使用基礎模型微調 API 建立定型執行
重要
這項功能在下列區域開放公開預覽:centralus、eastus、eastus2、northcentralus 和 westus。
本文說明如何使用基礎模型微調(現在是馬賽克 AI 模型訓練的一部分)API 來建立和設定定型執行,並描述 API 呼叫中使用的所有參數。 您也可以使用 UI 建立回合。 如需指示,請參閱 使用基礎模型微調 UI 建立定型回合。
需求
請參閱 需求。
建立訓練回合
若要以程式設計方式建立訓練回合,請使用 create() 函式。 這個函式會用提供的資料集訓練模型,並將最終的 Composer 檢查點轉換為 Hugging Face 格式化檢查點以供推斷。
您必須輸入想訓練的模型、訓練資料集的位置,以及註冊模型的位置。 也有選擇性參數可讓您執行評估並變更回合的超參數。
回合完成之後會儲存完成的回合和最終檢查點、複製模型,並在 Unity Catalog 將該複製品註冊為供推斷的模型版本。
已完成回合的模型,不是 Unity Catalog 中複製的模型版本,而且其 Composer 和 Hugging Face 檢查點會儲存至 MLflow。 Composer 檢查點可用於持續微調工作。
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
設定訓練回合
下表摘要說明 函式 foundation_model.create() 的參數。
| 參數 | 必要 | 類型 | 描述 |
|---|---|---|---|
model |
x | 字串 | 模型要使用的的名稱。 請參閱支援的模型。 |
train_data_path |
x | 字串 | 訓練資料的位置。 這可以是 Unity Catalog (<catalog>.<schema>.<table> 或 dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) 或 HuggingFace 資料集中的位置。針對 INSTRUCTION_FINETUNE,資料應該使用每個包含 prompt 和 response 欄位的資料列格式化。若為 CONTINUED_PRETRAIN,這是 .txt 檔案的資料夾。 請參閱 針對接受的數據格式準備基礎模型微調 數據,以及 針對數據大小建議進行模型定 型的建議數據大小。 |
register_to |
x | 字串 | Unity 目錄和結構描述 (<catalog>.<schema> 或 <catalog>.<schema>.<custom-name>),亦即模型為方便部署在訓練後註冊的位置。 如果未定義 custom-name,則預設為回合名稱。 |
data_prep_cluster_id |
字串 | 用於 Spark 資料處理之叢集的叢集 ID。 對於訓練資料位於差異資料表的受監督訓練工作,這是必要的項目。 如需如何尋找叢集 ID 的資訊,請參閱取得叢集 ID。 | |
experiment_path |
字串 | 儲存訓練回合輸出 (計量和檢查點) 之 MLflow 實驗的路徑。 預設為使用者個人工作區內的回合名稱 (亦即 /Users/<username>/<run_name>)。 |
|
task_type |
字串 | 要執行的工作類型。 可以是 CHAT_COMPLETION (預設值)、CONTINUED_PRETRAIN 或 INSTRUCTION_FINETUNE。 |
|
eval_data_path |
字串 | 評估資料的遠端位置 (如果有)。 必須遵循與 train_data_path 相同的格式。 |
|
eval_prompts |
List[str] | 用於在評估期間產生回應的提示字串清單。 預設值為 None (不會產生提示)。 每次檢查模型的檢查點時,結果都會記錄至實驗。 每個模型檢查點都會觸發產生過程,各項產生參數如下:max_new_tokens: 100、temperature: 1、top_k: 50、top_p: 0.95、do_sample: true。 |
|
custom_weights_path |
字串 | 用於訓練之自訂模型檢查點的遠端位置。 預設值為 None,這表示回合會從所選模型的原始預先訓練權數開始。 如果提供自訂權數,則會使用這些權數,而不是模型的原始預先訓練權數。 這些權數必須是 Composer 檢查點,而且必須符合指定之架構 model 。 請參閱 建置自定義模型權數 |
|
training_duration |
字串 | 回合的總期間。 預設值為一個 Epoch 或 1ep。 可以在 Epoch (10ep) 或權杖 (1000000tok) 中指定。 |
|
learning_rate |
字串 | 模型訓練的學習速率。 對於 Llama 3.1 405B Instruct 以外的所有模型,預設學習速率為 5e-7。 對於 Llama 3.1 405B Instruct,預設學習速率為 1.0e-5。 最佳化工具是 Beta 值為 0.99 和 0.95 的 DecoupledLionW,未使用權數衰減。 學習速率排程器是 LinearWithWarmupSchedule,熱身階段佔總訓練持續時間 2%,最後學習速率乘數為 0。 |
|
context_length |
字串 | 資料範例的序列長度上限。 這可用來截斷任何太長的資料,並將較短的序列封裝在一起,提高效率。 預設值為 8192 個權杖,或所提供模型的內容長度上限,以較低者為準。 您可以使用這個參數設定內容長度,但不支援超出每個模型內容長度上限的設定。 如需每個模型支援的內容長度上限,請參閱支援的模型。 |
|
validate_inputs |
布林值 | 是否要在送交訓練工作之前,驗證輸入路徑的存取權。 預設值為 True。 |
以自訂模型權數為基礎建置
基礎模型微調支援使用選擇性參數 custom_weights_path 來新增自定義權數,以定型和自定義模型。
若要開始使用,請從先前的訓練回合設定 custom_weights_path 為 Composer 檢查點路徑。 您可以在先前 MLflow 執行的 [成品] 索引標籤中找到檢查點路徑。 檢查點資料夾名稱會對應至特定快照集的批次和 Epoch,例如 ep29-ba30/。
![前一個 MLflow 回合的 [成品] 索引標籤](../../_static/images/large-language-models/checkpoint-path.png)
- 若要提供先前執行的最新檢查點,請將 設定
custom_weights_path為 Composer 檢查點。 例如:custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink。 - 若要提供先前的檢查點,請將 設定
custom_weights_path為資料夾的路徑,其中包含.distcp對應至所需檢查點的檔案,例如custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#。
接下來,更新 model 參數,以符合您傳遞給 custom_weights_path之檢查點的基底模型。
在下列範例 ift-meta-llama-3-1-70b-instruct-ohugkq 中,是先前 meta-llama/Meta-Llama-3.1-70B微調的執行。 若要微調 來自 ift-meta-llama-3-1-70b-instruct-ohugkq的最新檢查點,請設定 model 和 custom_weights_path 變數,如下所示:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
請參閱 設定定型回合 ,以在微調回合中設定其他參數。
取得叢集 ID
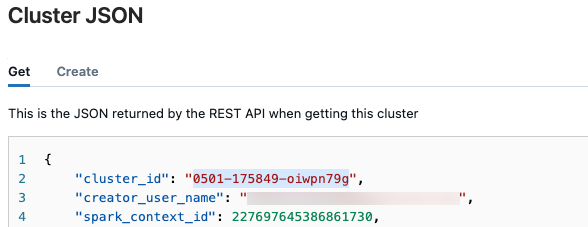
若要擷取叢集 ID:
在 Databricks 工作區的左側導覽列按下[計算]。
在資料表中,按下叢集的名稱。
按下右上角的
 ,然後從下拉式功能表中選取[檢視 JSON]。
,然後從下拉式功能表中選取[檢視 JSON]。叢集 JSON 檔案隨即出現。 複製叢集識別碼,亦即檔案中的第一行。
取得回合狀態
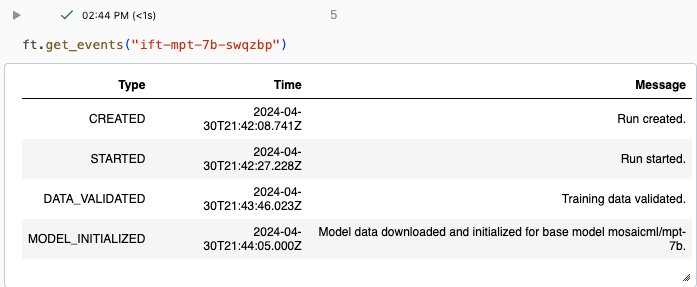
若要追蹤回合的進度,您可以使用 Databricks UI 中的 [實驗] 頁面或使用 API 命令 get_events()。 如需詳細資訊,請參閱 檢視、管理和分析基礎模型微調執行。
get_events() 輸出範例︰
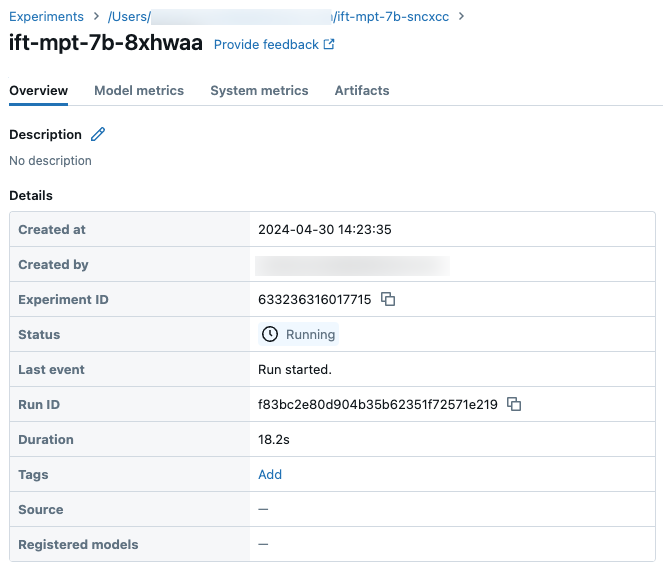
實驗頁面上的回合範例詳細資料:
下一步
訓練回合完成之後,您可以在 MLflow 檢閱計量及部署推斷模型。 請參閱教學課程:建立和部署基礎模型微調執行的步驟 5 到 7。
如需逐步說明資料準備、微調訓練回合組態和部署的指令微調範例,請參閱指令微調:具名實體辨識示範筆記本。
筆記本範例
下列筆記本示範如何使用 Meta Llama 3.1 405B Instruct 模型產生綜合資料,並使用該資料微調模型: