如何建立和查詢向量搜尋索引
本文說明如何使用馬賽克 AI 向量搜尋 建立及查詢向量搜尋索引。
您可以使用UI、Python SDK,或 REST API來建立和管理向量搜尋元件,例如向量搜尋端點和向量搜尋索引。
要求
- 已啟用 Unity Catalog 工作區。
- 已啟用無伺服器計算。 如需說明,請參閱 連線到無伺服器計算。
- 來源 table 必須已啟用變更資料饋送。 如需指示,請參閱 在 Azure Databricks上使用 Delta Lake 變更數據摘要。
- 若要建立向量搜尋索引,您必須在索引即將建立於 catalogschemawhere 時具有 CREATE TABLE 許可權。
- 若要查詢其他使用者擁有的索引,您必須擁有額外的許可權。 請參閱 查詢向量搜尋端點。
使用訪問控制清單來設定建立和管理向量搜尋端點的許可權。 請參閱 向量搜尋端點的 ACL。
安裝
若要使用向量搜尋 SDK,您必須在筆記本中安裝它。 使用下列代碼:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
認證
請參閱 資料保護和驗證。
建立向量搜尋端點
您可以使用 Databricks UI、Python SDK 或 API 來建立向量搜尋端點。
使用UI建立向量搜尋端點
請遵循下列步驟,使用UI建立向量搜尋端點。
在左側邊欄中,點擊 [計算]。
點選 向量搜尋 標籤,然後點擊 建立。

[建立端點] 表單 隨即開啟。 輸入此端點的名稱。
按一下 確認。
使用 Python SDK 建立向量搜尋端點
下列範例會使用 create_endpoint() SDK 函式來建立向量搜尋端點。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
使用 REST API 建立向量搜尋端點
請參閱 REST API 參考檔:POST /api/2.0/vector-search/endpoints。
(選擇性)建立並設定端點來提供內嵌模型
如果您選擇讓 Databricks 計算內嵌,您可以使用預先設定的基礎模型 API 端點,或建立服務端點的模型來提供您選擇的內嵌模型。 如需指示,請參閱 依令牌付費基礎模型 API 或 建立服務端點的基礎模型。 如需筆記本範例,請參閱 Notebook 範例,以呼叫內嵌模型。
當您設定內嵌端點時,Databricks 建議您保持「縮放至零」的預設選擇 remove,。 服務端點需要幾分鐘才能完成熱身,而縮減的端點上的索引初始查詢可能會逾時。
注意
如果未適當地為數據集設定內嵌端點,向量搜尋索引初始化可能會逾時。 您應該只針對小型資料集和測試使用 CPU 端點。 針對較大的數據集,請使用 GPU 端點以獲得最佳效能。
建立向量搜尋索引
您可以使用UI、Python SDK 或 REST API 來建立向量搜尋索引。 UI 是最簡單的方法。
有兩種類型的索引:
- Delta Sync Index 自動同步到來源 Delta Table,並且隨著 Delta Table 中的基礎數據變化,持續且逐步更新索引。
- 直接向量存取索引 支援向量和元數據的直接讀取和寫入。 用戶須負責使用 REST API 或 Python SDK 更新此 table。 您無法使用 UI 建立這種類型的索引。 您必須使用 REST API 或 SDK。
使用 UI 建立索引
在左側邊欄中,按一下 [Catalog] 以開啟 [Catalog] Explorer UI。
導航至您想要使用的 Delta table。
單擊右上角的 [建立] 按鈕,然後從下拉菜單中選擇 [select向量搜尋索引]。
![[建立索引] 按鈕](../_static/images/generative-ai/create-index-button.png)
使用對話框中的選取器來設定索引。
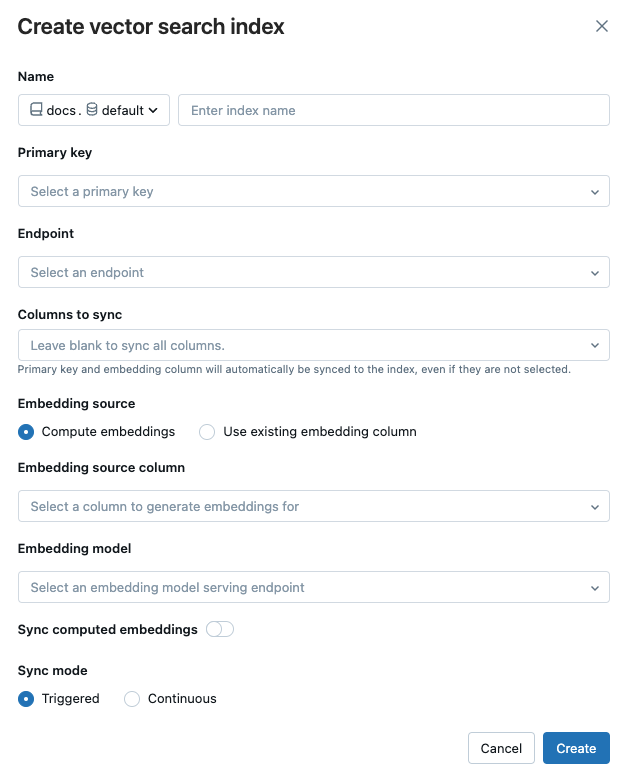
名稱:用於 Unity Catalog中線上 table 的名稱。 名稱需要三層命名空間,
<catalog>.<schema>.<name>。 只允許英文字母、數字和下劃線。主鍵:將 Column 作為主鍵。
端點:Select 您想要使用的向量搜尋端點。
Columns sync :使用向量索引將 Select 從 columns 轉換到 sync。 如果您將此欄位保留空白,來源 table 的所有 columns 都會與索引同步。 主鍵 column 和內嵌來源 column 或內嵌向量 column 一律會同步處理。
嵌入來源:指出您是否希望 Databricks 為 Delta table 中的文本 column 計算嵌入式向量(計算嵌入式向量),或如果您的 Delta table 包含預先計算的嵌入式向量(使用現有的嵌入式向量 column)。
- 如果您選擇了 計算內嵌,並且選擇了您希望進行內嵌計算的 selectcolumn,以及提供內嵌模型服務的端點。 僅支援文字 columns。
- 如果您選取 使用現有的內嵌 column,select 包含預先計算的內嵌和內嵌維度的 column。 預先計算的內嵌 column 格式應該是
array[float]。
Sync 計算出的嵌入向量:切換此設定,將產生的嵌入向量儲存到 Unity Catalogtable。 如需詳細資訊,請參閱 儲存產生的內嵌 table。
Sync 模式:連續 以秒的延遲將索引保持在 sync。 然而,由於一個計算叢集已被配置來執行連續的 sync 串流管線,與之相關的成本因此較高。 針對 連續 和 觸發,update 是增量式處理,僅處理自上次 sync 後變更的數據。
在 觸發的sync 模式下,您可以使用 Python SDK 或 REST API 來啟動 sync。請參閱 Update 中的 Delta Sync Index。
當您完成索引設定後,請點擊 [建立]。
使用 Python SDK 建立索引
下列範例會建立一個由 Databricks 計算的內嵌的 Delta Sync Index。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
下列範例會建立具有自我管理內嵌的 Delta Sync Index。 此範例同時展示了如何僅使用索引中自 columns 中選出的一個子集,並將其用於選擇性參數 columns_to_sync 到 select 的情況。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
根據預設,來源 table 的所有 columns 都會與索引同步。 若要只 synccolumns子集,請使用 columns_to_sync。 主鍵和內嵌 columns 一律包含在索引中。
若要 sync只 主鍵和內嵌 column,您必須在 columns_to_sync 中指定它們,如下所示:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
如要指定額外的 sync 和 columns,請按照如下所示的進行。 您不需要包含主鍵和內嵌 column,因為它們始終保持同步。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
下列範例會建立直接向量存取索引。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
使用 REST API 建立索引
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes。
儲存產生的內嵌 table
如果 Databricks 產生內嵌,您可以將產生的內嵌儲存至 Unity Catalog中的 table。 此 table 建立於與向量索引相同的 schema,並從向量索引頁面進行連結。
table 的名稱是由向量搜尋索引的名稱組成,並附加 _writeback_table。 無法編輯名稱。
您可以像 Unity Catalog中的其他任何 table 一樣存取和查詢 table。 不過,您不應該卸除或修改 table,因為它不適合手動更新。 刪除索引時,會自動刪除 table。
Update 向量搜尋索引
Update 德爾塔 Sync 指數
當來源 Delta table 變更時,使用 連續sync 模式建立的索引會自動 update。 如果您使用 觸發sync 模式,請使用 Python SDK 或 REST API 來啟動 sync。
Python SDK
index.sync()
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes/{index_name}/sync。
Update 直接向量存取索引
您可以使用 Python SDK 或 REST API 來 insert、update,或刪除直接向量存取索引中的數據。
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes。
下列程式碼範例說明如何使用個人存取令牌(PAT)進行update索引。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
下列程式代碼範例說明如何使用服務主體 update 索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
查詢向量搜尋端點
您只能使用 Python SDK、REST API 或 SQL vector_search() AI 函式來查詢向量搜尋端點。
注意
如果查詢端點的使用者不是向量搜尋索引的擁有者,用戶必須具有下列 UC 許可權:
- USE CATALOG 包含向量搜尋索引的 catalog。
- USE SCHEMA 包含向量搜尋索引的 schema。
- 在向量搜尋索引上 SELECT。
若要執行混合式關鍵詞相似性搜尋,set 參數 query_typehybrid。 默認值為 ann (近似近鄰)。
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes/{index_name}/query。
下列程式代碼範例說明如何使用個人存取令牌來查詢索引(PAT)。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
下列程式代碼範例說明如何使用服務主體查詢索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
重要
vector_search() AI 功能目前在 公開預覽中。
若要使用此 AI 函式,請參閱 vector_search 函式。
在查詢上使用篩選
查詢可以根據 Delta table中的任何 column 來定義篩選。
similarity_search 只會傳回符合指定篩選的數據列。 支援下列篩選:
| 篩選運算子 | 行為 | 例子 |
|---|---|---|
NOT |
否定篩選條件。 索引鍵必須以 「NOT」 結尾。 例如,應用“color NOT”條件且值為“red”時,會比對到where這份檔案,其顏色不是紅色。 |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
檢查域值是否小於篩選值。 索引鍵必須以 「<」 結尾。 例如,值為 200 的「價格 <」符合檔案 where 中價格小於 200 的條件。 | {"id <": 200} |
<= |
檢查域值是否小於或等於篩選值。 密鑰的結尾必須是「<=」。 例如,「price <= 200」的條件會符合文件 where,其價格小於或等於 200。 | {"id <=": 200} |
> |
檢查域值是否大於篩選值。 索引鍵必須以 「>」 結尾。 例如,值為 200 的「價格 >」符合條件:在文件 where 中,價格大於 200。 | {"id >": 200} |
>= |
檢查域值是否大於或等於篩選值。 索引鍵的結尾必須是 「>=」。 例如,「price >= 200」的值會匹配價格大於或等於 200 的文件 where。 | {"id >=": 200} |
OR |
檢查欄位值是否符合任何篩選 values。 鍵值必須包含 OR,以分隔多個子鍵。 例如,color1 OR color2 的值為 ["red", "blue"] 時,符合 where 的文件,條件是 color1 的值是 red 或 color2 的值是 blue。 |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
匹配部分字串。 | {"column LIKE": "hello"} |
| 未指定篩選運算子 | 過濾器會檢查是否有完全匹配。 如果指定多個 values,它會符合任何一個 values。 |
{"id": 200}
{"id": [200, 300]}
|
請參閱下列程式代碼範例:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
請參閱 POST /api/2.0/vector-search/indexes/{index_name}/query。
範例筆記本
本節中的範例示範向量搜尋 Python SDK 的使用方式。
LangChain 範例
請參閱 如何將 LangChain 套件與馬賽克 AI 向量搜尋整合使用,以了解如何在 LangChain 套件中整合馬賽克 AI 向量搜尋。
下列筆記本示範如何將相似度搜尋結果轉換成 LangChain 檔。
使用 Python SDK 筆記本進行向量搜尋
Notebook 呼叫嵌入模型的範例
下列筆記本示範如何設定馬賽克 AI 模型服務端點以進行內嵌產生。