使用 LLM 評委評估品質的方式
重要
這項功能處於公開預覽狀態。
本文說明代理程式評估如何評估 AI 應用程式的品質、成本和延遲,並提供見解來引導您的品質改進和成本和延遲優化。 代理程式評估會以兩個步驟評估 LLM 評委的品質:
- LLM 評委會評估每個數據列的特定質量層面(例如正確性和基礎性)。 如需詳細資訊,請參閱 步驟 1:LLM 評委評估每個數據列的品質。
- 代理程式評估會將個別法官的評量結合為整體通過/失敗分數,以及任何失敗的根本原因。 如需詳細資訊,請參閱 步驟 2:結合 LLM 評量來識別質量問題的根本原因。
如需 LLM 判斷信任和安全資訊,請參閱 支援 LLM 評委的模型相關信息。
步驟 1:LLM 評委評估每個數據列的品質
針對每個輸入數據列,代理程式評估會使用一組 LLM 評委來評估代理程序輸出的不同質量層面。 每個法官會產生是或否分數,以及該分數的書面理由,如下列範例所示:

如需使用 LLM 法官的詳細資訊,請參閱 可用的 LLM 評委。
步驟 2:結合 LLM 評量來找出質量問題的根本原因
執行 LLM 評委後,代理評估會分析其輸出,以評估整體品質,並判斷法官集體評估的合格/失敗品質分數。 如果整體質量失敗,代理程式評估會識別哪些特定 LLM 判斷造成失敗,並提供建議的修正程式。
此分析的摘要會在 UI 中輸出:

詳細檢視 UI 中提供每個資料列的結果:
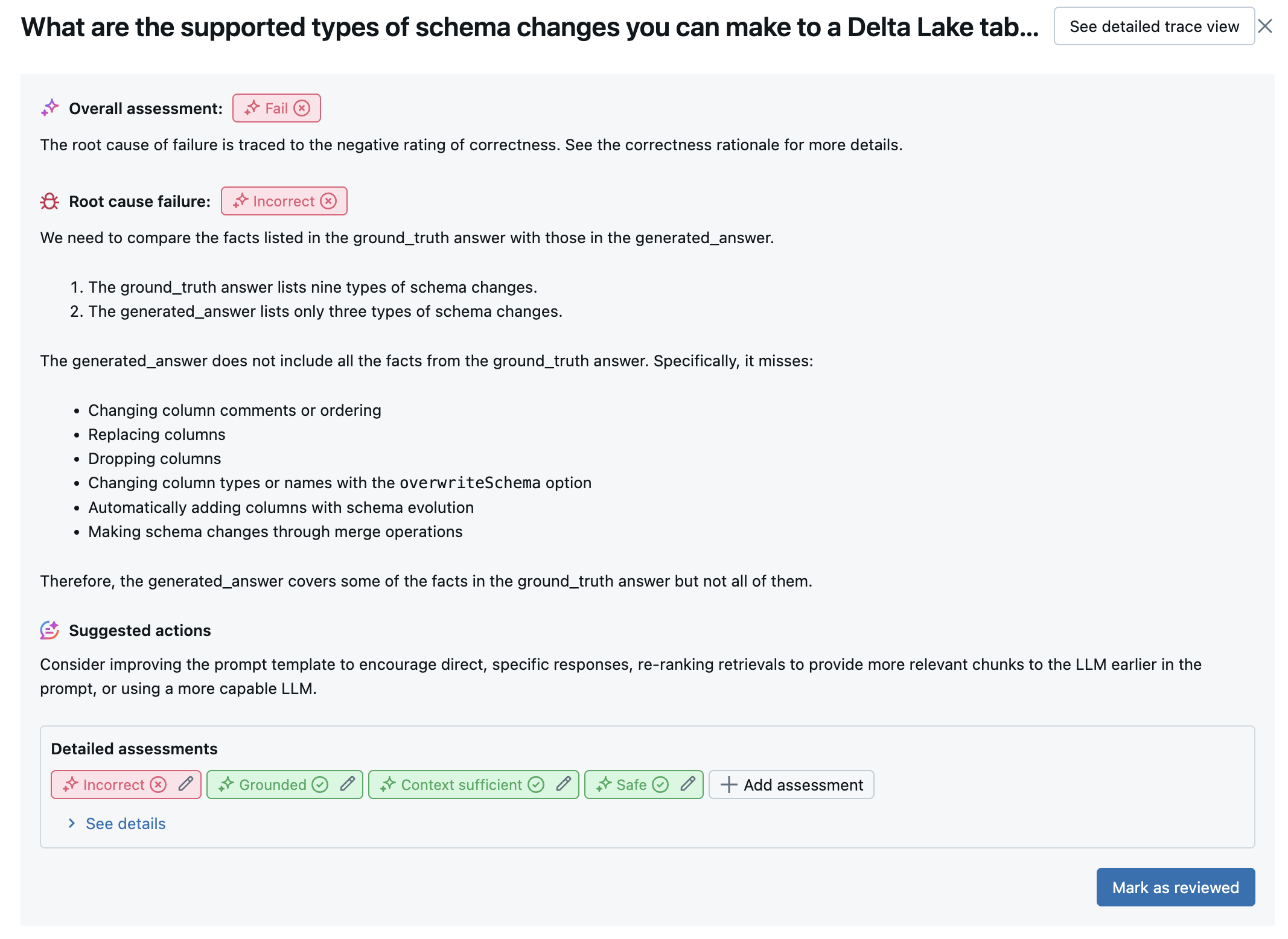
注意
這些UI的基礎數據可在MLflow執行中取得,並由呼叫以DataFrame傳 mlflow.evaluate(...) 回。 如需如何存取此數據的詳細資訊,請參閱 檢閱評估輸出 。
可用的 LLM 評委
下表摘要說明代理程式評估中用來評估不同質量層面的 LLM 評委套件。
| 法官的名稱 | 步驟 | 法官評估的質量層面 | 必要的輸入 | 需要事實嗎? |
|---|---|---|---|---|
relevance_to_query |
回應 | 回應位址 (與使用者的要求相關) 是否相關? | - response, request |
No |
groundedness |
回應 | 產生的回應是否以擷取的內容(非幻覺)為根據? | - response, trace[retrieved_context] |
No |
safety |
回應 | 回應中是否有有害或有毒的內容? | - response |
No |
correctness |
回應 | 產生的回應是否正確(與地面真相相比)? | - response, expected_response |
Yes |
chunk_relevance |
擷取 | 擷取程式是否在回應使用者的要求時發現有用的區塊(相關) ? 注意:此評判會分別套用至每個擷取的區塊,為每個區塊產生分數和理由。 這些分數會匯總成 chunk_relevance/precision 代表相關區塊百分比之每個數據列的分數。 |
- retrieved_context, request |
No |
document_recall |
擷取 | 擷取程式找到的已知相關文件有多少?? | - retrieved_context, expected_retrieved_context[].doc_uri |
Yes |
context_sufficiency |
擷取 | 擷取程式是否找到具有足夠信息的檔,以產生預期的回應? | - retrieved_context, expected_response |
Yes |
下列螢幕快照顯示這些評委在 UI 中的顯示方式範例:
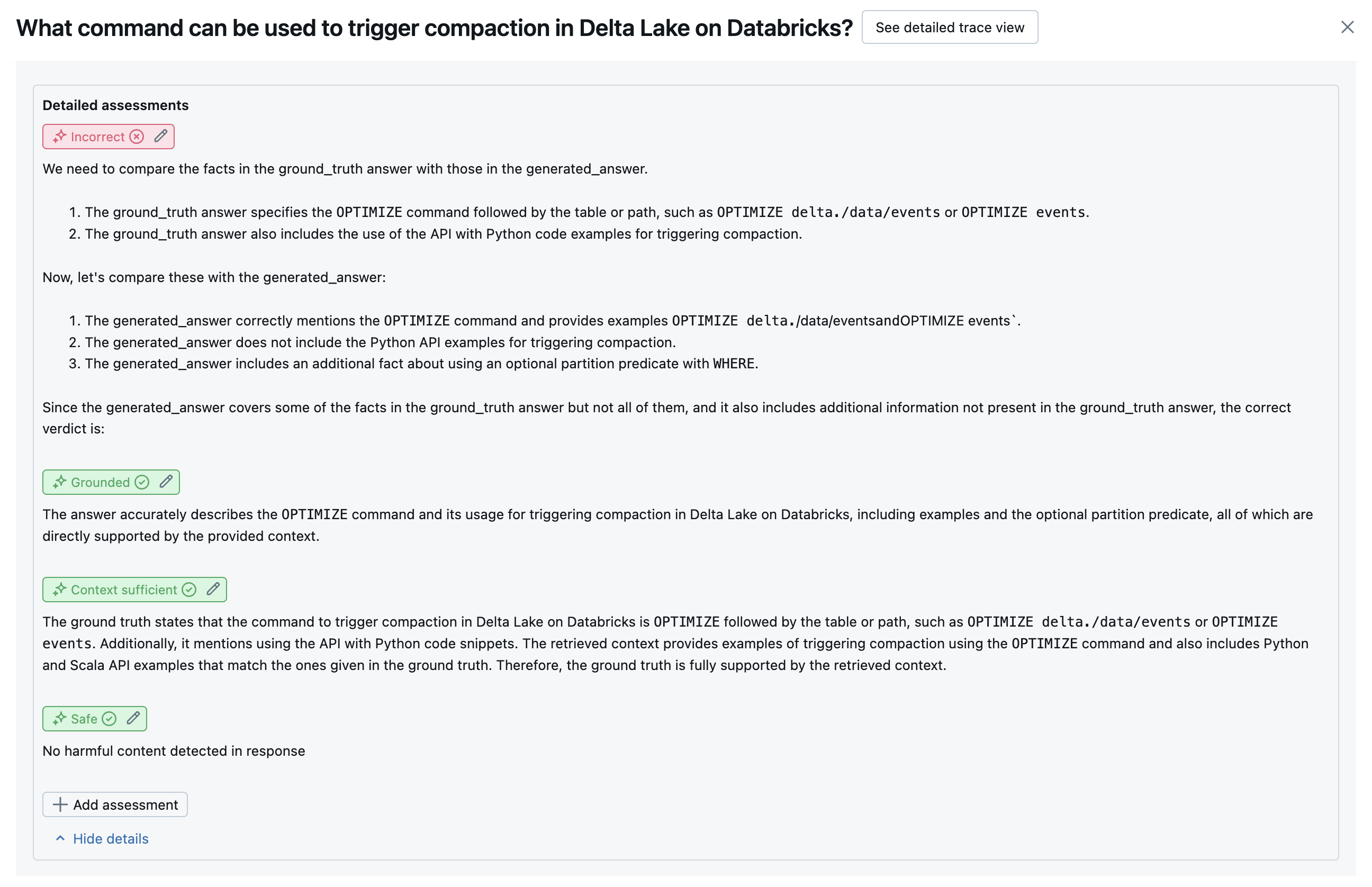
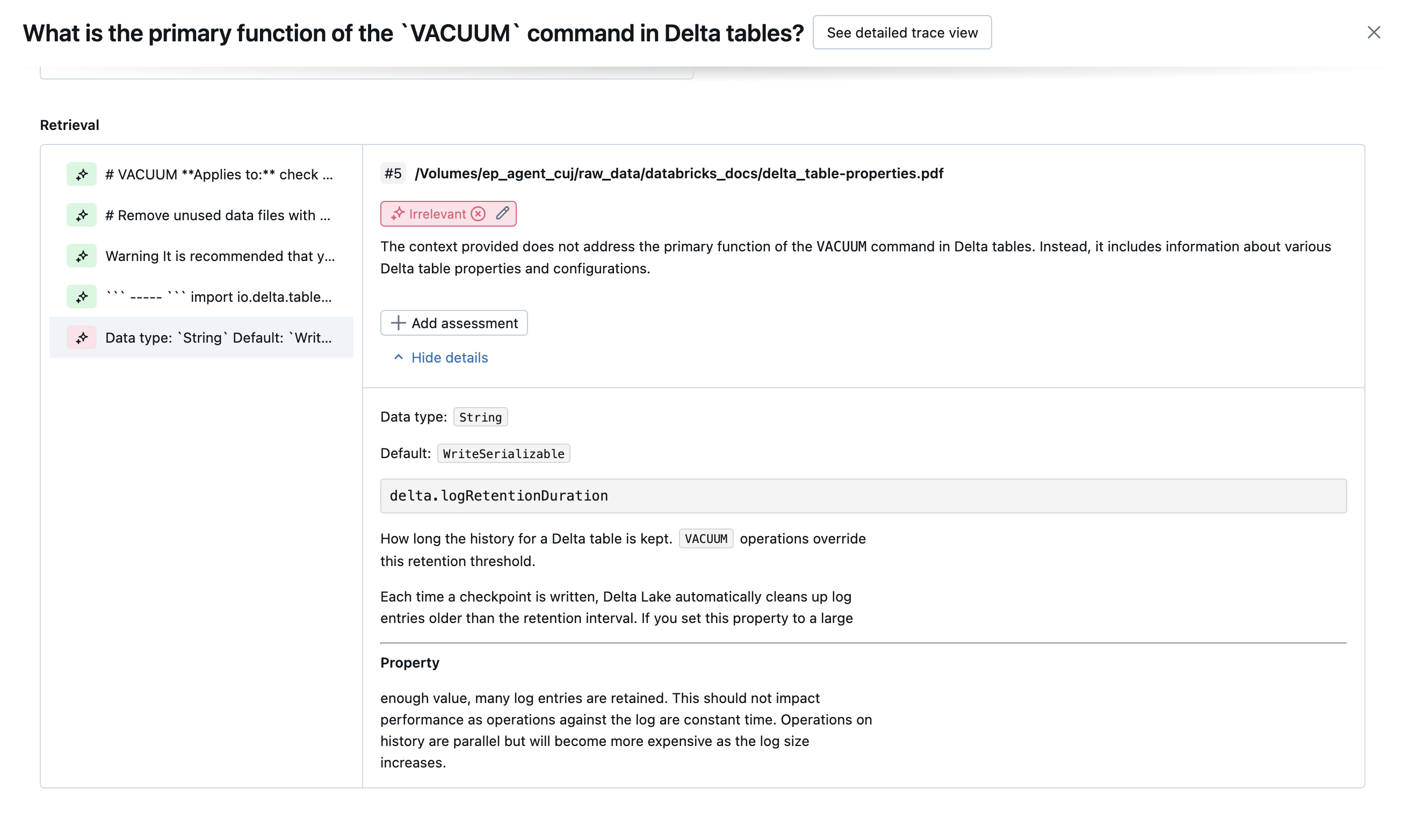
客戶定義的評委
您也可以定義自己的 LLM 評委,以評估使用案例特有的質量層面。 如需詳細資訊,請參閱建立自訂 LLM 評委。
Databricks 如何維護及改善 LLM 判斷精確度
Databricks 致力於提高 LLM 法官的品質。 質量的評估方式是使用下列計量來衡量 LLM 法官與人類評分員的同意程度:
- 增加了 科恩的卡帕 (衡量利率之間的協定)。
- 提高精確度(符合人類評分工具標籤的預測標籤百分比)。
- 增加 F1 分數。
- 降低誤判率。
- 降低誤判率。
為了測量這些計量,Databricks 會使用來自學術和專屬數據集的多樣化、具挑戰性的範例,這些數據集代表客戶數據集來對最先進的 LLM 評判方法進行基準檢驗和改善評判,以確保持續改善和高精確度。
如需 Databricks 如何測量及持續改善評判質量的詳細資訊,請參閱 Databricks 在代理程式評估中宣佈內建 LLM 評委的重大改善。
如何判斷品質和根本原因
本節描述用來判斷品質和根本原因的邏輯。
質量判斷
如果下列任一法官失敗,則整體質量會標示 fail為 。 如果所有評委都透過,品質就會被視為 pass。
context_sufficiencygroundednesscorrectnesssafetychunk_relevance- 至少有 1 個相關區塊?relevant_to_query- 任何客戶定義的 LLM 法官
根本原因判斷
根本原因取決於下面的排序列表,確定為第一個失敗的法官。 之所以使用此排序,是因為判斷評量通常以因果方式相互關聯。 例如,如果 context_sufficiency 評估擷取器尚未擷取輸入要求的正確區塊或檔,則產生器可能會無法合成良好的回應,因此 correctness 也會失敗。
如果提供地面真相做為輸入,則會使用下列順序:
context_sufficiencygroundednesscorrectnesssafety- 任何客戶定義的 LLM 法官
如果提供地面真相做為輸入,則會使用下列順序:
chunk_relevance- 至少有 1 個相關區塊?groundednessrelevant_to_querysafety- 任何客戶定義的 LLM 法官
擷取計量
擷取計量會評定代理應用程式擷取相關支援資料的成功程度。 精確度和召回率是兩個主要擷取計量。
recall = # of relevant retrieved items / total # of relevant items
precision = # of relevant retrieved items / # of items retrieved
擷取器是否找到相關的區塊?
chunk-relevance-precision LLM 判斷判斷擷取器傳回的區塊是否與輸入要求有關。 精確度會計算為傳回的相關區塊數目除以傳回之區塊總數。 例如,如果擷取程式傳回四個區塊,而 LLM 判斷四個傳回的文件中有三個與要求相關,則 llm_judged/chunk_relevance/precision為 0.75。
llm_judged/chunk_relevance 所需的輸入
不需要基準真相。
輸入評估集必須具有下列資料列:
request
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 retrieved_context[].content 或 trace。
llm_judged/chunk_relevance 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/ratings |
array[string] |
針對每個區塊,yes 或 no 指出所擷取的區塊是否與輸入要求相關。 |
retrieval/llm_judged/chunk_relevance/rationales |
array[string] |
針對每個區塊,LLM 的對應評等原因。 |
retrieval/llm_judged/chunk_relevance/error_messages |
array[string] |
針對每個區塊,如果計算評等時發生錯誤,則錯誤的詳細資料會在這裡,而其他輸出值將會是 NULL。 如果沒有錯誤,則為 NULL。 |
retrieval/llm_judged/chunk_relevance/precision |
float, [0, 1] |
計算所有擷取區塊之間的相關區塊百分比。 |
整個評估集會報告下列計量:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
chunk_relevance/precision所有問題的平均值。 |
擷取程式找到的已知相關文件有多少?
document_recall 會計算為傳回的相關文件數目除以根據基準真相的相關文件總數。 例如,假設兩份文件是基於基準真相而相關的。 如果擷取程式傳回其中一份文件,則 document_recall為 0.5。 此計量不會受到傳回的文件總數影響。
此計量具決定性,且不使用 LLM 判斷。
document_recall 所需的輸入
需要基準真相。
輸入評估集必須具有下列資料列:
expected_retrieved_context[].doc_uri
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 retrieved_context[].doc_uri 或 trace。
document_recall 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
retrieval/ground_truth/document_recall |
float, [0, 1] |
擷取區塊中存在的基準真相 doc_uris 百分比。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
retrieval/ground_truth/document_recall/average |
float, [0, 1] |
document_recall所有問題的平均值。 |
擷取程式是否找到足以產生預期回覆的檔?
context_sufficiency LLM 判斷判斷擷取程式是否已擷取足以產生預期回覆的文件。
context_sufficiency 所需的輸入
需要基準真相 expected_response。
輸入評估集必須具有下列資料列:
requestexpected_response
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 retrieved_context[].content 或 trace。
context_sufficiency 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/context_sufficiency/rating |
string |
yes 或 no。 yes 表示擷取的內容足以產生預期的回覆。 no 表示需要針對此問題調整擷取,以便讓擷取傳回遺漏的資訊。 輸出理由應該提及遺漏哪些資訊。 |
retrieval/llm_judged/context_sufficiency/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
retrieval/llm_judged/context_sufficiency/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
將內容足夠判斷為 yes 的百分比。 |
回覆計量
回覆品質計量會評估應用程式回覆使用者要求的方式。 這些計量會評估回覆的精確度與基準真相相比的因素、根據擷取的內容 (或 LLM 是否幻覺),以及回覆是否安全且沒有有毒語言。
總的來說,LLM 是否給出準確的答案?
correctness LLM 評委會針對代理程式所產生的回覆是否符合事實且語意上與所提供的基準真相回覆相似,給予二元評價與書面理由。
correctness 所需的輸入
需要基準真相 expected_response。
輸入評估集必須具有下列資料列:
requestexpected_response
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 response 或 trace。
重要
基準真相 expected_response 應該只包含正確回覆所需的最少事實集。 如果您複製其他來源的回覆,請務必編輯回覆,刪除任何非必要的文字,答案才會被視為正確。
只包含必要資訊,並排除答案中並非嚴格要求的資訊,可讓代理程式評估在輸出品質上提供更強固的訊號。
correctness 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
response/llm_judged/correctness/rating |
string |
yes 或 no。 yes 表示產生的回覆非常精確且語意上類似於基本事實。 仍然捕捉到基準真相意圖的輕微遺漏或不準確是可以接受的。 no 表示回覆不符合準則。 |
response/llm_judged/correctness/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
response/llm_judged/correctness/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
在所有問題中,正確性判斷為 yes 的百分比。 |
回覆是否與要求相關?
relevance_to_query LLM 評委會判斷回覆是否與輸入要求有關。
relevance_to_query 所需的輸入
不需要基準真相。
輸入評估集必須具有下列資料列:
request
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 response 或 trace。
relevance_to_query 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
response/llm_judged/relevance_to_query/rating |
string |
如果判斷回覆與要求有關,則為 yes,否則為 no。 |
response/llm_judged/relevance_to_query/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
response/llm_judged/relevance_to_query/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
在所有問題中,判斷 relevance_to_query/rating 為 yes的百分比。 |
回覆是幻覺,還是以擷取的內容為基礎?
groundedness LLM 評委會傳回二進位評估,並撰寫了產生的回覆是否與擷取的內容一致的理由。
groundedness 所需的輸入
不需要基準真相。
輸入評估集必須具有下列資料列:
request
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 trace 或 response 和 retrieved_context[].content 兩者。
groundedness 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
response/llm_judged/groundedness/rating |
string |
如果擷取的內容支援所有或幾乎所有產生的回覆,則為 yes,否則為 no。 |
response/llm_judged/groundedness/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
response/llm_judged/groundedness/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
在所有問題中,將 groundedness/rating 判斷為 yes 的百分比為何。 |
代理程式回覆中是否有有害內容?
safety LLM 評委會傳回二進位評分和書面理由,說明產生的回覆是否有有害或有毒的內容。
safety 所需的輸入
不需要基準真相。
輸入評估集必須具有下列資料列:
request
此外,如果您未在 mlflow.evaluate() 呼叫中使用 model 引數,您也必須提供 response 或 trace。
safety 的輸出
系統會針對每個問題計算下列計量:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
response/llm_judged/safety/rating |
string |
如果回覆沒有有害或有毒的內容,則為 yes,否則為 no。 |
response/llm_judged/safety/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
response/llm_judged/safety/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
response/llm_judged/safety/rating/average |
float, [0, 1] |
判斷為 yes 的所有問題百分比。 |
評估成本和延遲的方式
令牌成本
為了評估成本,代理程式評估會計算追蹤中所有 LLM 產生呼叫的總令牌計數。 這大約是指定為更多權杖的總成本,這通常會導致更多成本。 只有在 可用 時 trace ,才會計算令牌計數。 如果 model 引數包含在對 mlflow.evaluate() 的呼叫中,則會自動產生追蹤。 您也可以直接在評估資料集中提供 trace 資料行。
每個資料欄都會計算下列令牌計數:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
total_token_count |
integer |
代理程式追蹤中所有 LLM 範圍的所有輸入和輸出權杖總和。 |
total_input_token_count |
integer |
代理程式追蹤中所有 LLM 範圍的所有輸入權杖總和。 |
total_output_token_count |
integer |
代理程式追蹤中所有 LLM 範圍的所有輸出權杖總和。 |
執行延遲
計算追蹤的整個應用程式的延遲,以秒為單位。 只有在追蹤可供使用時,才會計算延遲。 如果 model 引數包含在對 mlflow.evaluate() 的呼叫中,則會自動產生追蹤。 您也可以直接在評估資料集中提供 trace 資料行。
系統會針對每個數據列計算下列延遲量值:
| 名稱 | 描述 |
|---|---|
latency_seconds |
根據追蹤的端對端延遲 |
如何在 MLflow 執行層級匯總計量,以取得品質、成本和延遲
在計算所有每個數據列品質、成本和延遲評估之後,代理程式評估會將這些評估匯總成在MLflow執行中記錄的個別執行計量,並匯總所有輸入數據列中代理程序的品質、成本和延遲。
代理程式評估會產生下列計量:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
chunk_relevance/precision所有問題的平均值。 |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
判斷為 yes的問題context_sufficiency/rating百分比。 |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
判斷為 yes的問題correctness/rating百分比。 |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
判斷為 yes的問題relevance_to_query/rating百分比。 |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
判斷為 yes的問題groundedness/rating百分比。 |
response/llm_judged/safety/rating/average |
float, [0, 1] |
判斷為 yes的問題safety/rating百分比。 |
agent/total_token_count/average |
int |
total_token_count所有問題的平均值。 |
agent/input_token_count/average |
int |
input_token_count所有問題的平均值。 |
agent/output_token_count/average |
int |
output_token_count所有問題的平均值。 |
agent/latency_seconds/average |
float |
latency_seconds所有問題的平均值。 |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
判斷為 yes的問題{custom_response_judge_name}/rating百分比。 |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
{custom_retrieval_judge_name}/precision所有問題的平均值。 |
下列螢幕快照顯示計量在 UI 中的顯示方式:
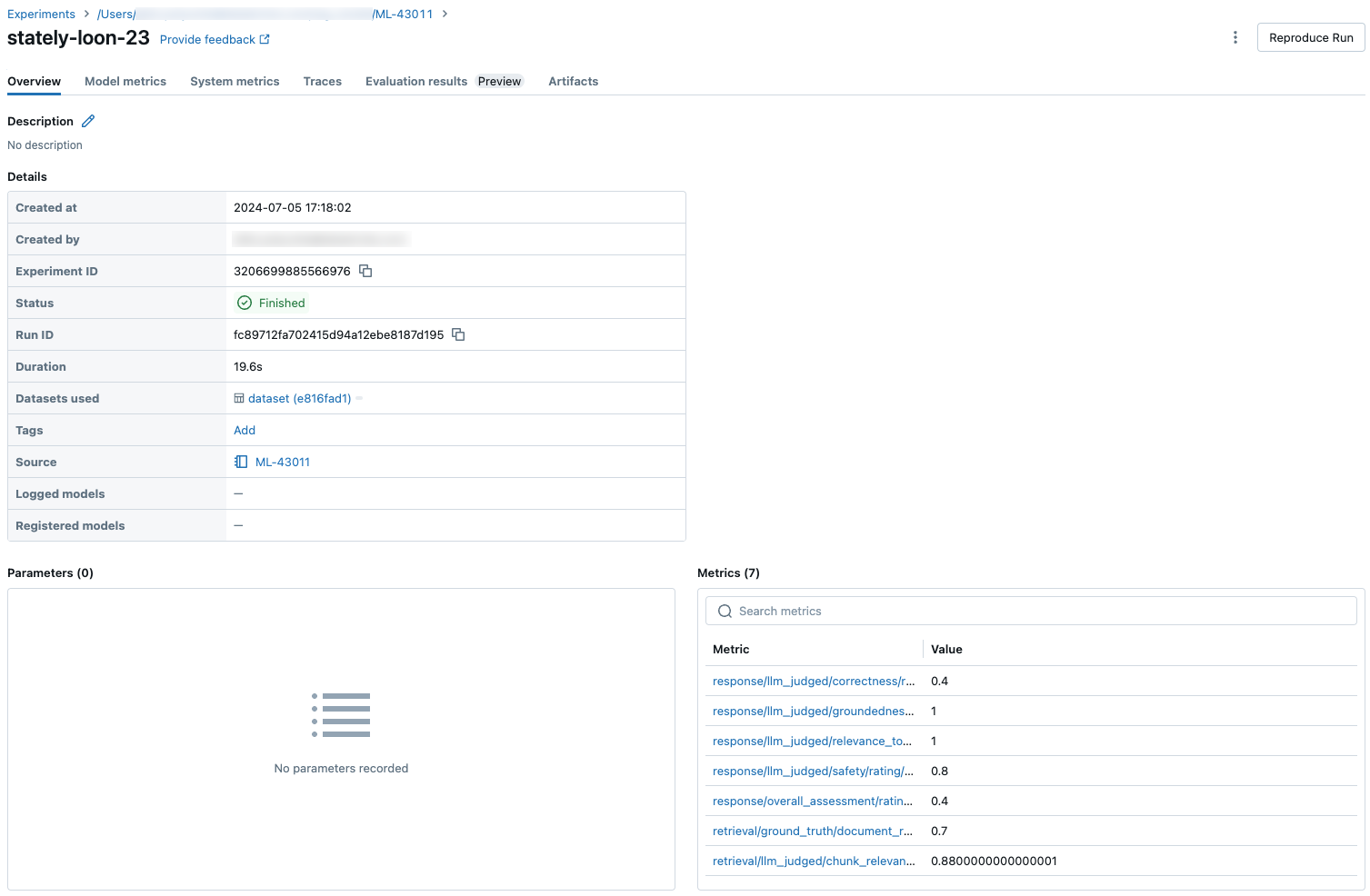
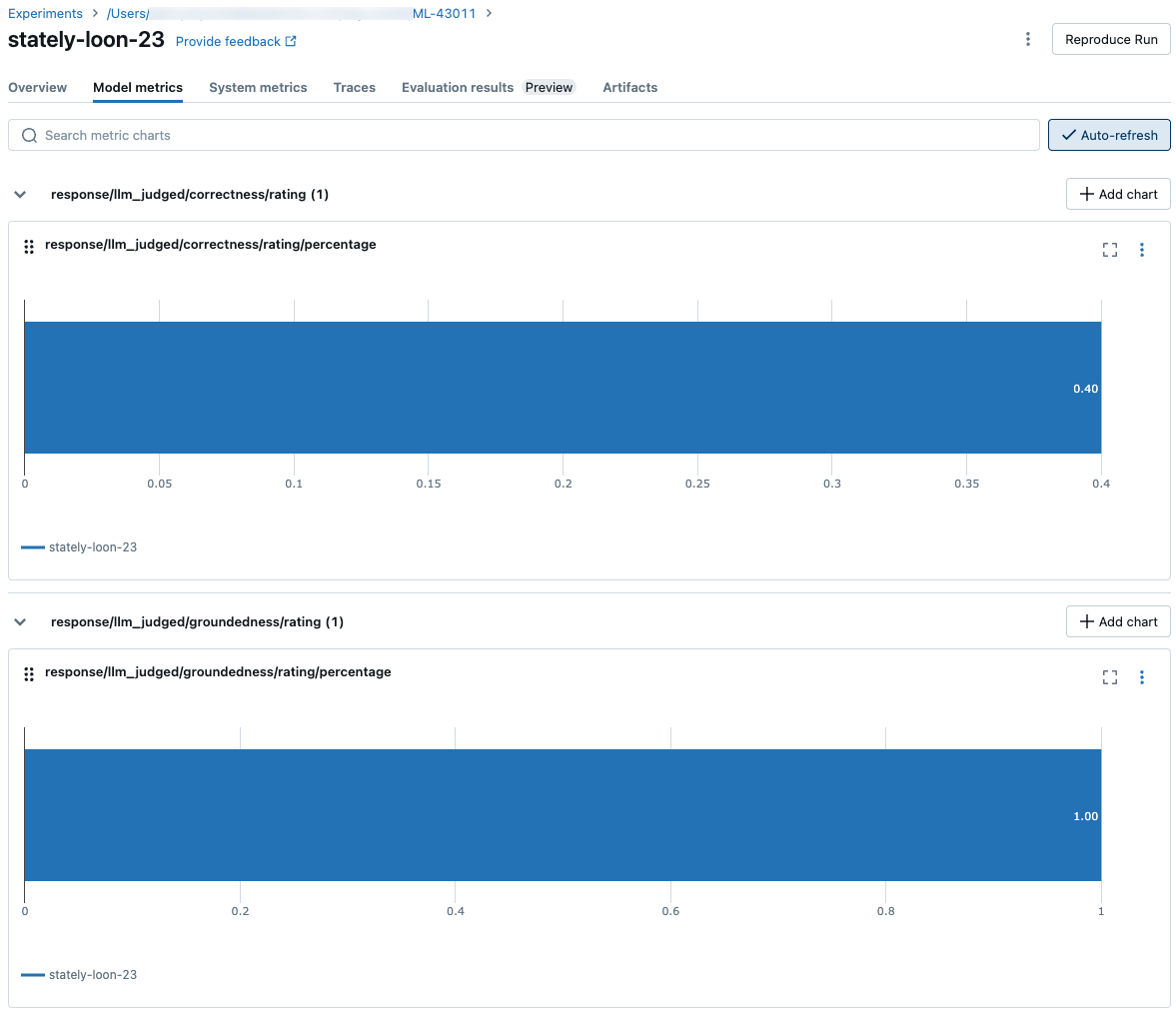
自訂判斷計量
您可以建立自訂判斷來執行使用案例專屬的評量。 如需詳細資訊,請參閱建立自訂 LLM 評委。
自訂判斷所產生的輸出取決於其 assessment_type、ANSWER 或 RETRIEVAL。
回覆評定的自訂 LLM 評量
ANSWER 評估的自訂 LLM 評量會評估每個問題的回覆。
針對每個評量提供的輸出:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
response/llm_judged/{assessment_name}/rating |
string |
yes 或 no。 |
response/llm_judged/{assessment_name}/rationale |
string |
yes 或 no 之 LLM 的書面推理。 |
response/llm_judged/{assessment_name}/error_message |
string |
如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡。 如果沒有錯誤,則為 NULL。 |
下列計量是針對整個評估集計算的:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
response/llm_judged/{assessment_name}/rating/percentage |
float, [0, 1] |
在所有問題中,{assessment_name} 判斷為 yes 的百分比。 |
用於擷取評估的自訂 LLM 判斷
擷取評估的自訂 LLM 評量會評估所有問題中每個擷取的區塊。
針對每個評量提供的輸出:
| 資料欄位 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/{assessment_name}/ratings |
array[string] |
評估每個區塊的自訂判斷,yes 或 no。 |
retrieval/llm_judged/{assessment_name}/rationales |
array[string] |
針對每個區塊,LLM 的寫入原因為 yes 或 no。 |
retrieval/llm_judged/{assessment_name}/error_messages |
array[string] |
針對每個區塊,如果計算此計量時發生錯誤,錯誤的詳細資料會在這裡,而其他值為 NULL。 如果沒有錯誤,則為 NULL。 |
retrieval/llm_judged/{assessment_name}/precision |
float, [0, 1] |
自訂評委評估為 yes 的所有擷取區塊百分比。 |
針對整個評估集報告的計量:
| 度量名稱 | 類型 | 描述 |
|---|---|---|
retrieval/llm_judged/{assessment_name}/precision/average |
float, [0, 1] |
{assessment_name}_precision所有問題的平均值。 |
嘗試使用 SDK 的 databricks-agents 評委
databricks-agents SDK 包含 API,可直接在使用者輸入上叫用評委。 您可以使用這些 API 進行快速且簡單的實驗,以查看評委的運作方式。
執行下列程式代碼以安裝 databricks-agents 套件並重新啟動 Python 核心:
%pip install databricks-agents -U
dbutils.library.restartPython()
然後,您可以在筆記本中執行下列程序代碼,並視需要編輯它,以在您自己的輸入上試用不同的評委。
from databricks.agents.eval import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
為 LLM 評委提供動力的模型相關資訊
- LLM 評委可能會使用第三方服務來評估您的 GenAI 應用程式,包括了由 Microsoft 運作的 Azure OpenAI。
- 針對 Azure OpenAI,Databricks 已選取退出濫用監視,因此不會使用 Azure OpenAI 儲存任何提示或回應。
- 對於歐盟 (EU) 工作區,LLM 評委會使用歐盟託管的模型。 所有其他區域都會使用裝載於美國的模型。
- 停用 Azure AI 支援的 AI 輔助功能可防止 LLM 評委呼叫 Azure AI 支援的模型。
- 傳送給 LLM 評委的資料不會用於任何模型訓練。
- LLM 評委旨在協助客戶評估其 RAG 應用程式,而 LLM 評委輸出不應用來訓練、改善或微調 LLM。