_ERROR |
執行失敗,因為叢集錯誤 |
REPOSITORY_CHECKOUT_FAILED |
無法完成簽出,因為與第三方服務通訊時發生錯誤 |
INVALID_CLUSTER_REQUEST |
執行失敗,因為它發出了啟動叢集的無效要求 |
WORKSPACE_RUN_LIMIT_EXCEEDED |
工作區已達到同時進行的活動運行數量上限的配額。 請考慮在較長的時段內規劃執行 |
FEATURE_DISABLED |
執行失敗,因為它嘗試存取工作區無法使用的功能 |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
叢集建立、啟動和向上調整要求的數目已超過分配的速率限制。 請考慮將執行過程分散在較長的時間範圍內 |
STORAGE_ACCESS_ERROR |
執行失敗,因為存取客戶 Blob 記憶體時發生錯誤 |
RUN_EXECUTION_ERROR |
執行已完成,但有一些任務失敗。 |
UNAUTHORIZED_ERROR |
執行失敗,因為存取資源時發生許可權問題 |
LIBRARY_INSTALLATION_ERROR |
安裝使用者要求的程式庫時,執行失敗。 原因可能包括,但不限於:提供的連結庫無效、安裝連結庫的許可權不足等等 |
MAX_CONCURRENT_RUNS_EXCEEDED |
排程的執行超過為作業設定的最大並行執行限制 |
MAX_SPARK_CONTEXTS_EXCEEDED |
該執行被排程在已到達設定的上下文數目上限的叢集上。 |
RESOURCE_NOT_FOUND |
執行所需的資源不存在 |
INVALID_RUN_CONFIGURATION |
執行失敗,因為設定無效 |
CLOUD_FAILURE |
執行失敗,因為雲端提供者問題 |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
因為達到作業層級佇列大小限制,所以已略過執行 |