二進位檔
Databricks Runtime 支援 二進位檔 數據源,它會讀取二進位檔,並將每個檔案轉換成包含檔案原始內容和元數據的單一記錄。 二進位檔數據源會產生具有下列數據行和可能分割數據行的 DataFrame:
path (StringType):檔案的路徑。modificationTime (TimestampType):檔案的修改時間。 在某些 Hadoop FileSystem 實作中,這個參數可能無法使用,而且此值會設定為預設值。length (LongType):以位元組為單位的檔案長度。content (BinaryType):檔案的內容。
若要讀取二進位檔,請將資料來源 format 指定為 binaryFile。
影像
Databricks 建議您使用二進位檔數據源來載入影像數據。
Databricks 函 display 式支持顯示使用二進位數據源載入的影像數據。
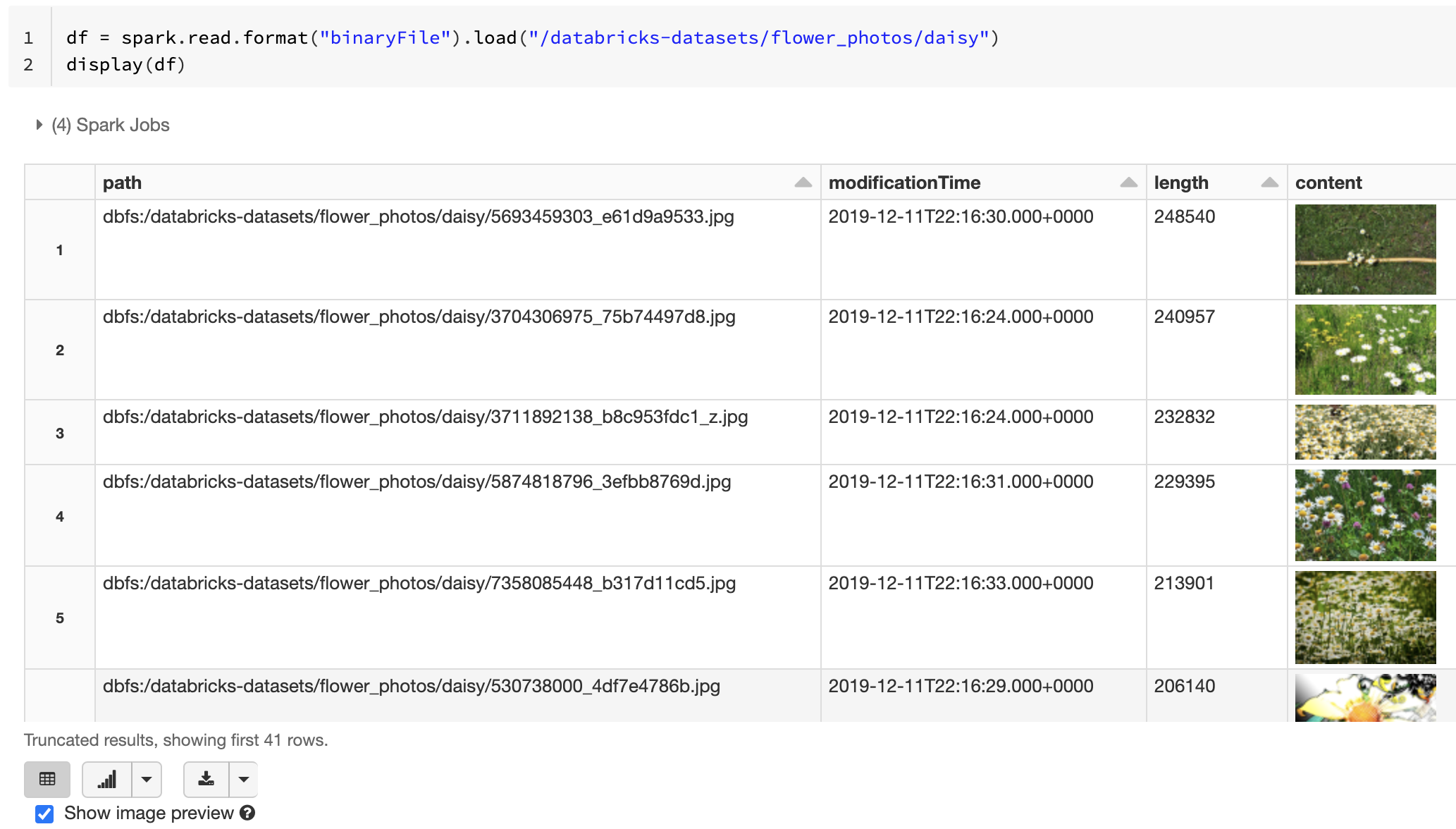
如果所有載入的檔案都有擴展名為映像的檔案名,則會自動啟用影像預覽:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
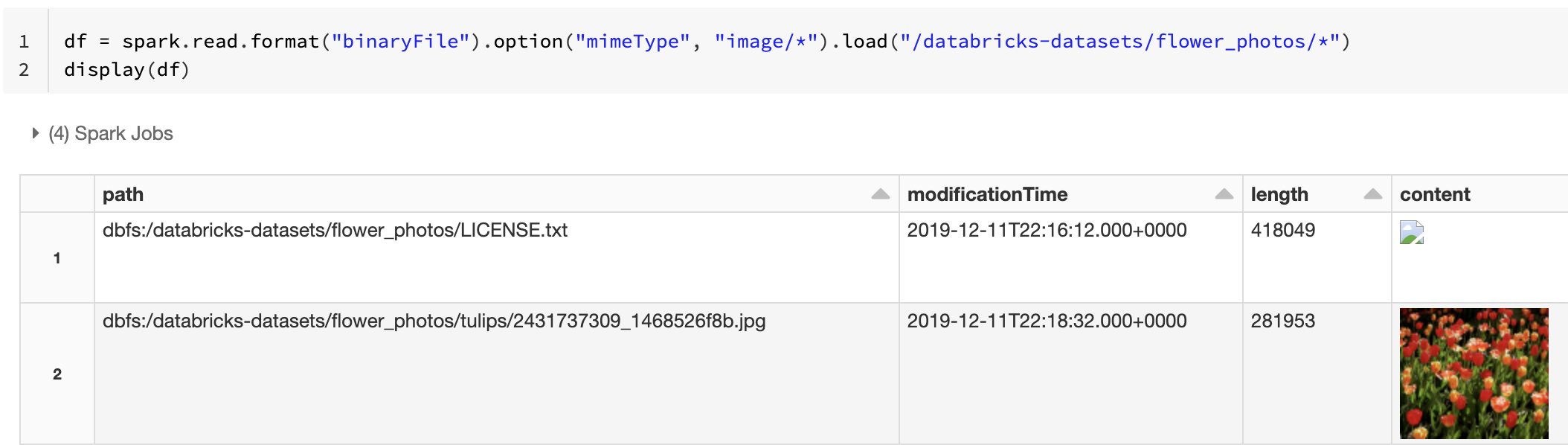
或者,您可以使用 選項搭配字串值"image/*"來標註二進位數據行,來強制影像預覽功能mimeType。 影像會根據其二進位內容中的格式信息來譯碼。 支援的映像型態為 bmp、 gif、 jpeg與 png。 不支援的檔案會顯示為中斷的影像圖示。
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
如需處理影像資料的建議工作流程,請參閱影像應用程式的參考解決方案。
選項。
若要載入路徑符合指定 glob 模式的檔案,同時保留資料分割探索的行為,您可以使用 pathGlobFilter 選項。 下列程式代碼會從輸入目錄讀取具有資料分割探索的所有 JPG 檔案:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
如果您想要忽略分割區探索,並以遞歸方式搜尋輸入目錄下的檔案,請使用 recursiveFileLookup 選項。 這個選項會搜尋巢狀目錄,即使其名稱 未 遵循資料分割命名配置,例如 date=2019-07-01。
下列程式代碼會以遞歸方式從輸入目錄讀取所有 JPG 檔案,並忽略資料分割探索:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Scala、Java 和 R 也有類似的 API。
注意
若要在將數據載入回時改善讀取效能,Azure Databricks 建議使用 Delta 資料表儲存從二進位檔載入的數據:
df.write.save("<path-to-table>")