使用 MLflow 執行來查看訓練結果
本文說明如何使用 MLflow 執行來檢視和分析模型定型實驗的結果,以及如何管理和組織執行。 如需 MLflow 實驗的詳細資訊,請參閱 透過 MLflow 實驗組織訓練執行。
MLflow 執行對應於模型程式碼的單次執行。 每個執行都會記錄啟動執行之筆記本、執行所建立的任何模型、模型 parameters 和計量儲存為索引鍵/值組、執行元數據標記,以及執行所建立的任何成品或輸出檔案等資訊。
所有 MLflow 執行皆會記錄到作用中的實驗。 如果您尚未將實驗 set 明確標記為當前使用的實驗,則會將執行記錄至 notebook 環境下的實驗。
檢視執行詳細數據
您可以從其實驗詳細數據頁面,或直接從建立執行的筆記本存取執行。
從 [實驗詳細數據] 頁面點擊運行 table中的名稱。
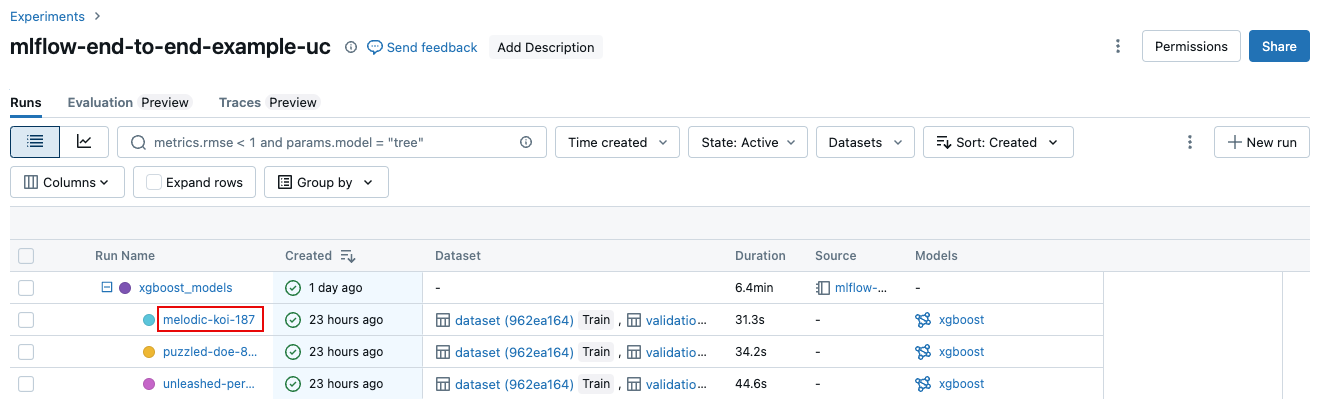
從筆記本中,點擊實驗執行側邊欄中的執行名稱。

執行畫面 顯示了用於此執行的 parameters,以及執行所產生的指標和詳細資訊,包括到來源筆記本的連結。 從執行儲存的成品可在 [成品] 索引卷標 中取得。
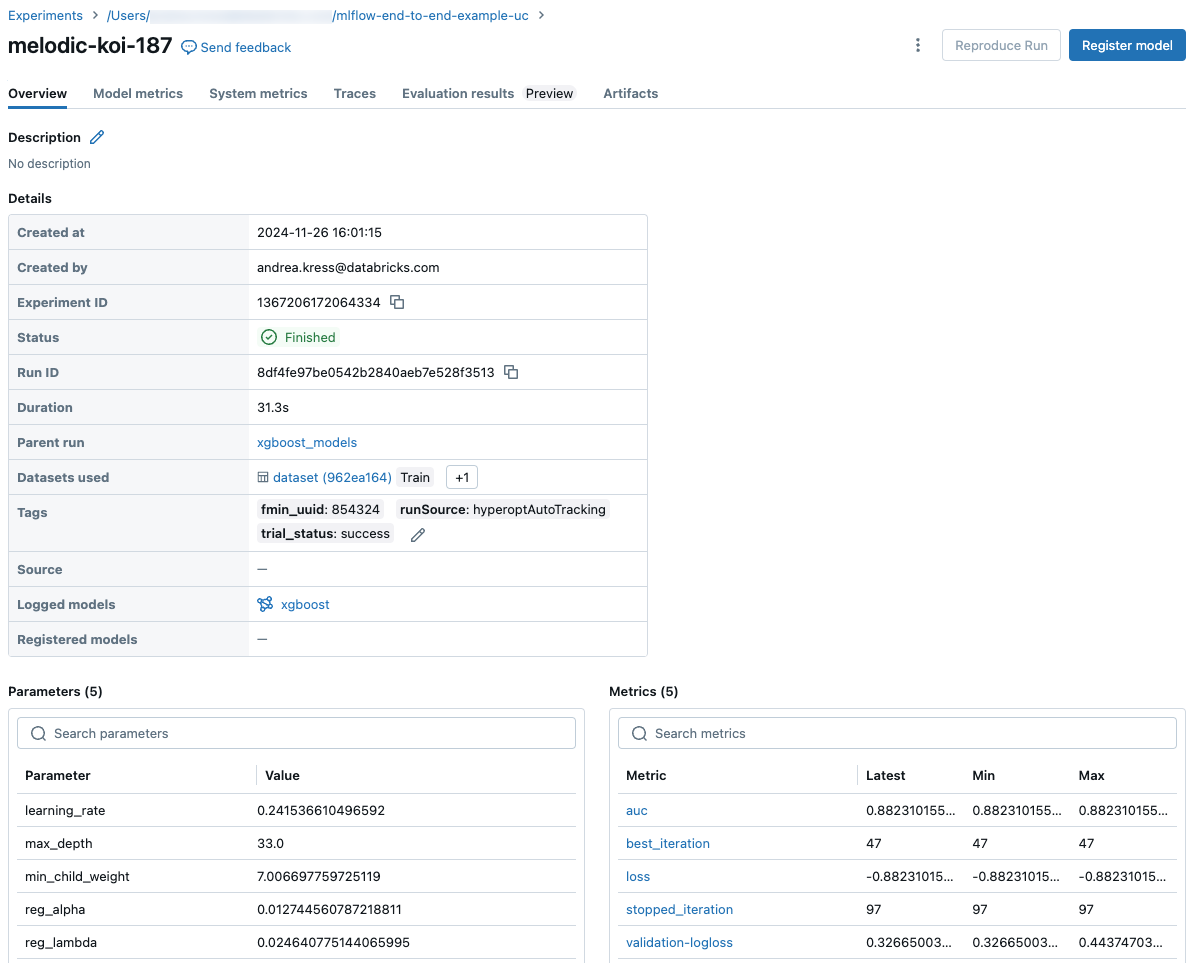
預測的程式碼片段
如果您從執行中記錄模型,模型會出現在 [Artifacts] 索引標籤中,以及說明如何在 Spark 和 Pandas DataFrame 上載入和使用模型進行預測的代碼段。
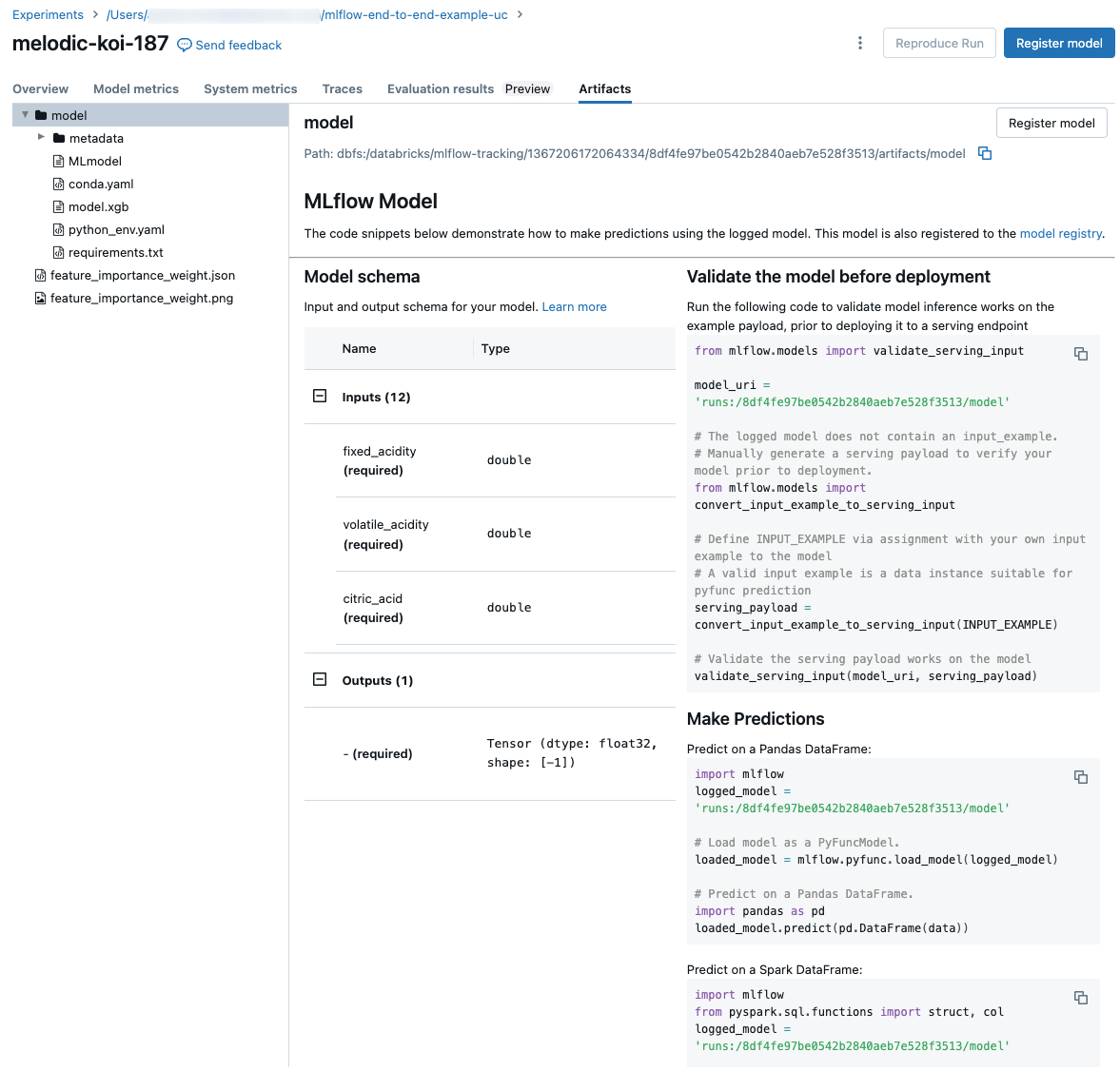
檢視用於運行的筆記本
若要檢視建立執行的筆記本的版本:
- 在實驗詳細數據頁面上,點擊 Sourcecolumn中的連結。
- 在 [執行] 頁面上,按下 [來源] 旁的連結。
- 從筆記本的 [實驗執行] 側邊欄中,按下該實驗執行的方塊中的 [筆記本]
 圖示。
圖示。
與執行相關聯的筆記本版本會出現在主面板 window 中,並有一個顯示執行日期和時間的高亮提示列。
將標記新增至執行
標籤是索引鍵/值組,您可稍後建立和用來搜尋執行。
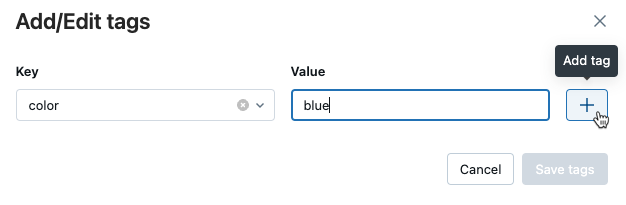
在 [執行] 頁面上的 [詳細數據]table中,按兩下 [標籤標旁的 [新增]。

[新增/編輯標籤] 對話框隨即開啟。 在 [金鑰] 欄位中,輸入金鑰的名稱,然後點擊 [新增標籤]。
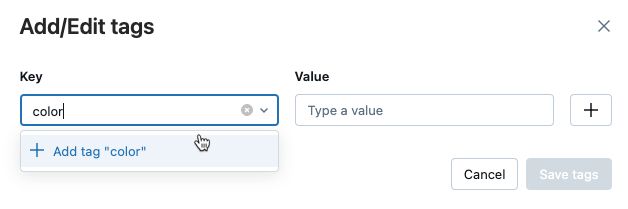
在 [值] 字段中,輸入標籤的值。
點擊加號以儲存您剛才輸入的鍵值對。
若要新增其他標籤,請重複步驟 2 到 4。
完成時,按一下 儲存標籤。
編輯或刪除執行的標記
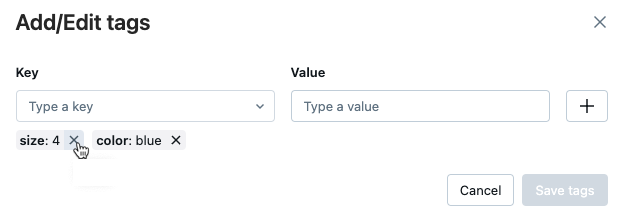
在 [執行] 頁面上的 [詳細數據table],點擊現有標籤旁的鉛筆圖示

[新增/編輯標籤] 對話框隨即開啟。
若要刪除標記,請按下該標籤上的 X。
若要編輯標籤,請從下拉功能表中選擇
,然後在「值」欄位中編輯 的值。 按一下加號以儲存您的變更。 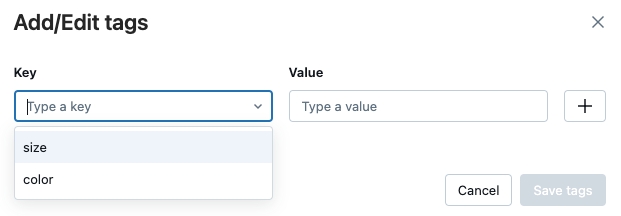
完成後,按一下 儲存卷標。
重現執行的軟體環境
您可以按下執行頁面右上角的 [重現執行環境],以重現該次執行的準確軟體環境。 下列對話方塊隨即顯示:
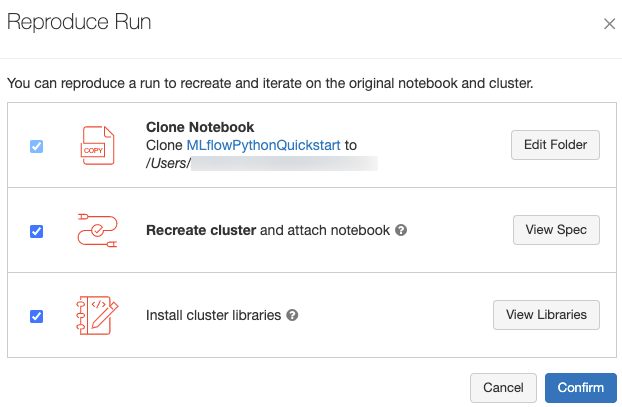
當您按下 [確認] 時,使用預設設定:
- 筆記本會被複製到對話方塊中顯示的位置。
- 如果原始叢集仍然存在,則複製的筆記本會連結至原始叢集,並啟動叢集。
- 如果原始叢集已不存在,則會建立並啟動具有相同組態的新叢集,包括任何已安裝的程式庫。 筆記本會連結至您所使用的最後一個叢集。
您可以 select 複製筆記本到另一個位置,並查看叢集組態和已安裝的函式庫:
- 若要
不同的資料夾來儲存複製的筆記本,請按下 [編輯資料夾] 。 - 若要查看叢集規格,請按下 [檢視規格]。若要只複製筆記本而非叢集,請取消選取此選項。
- 如果原始叢集已不存在,您可以按下 [檢視連結庫]來查看原始叢集上安裝的連結庫。 如果原始叢集仍然存在,此區段會呈現灰色。
重新命名執行
若要重新命名執行,請按下執行頁面右上角的 Kebab 功能表 ![]() (位於 許可權 按鈕旁邊),然後選擇 select重新命名。
(位於 許可權 按鈕旁邊),然後選擇 select重新命名。
要顯示的 Selectcolumns
若要控制實驗詳細頁面上顯示的 columns(來自執行 table),請從下拉菜單中按一下 [Columns] 和 [select]。
篩選執行
您可以在實驗詳細資訊頁面上的 table 中,根據參數或計量 values搜尋運行。 您也可依標記搜尋執行。
若要搜尋符合包含參數和計量 values的表達式的執行,請在搜尋欄位中輸入查詢,然後按 Enter。 一些查詢語法範例如下:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1根據預設,計量 values 會根據上次記錄的值進行篩選。 使用
MIN或MAX可讓您分別根據的最小或最大計量 values搜尋執行。 只有在 2024 年 8 月之後記錄的執行,才會具備最小和最大計量 values。若要依標記搜尋執行,請輸入以下格式的標籤:
tags.<key>="<value>"。 字串 values 必須以引弧括住,如下所示。tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5索引鍵和 values 可以包含空格。 如果索引鍵包含空格,您必須將其括在反引號中,如下所示。
tags.`my custom tag` = "my value"
您也可以根據運行的狀態(作用中或已刪除)、創建時間,以及所使用的資料集來篩選運行。 若要這樣做,請分別從 時間創建、狀態或 數據集 下拉功能表中選取。
下載執行
您可以從 [實驗詳細資料] 頁面下載執行,如下所示:
單擊
 開啟 kebab 功能表。
開啟 kebab 功能表。![Kebab 功能表,並在 [實驗] 頁面上下載選項。](../_static/images/mlflow/download-runs.png)
若要下載 CSV 格式的檔案,其中包含顯示的所有回合(最多 100 個),select下載
<n>執行。 MLflow 會建立並下載一個文件,每列代表一個執行,並包含每個執行的以下字段:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...如果您要下載超過 100 次執行紀錄,或希望以程式化的方式下載執行紀錄,select下載所有執行。 隨即開啟對話框,其中顯示您可以在筆記本中複製或開啟的代碼段。 在筆記本數據格中執行此程式代碼之後,select從數據格輸出下載所有數據列。
刪除執行
您可以遵循下列步驟,從實驗詳細資訊頁面刪除執行紀錄:
- 在實驗中,按兩下執行左邊的複選框,select 一或多個執行。
- 按一下刪除。
- 如果執行是父系執行,請決定是否也想要刪除子系執行。 預設會選取此選項。
- 按一下 [刪除] 以確認。 已刪除的執行會儲存 30 天。 若要顯示已刪除的執行,請在 [狀態] 字段中 select[已刪除]。
根據建立時間執行大量刪除
您可使用 Python 來大量刪除在 UNIX 時間戳記之前或之上建立的實驗執行。
使用 Databricks Runtime 14.1 或更新版本,您可呼叫 mlflow.delete_runs API 來刪除執行,並傳回已刪除的執行數目。
以下是 mlflow.delete_runsparameters:
-
experiment_id:包含要刪除的執行的實驗的識別碼。 -
max_timestamp_millis:以毫秒為單位的建立時間戳記上限,自 UNIX Epoch 以來用於刪除執行。 只會刪除在此時間戳記之前或之上建立的執行。 -
max_runs: 選用。 正整數,表示要刪除的執行數目上限。 max_runs 允許的最大值為 10000。 如果未指定,max_runs會預設為 10000。
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
使用 Databricks Runtime 13.3 LTS 或更早版本,您可在 Azure Databricks Notebook 中執行下列用戶端程式碼。
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
請參閱 Azure Databricks 實驗 API 檔,以取得
Restore 執行
您可以 restore 先前從 UI 中刪除的執行,如下所示:
- 在 [實驗] 頁面上的 [狀態] 字段中,select[已刪除] 以顯示已刪除的執行。
- Select 透過點選執行左側的複選框來選擇一個或多個運行。
- 點擊Restore。
- 按兩下 [Restore] 以確認。 當您在 [狀態] 欄位中 select啟用 時,現在會顯示復原的執行。
大量 restore 會根據刪除時間執行
您也可以使用 Python 來批量運行在 UNIX 時間戳時或之後被刪除的實驗 restore 執行。
使用 Databricks Runtime 14.1 或更高版本,您可以呼叫 mlflow.restore_runs API 來 restore 執行紀錄,並傳回已還原的執行紀錄數目。
以下是 mlflow.restore_runsparameters:
-
experiment_id:包含運行的實驗識別碼到 restore。 -
min_timestamp_millis:以毫秒為單位的刪除時間戳記下限,自 UNIX Epoch 以來用於還原執行。 只有在此時間戳記或之後刪除的執行才會還原。 -
max_runs: 選用。 指定的正整數,表示 restore的最大運行次數。 max_runs 允許的最大值為 10000。 如果未指定,max_runs 會預設為 10000。
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
使用 Databricks Runtime 13.3 LTS 或更早版本,您可在 Azure Databricks Notebook 中執行下列用戶端程式碼。
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
請參閱 Azure Databricks 實驗 API 文件,以取得
比較執行
您可從單一實驗或多個實驗比較執行。 [比較執行] 頁面會以圖形和表格式的格式呈現所選執行的相關資訊。 您也可以建立執行結果的視覺化,以及執行資訊 tables、執行 parameters和指標的視覺化。
建立視覺效果:
-
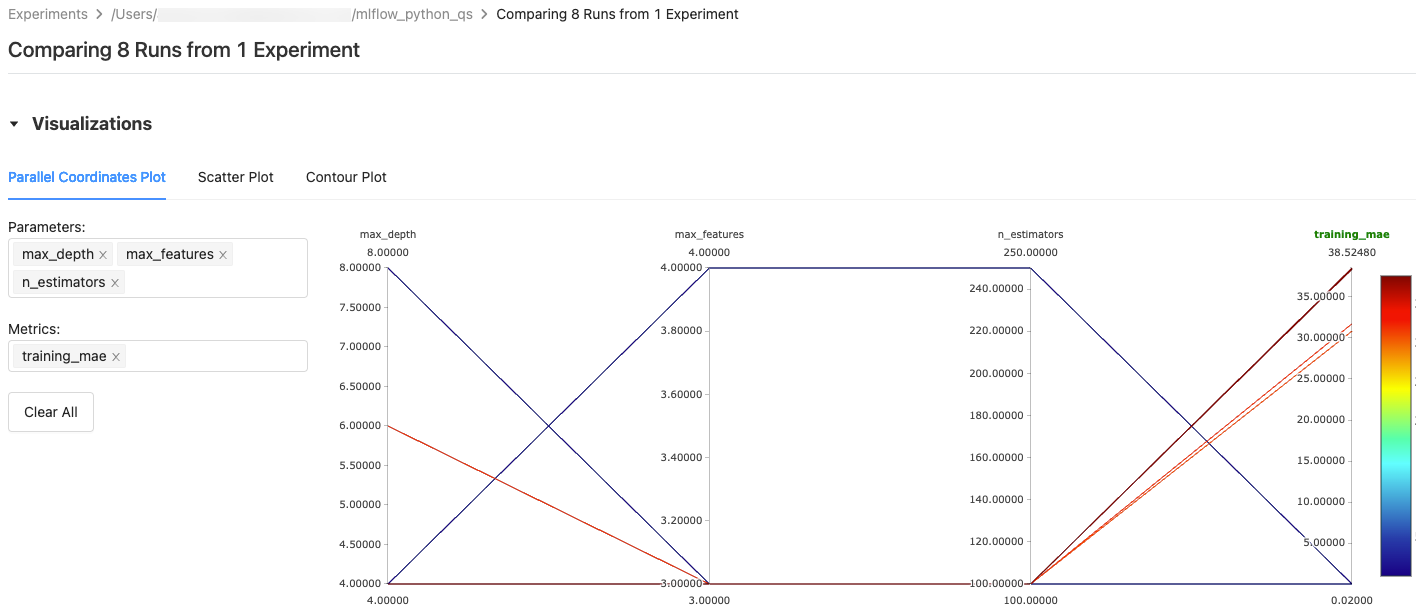
Select 繪圖類型(平行座標繪圖、散佈圖或 分布圖)。
針對 平行座標圖,select 和要繪製的指標 parameters。 從這裡,您可以識別所選 parameters 與計量之間的關聯性,這可協助您更妥善地定義模型的超參數微調空間。
針對 散佈圖 或 分布圖,select 要顯示在每個座標軸上的參數或度量。
Parameters 和 計量tables 顯示所有選取回合的執行 parameters 和計量。 這些 tables 中的 columns 由上述 執行詳情table 即時識別。 為了簡化操作,您可以切換 ![[僅顯示差異] 按鈕](../_static/images/mlflow/show-diff-only.png) ,以隱藏所有選取的運行中相同的 parameters 和計量。
,以隱藏所有選取的運行中相同的 parameters 和計量。
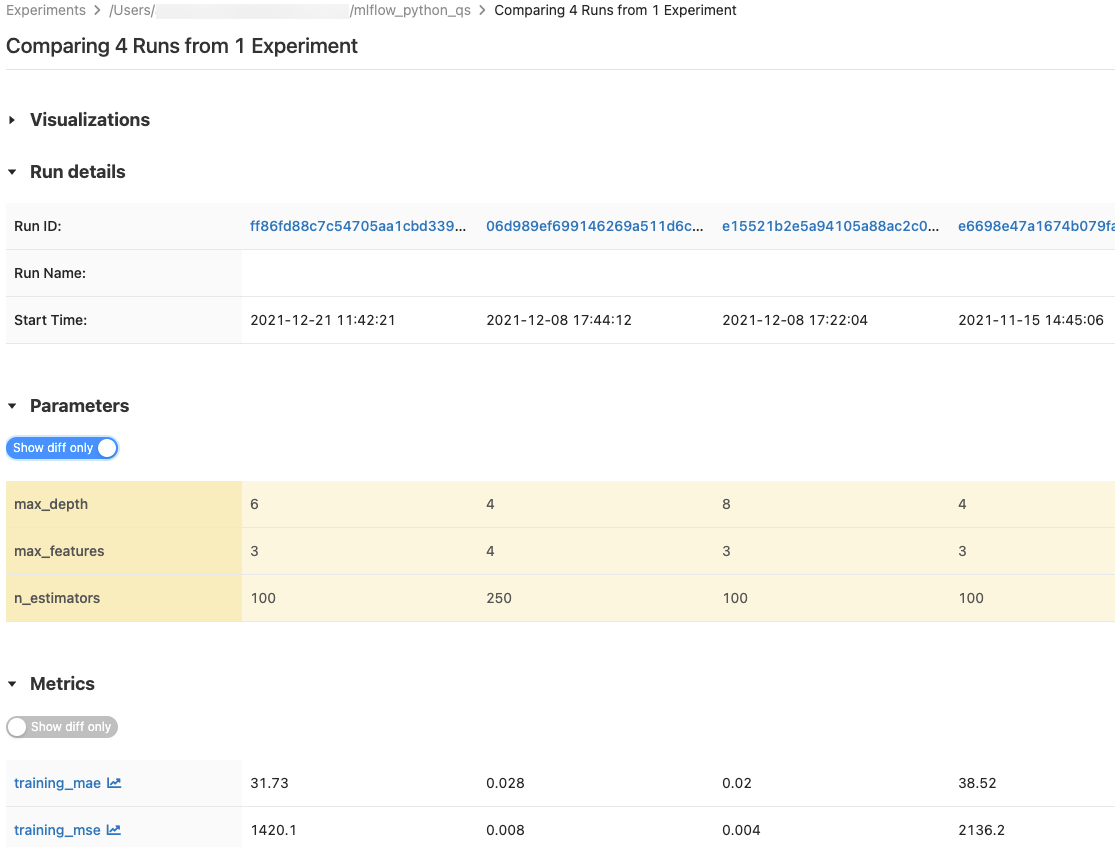
比較單一實驗的執行
- 在 [實驗詳細資料] 頁面,勾選執行左邊的複選框來選擇 select 兩次或更多次的執行,或選擇 column頂端的核取方塊以選取 select 所有執行。
- 按一下 [比較]。 [比較
<N>執行] 畫面隨即出現。
比較多個實驗的執行
- 在 [實驗] 頁面上,select 您可以通過點選實驗名稱左邊的方塊來選擇您想要比較的實驗。
- 按下 [比較 (n) (n] 是您選取的實驗數目)。 隨即出現畫面,其中顯示您選取的實驗的所有執行。
- Select 兩個以上的執行方式,方法是按兩下執行左邊的複選框,或選取 column頂端的方塊來 select 所有執行。
- 按一下 [比較]。 [比較
<N>執行] 畫面隨即出現。
在工作區之間複製執行
若要透過 Databricks 工作區匯入或匯出 MLflow 執行,您可使用社群導向的開放原始碼專案 MLflow Export-Import。