sparklyr
Azure Databricks 支援筆記本、工作和 RStudio Desktop 中的 sparklyr。 本文章說明如何使用 sparklyr,並提供您可以執行的範例指令碼。 如需更多資訊,請參閱 Apache Spark 的 R 介面 (英文)。
需求
Azure Databricks 會透過每個 Databricks Runtime 版本散發最新穩定版本的 sparklyr。 您可以匯入已安裝的 sparklyr 版本,在 Azure Databricks R 筆記本或 Azure Databricks 上託管的 RStudio Server 中使用 sparklyr。
在 RStudio Desktop 中,Databricks Connect 可讓您將 sparklyr 從本機電腦連線到 Azure Databricks 叢集,並執行 Apache Spark 程式碼。 請參閱使用 sparklyr 和 RStudio Desktop 搭配 Databricks Connect (英文)。
將 sparklyr 連線至 Azure Databricks 叢集
若要建立 sparklyr 連線,您可以在 "databricks" 中使用 spark_connect() 作為連線方法。
不需要額外的 parametersspark_connect(),也不需要呼叫 spark_install(),因為Spark已安裝在 Azure Databricks 叢集上。
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
使用 sparklyr 的進度列和 Spark UI
如果您將 sparklyr 連線物件指派給上述範例中名為 sc 的變數,就會在觸發 Spark 工作的每個命令之後,在筆記本中看到 Spark 進度列。
此外,您可以按一下進度列旁邊的連結,以檢視與指定 Spark 工作相關聯的 Spark UI。
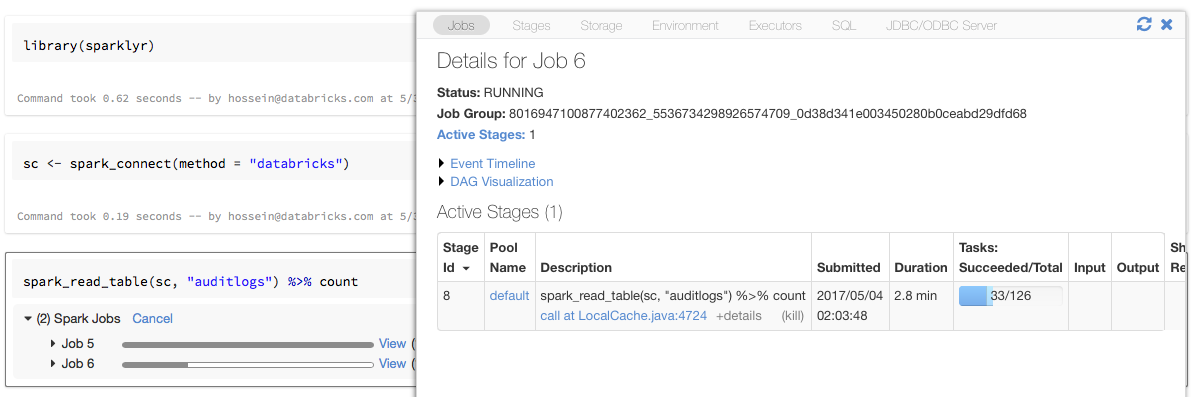
使用 sparklyr
安裝 sparklyr 並建立連線之後,所有其他 sparklyr API 就會如平常般運作。 如需一些範例,請參閱範例筆記本 (英文)。
sparklyr 通常與其他 tidyverse 套件一起使用,例如 dplyr。 為了方便起見,這些套件大部分都預先安裝在 Databricks 上。 只要匯入它們就可以開始使用 API。
同時使用 sparklyr 和 SparkR
SparkR 和 sparklyr 可以在單一筆記本或工作中一起使用。 您可以匯入 SparkR 以及 sparklyr,並使用其功能。 在 Azure Databricks 筆記本中,SparkR 連線已預先設定。
SparkR 中的某些函數會遮罩 dplyr 中的許多函數:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
如果您在匯入 dplyr 之後匯入 SparkR,就可以使用完整名稱來參考 dplyr 中的函數,例如 dplyr::arrange()。
同樣地,如果您在 SparkR 之後匯入 dplyr,則 SparkR 中的函數會由 dplyr 遮罩。
或者,您也可以在不需要時,選擇性地將這兩個套件的其中一個中斷連結。
detach("package:dplyr")
另請參閱比較 SparkR 和 sparklyr (英文)。
在 spark-submit 工作中使用 sparklyr
透過小幅度修改程式碼,您可以執行在 Azure Databricks 上使用 sparklyr 做為 spark-submit 工作的指令碼。 上述某些指示不適用於在 Azure Databricks 上的 spark-submit 工作中使用 sparklyr。 特別是,您必須提供 Spark 主要 URL 給 spark_connect。 例如:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
不支援的功能
Azure Databricks 不支援 sparklyr 方法,例如需要本機瀏覽器的 spark_web() 和 spark_log()。 不過,由於 Spark UI 內建在 Azure Databricks 上,因此您可以輕鬆地檢查 Spark 工作和記錄。
請參閱計算驅動程式和工作者記錄 (英文)。
範例筆記本:Sparklyr 示範
Sparklyr 筆記本
如需其他範例,請參閱 使用 DataFrames,以及 tables 在 R中的內容。