差異數據表串流讀取和寫入
Delta Lake 已透過和writeStream與 Spark 結構化串流readStream深入整合。 Delta Lake 克服許多通常與串流系統和檔案相關的限制,包括:
- 將低延遲擷取所產生的小型檔案聯合在一起。
- 使用多個數據流(或並行批次作業)維護「完全一次」處理。
- 使用檔案作為數據流的來源時,有效率地探索哪些檔案是新的檔案。
注意
本文說明如何使用 Delta Lake 數據表作為串流來源和接收。 若要瞭解如何在 Databricks SQL 中使用串流數據表載入數據,請參閱 在 Databricks SQL 中使用串流數據表載入數據。
如需使用 Delta Lake 串流靜態聯結的詳細資訊,請參閱 Stream-static 聯結。
差異數據表做為來源
結構化串流會以累加方式讀取 Delta 數據表。 對 Delta 數據表使用串流查詢時,新記錄會以等冪方式處理,因為新的數據表版本會認可源數據表。
下列程式代碼範例示範如何使用數據表名稱或檔案路徑來設定串流讀取。
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
重要
如果 Delta 資料表的結構描述在串流讀取在根據資料表開始之後變更,查詢就會失敗。 就大部分結構描述變更而言,您可以重新啟動串流,以解決結構描述不符問題,然後繼續處理。
在 Databricks Runtime 12.2 LTS 和以下版本中,您無法從已啟用數據行對應的 Delta 數據表進行串流,因為該數據表已啟用非累加架構演進,例如重新命名或卸除數據行。 如需詳細資料,請參閱使用資料行對應和結構描述變更進行串流處理。
限制輸入速率
下列選項可用來控制微批次:
maxFilesPerTrigger:每個微批次中要考慮多少個新檔案。 預設值為 1000。maxBytesPerTrigger:每個微批次中會處理多少數據。 此選項會設定「軟最大值」,這表示批次會處理大約這個數據量,而且可能會處理超過限制,以便在最小輸入單位大於此限制的情況下向前移動串流查詢。 預設不會設定此設定。
如果您搭配 maxFilesPerTrigger使用 maxBytesPerTrigger ,則微批次會處理數據,直到maxFilesPerTrigger達到 或 maxBytesPerTrigger 限制為止。
注意
如果源數據表交易因為設定而清除logRetentionDuration,而串流查詢會嘗試處理這些版本,則查詢預設會無法避免數據遺失。 您可以將 選項 failOnDataLoss 設定為 false 忽略遺失的數據並繼續處理。
串流 Delta Lake 異動數據擷取 (CDC) 摘要
Delta Lake 變更數據摘要 會記錄 Delta 資料表的變更,包括更新和刪除。 啟用時,您可以從變更資料摘要串流處理邏輯,以處理下游數據表的插入、更新和刪除。 雖然變更數據摘要數據輸出與所描述的 Delta 資料表稍有不同,但這會提供將累加變更傳播至獎章架構中下游數據表的解決方案。
重要
在 Databricks Runtime 12.2 LTS 和以下,您無法從已啟用數據行對應之 Delta 數據表的變更數據摘要進行串流處理,而該數據表已啟用非加總架構演進,例如重新命名或卸除數據行。 請參閱使用資料行對應和結構描述變更進行串流。
忽略更新和刪除
結構化串流不會處理不是附加的輸入,如果在做為來源的數據表上發生任何修改,則會擲回例外狀況。 處理無法自動傳播下游的變更有兩個主要策略:
- 您可以刪除輸出和檢查點,並從頭重新啟動數據流。
- 您可以設定這兩個選項之一:
ignoreDeletes:忽略刪除分割區界限數據的交易。skipChangeCommits:忽略刪除或修改現有記錄的交易。skipChangeCommits包含ignoreDeletes。
注意
在 Databricks Runtime 12.2 LTS 和更新版本中, skipChangeCommits 取代先前的設定 ignoreChanges。 在 Databricks Runtime 11.3 LTS 和更低版本中, ignoreChanges 是唯一支援的選項。
ignoreChanges 的語意與 skipChangeCommits 相差很大。 啟用 ignoreChanges 後,在來源資料表中重新寫入的資料檔案會在如 UPDATE、MERGE INTO、DELETE (在分割區內) 或 OVERWRITE 等資料變更作業後重新發出。 未變更的資料列常會隨著新資料列發出,因此下游客戶必須能夠處理重複項目。 刪除項目不會傳播至下游。 ignoreChanges 包含 ignoreDeletes。
skipChangeCommits 會完全忽略檔案變更作業。 因如 UPDATE、MERGE INTO、DELETE 和 OVERWRITE 等資料變更作業而在來源資料表中重新寫入的資料檔案會遭到完全忽略。 若要反映上游來源資料表中的變更,您必須實作個別邏輯以傳播這些變更。
設定為 ignoreChanges 的工作負載會繼續使用已知的語意運作,但 Databricks 建議針對所有新的工作負載使用 skipChangeCommits 。 使用 ignoreChanges 移轉工作負載以 skipChangeCommits 需要重構邏輯。
範例
例如,假設您有一個數據表 user_events ,其中包含 date由 分割的、 user_email和數據 action 行 date。 您串流出數據表, user_events 而且由於GDPR而需要從資料表中刪除數據。
當您在數據分割界限刪除時(也就是 WHERE ,位於數據分割數據行上),檔案已依值分割,因此刪除只會從元數據卸除這些檔案。 當您刪除整個資料分割時,您可以使用下列專案:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
如果您移除多個分割區中的數據(在此範例中為篩選 user_email),請使用下列語法:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
如果您使用語句更新 user_email UPDATE ,則會重寫包含 user_email 有問題的 檔案。 使用 skipChangeCommits 忽略已變更的數據檔。
指定初始位置
您可以使用下列選項來指定 Delta Lake 串流來源的起點,而不需要處理整個數據表。
startingVersion:要從中開始的 Delta Lake 版本。 Databricks 建議省略此選項給大部分的工作負載。 未設定時,數據流會從最新的可用版本開始,包括當時數據表的完整快照集。如果指定,數據流會從指定的版本 (含) 開始讀取 Delta 資料表的所有變更。 如果指定的版本已無法使用,數據流將無法啟動。 您可以從 DESCRIBE HISTORY 命令輸出的數據行取得認可版本
version。若要只傳回最新的變更,請指定
latest。startingTimestamp:要從其開始的時間戳記。 串流讀取器會讀取時間戳或之後認可的所有數據表變更。 如果提供的時間戳在數據表認可之前,串流讀取會以最早的可用時間戳開始。 值為下列其中之一:- 時間戳字串。 例如:
"2019-01-01T00:00:00.000Z"。 - 日期字串。 例如:
"2019-01-01"。
- 時間戳字串。 例如:
您無法同時設定這兩個選項。 只有在啟動新的串流查詢時,才會生效。 如果串流查詢已啟動,且進度已記錄在其檢查點中,則會忽略這些選項。
重要
雖然您可以從指定的版本或時間戳啟動串流來源,但串流來源的架構一律是 Delta 數據表的最新架構。 您必須確定指定的版本或時間戳之後,Delta 資料表沒有不相容的架構變更。 否則,當讀取架構不正確的數據時,串流來源可能會傳回不正確的結果。
範例
例如,假設您有資料表 user_events。 如果您想要讀取自第 5 版以來的變更,請使用:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
如果您想要讀取自 2018-10-18 年以來的變更,請使用:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
處理初始快照集而不卸除數據
注意
這項功能適用於 Databricks Runtime 11.3 LTS 和更新版本。 這項功能處於公開預覽狀態。
使用 Delta 數據表做為數據流來源時,查詢會先處理數據表中的所有數據。 這個版本的 Delta 數據表稱為初始快照集。 根據預設,Delta 數據表的數據文件會根據上次修改的檔案進行處理。 不過,上次修改時間不一定代表記錄事件時間順序。
在具有已定義浮水印的具狀態串流查詢中,修改時間處理檔案可能會導致記錄以錯誤的順序處理。 這可能會導致浮水印延遲事件的記錄下降。
您可以啟用下列選項來避免資料卸除問題:
- withEventTimeOrder:是否應該以事件時間順序處理初始快照集。
啟用事件時間順序后,初始快照集數據的事件時間範圍會分成時間值區。 每個微批次都會篩選時間範圍內的數據,以處理貯體。 maxFilesPerTrigger 和 maxBytesPerTrigger 組態選項仍然適用於控制微批次大小,但只因處理本質而以近似的方式。
下圖顯示此程式:
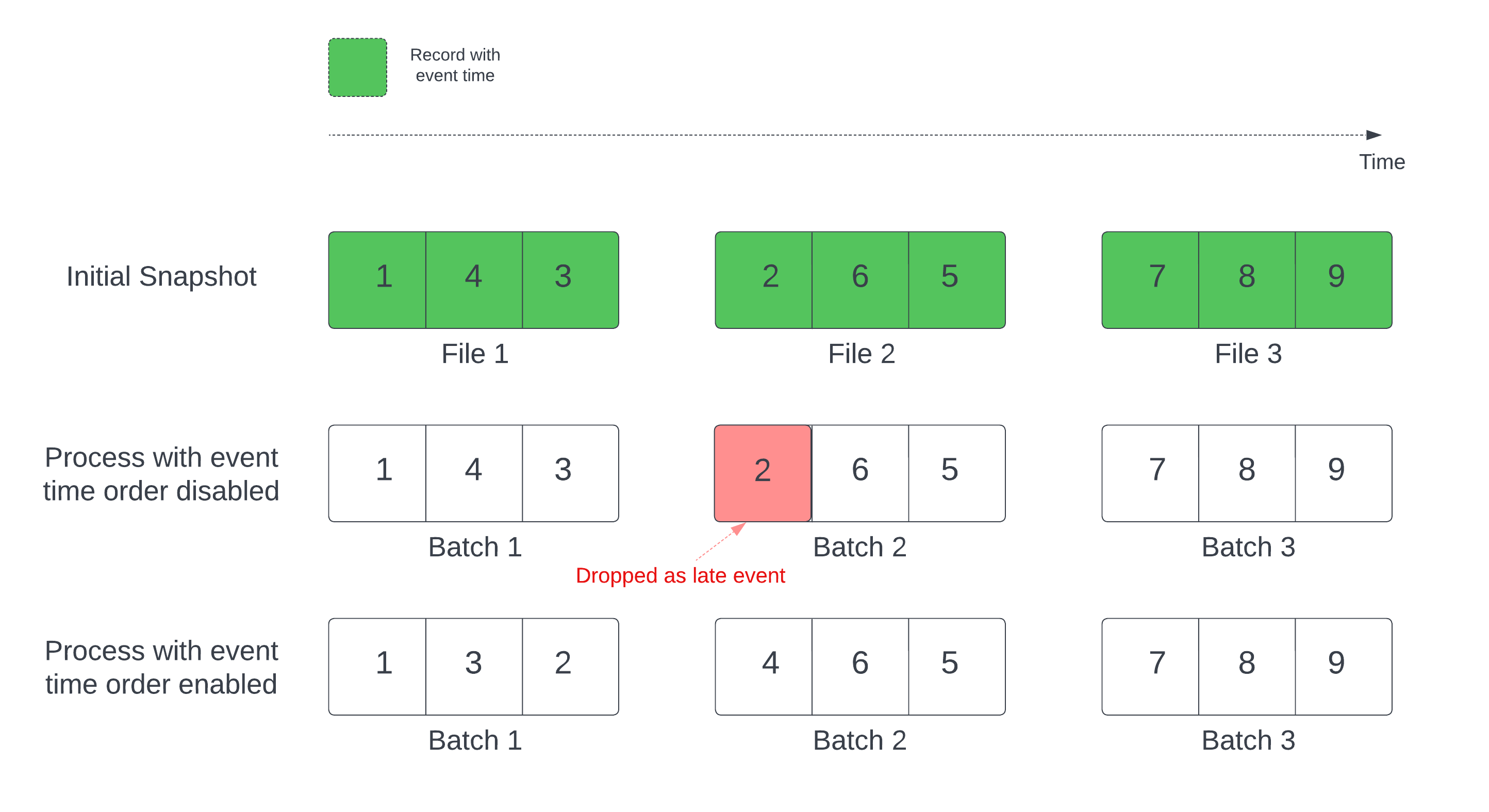
這項功能的值得注意的資訊:
- 只有在以預設順序處理具狀態串流查詢的初始差異快照集時,才會發生數據卸除問題。
- 當初始快照集仍在處理時,一旦啟動數據流查詢,就無法變更
withEventTimeOrder。 若要使用withEventTimeOrder已變更重新啟動,您必須刪除檢查點。 - 如果您執行已啟用WithEventTimeOrder的串流查詢,則必須先完成初始快照集處理,才能將它降級為不支援此功能的 DBR 版本。 如果您需要降級,您可以等候初始快照集完成,或刪除檢查點並重新啟動查詢。
- 在下列常見案例中不支援此功能:
- 事件時間數據行是產生的數據行,而且差異來源和浮浮浮水印之間有非投影轉換。
- 串流查詢中有多個 Delta 來源的浮水印。
- 啟用事件時間順序時,差異初始快照集處理的效能可能會變慢。
- 每個微批次都會掃描初始快照集,以篩選對應事件時間範圍內的數據。 若要加快篩選動作,建議您使用 Delta 源數據行作為事件時間,以便套用數據略過 (檢查 適用於 Delta Lake 的數據時是否適用)。 此外,沿著事件時間數據行的數據表分割可以進一步加速處理。 您可以檢查 Spark UI,以查看針對特定的微批次掃描了多少差異檔案。
範例
假設您有具有資料行的event_time資料表user_events。 您的串流查詢是匯總查詢。 如果您想要確保初始快照集處理期間不會卸除任何數據,您可以使用:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
注意
您也可以在叢集上使用 Spark 設定來啟用此功能,以套用至所有串流查詢: spark.databricks.delta.withEventTimeOrder.enabled true
差異數據表做為接收
您也可以使用結構化串流將數據寫入 Delta 資料表。 事務歷史記錄可讓 Delta Lake 完全保證一次處理,即使有其他數據流或批次查詢同時針對數據表執行也一樣。
注意
Delta Lake 函式會移除 Delta Lake VACUUM 未管理的所有檔案,但會略過任何以 _開頭的目錄。 您可以使用目錄結構, <table-name>/_checkpoints安全地儲存差異數據表的其他數據和元數據檢查點。
計量
您可以找出串流查詢程式中尚未處理的位元元組數目和檔案數目,作為 numBytesOutstanding 和 numFilesOutstanding 計量。 其他計量包括:
numNewListedFiles:為了計算此批次待辦專案而列出的 Delta Lake 檔案數目。backlogEndOffset:用來計算待辦項目數據表版本。
如果在筆記本中執行串流,您可以在串流查詢進度儀表板中的 [原始資料] 索引標籤下查看這些計量:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
附加模式
根據預設,串流會以附加模式執行,這會將新記錄新增至資料表。
在 toTable 串流至數據表時使用 方法,如下列範例所示:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
完整模式
您也可以使用結構化串流,以每個批次取代整個數據表。 其中一個使用案例範例是使用匯總來計算摘要:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
上述範例會持續更新數據表,其中包含客戶的匯總事件數目。
針對具有更寬鬆延遲需求的應用程式,您可以使用一次性觸發程式來節省計算資源。 您可以使用這些來更新指定排程上的摘要匯總數據表,只處理自上次更新之後抵達的新數據。
使用串流查詢的Upsert foreachBatch
您可以使用 和 foreachBatch 的組合merge,將串流查詢中的複雜 upsert 寫入 Delta 數據表。 請參閱<使用 foreachBatch 寫入任意資料接收器>。
此模式有許多應用程式,包括下列專案:
- 在更新模式中寫入串流匯總:這比完成模式更有效率。
- 將資料庫變更數據流寫入 Delta 數據表:可用於
foreachBatch寫入變更數據的合併查詢,以持續將變更數據流套用至 Delta 數據表。 - 使用重複資料刪除將數據串流寫入 Delta 資料表: 重複資料刪除 的僅插入合併查詢可用來
foreachBatch持續將資料(重複重複專案)寫入具有自動重複數據刪除的 Delta 資料表。
注意
- 請確定內部的
merge語句foreachBatch具有等冪性,因為串流查詢的重新啟動可以多次在相同的數據批次上套用作業。 - 在 中使用
foreachBatch時merge,串流查詢的輸入數據速率(在筆記本速率圖表中回報StreamingQueryProgress並可見)可能會報告為來源產生數據的實際速率之倍數。 這是因為merge會讀取輸入資料數次,因而造成輸入計量相乘。 如果這造成瓶頸,您可以在merge之前快取批次 DataFrame,然後在merge之後取消快取。
下列範例示範如何使用 內的 foreachBatch SQL 來完成這項工作:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
您也可以選擇使用 Delta Lake API 來執行串流 upsert,如下列範例所示:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
在中寫入等冪數據表 foreachBatch
注意
Databricks 建議針對您想要更新的每個接收設定個別的串流寫入。 使用 foreachBatch 來寫入多個數據表串行化寫入,這可減少平行處理並增加整體延遲。
Delta 數據表支援下列 DataFrameWriter 選項,以在等冪內 foreachBatch 對多個數據表進行寫入:
txnAppId:您可以在每個 DataFrame 寫入時傳遞的唯一字串。 例如,您可以使用 StreamingQuery 識別碼作為txnAppId。txnVersion:單調遞增的數位,做為交易版本。
Delta Lake 使用 和 txnVersion 的組合txnAppId來識別重複的寫入並忽略它們。
如果批次寫入因失敗而中斷,則重新執行批次會使用相同的應用程式和批次標識符,協助運行時間正確識別重複的寫入並忽略它們。 應用程式識別碼 (txnAppId) 可以是任何用戶產生的唯一字串,而且不需要與數據流標識符相關。 請參閱<使用 foreachBatch 寫入任意資料接收器>。
警告
如果您移除串流檢查點,並使用新的檢查點重新啟動查詢,則必須提供不同的 txnAppId。 新的檢查點會以的 0批次標識符開頭。 Delta Lake 會使用批次標識碼和 txnAppId 作為唯一索引鍵,並略過具有已見值的批次。
下列程式代碼範例示範此模式:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}