使用擷取增強產生和微調來增強大型語言模型
本系列文章將討論 LLM 用來產生其響應的知識擷取模型。 根據預設,大型語言模型 (LLM) 只能存取其定型數據。 不過,您可以增強模型以包含實時數據或私人數據。 本文討論兩種增強模型的機制之一。
第一個機制是「擷取擴增世代」(RAG),這是一種前置處理形式,結合了語意搜尋與內容準備(在另一篇文章中討論)。
第二個機制是 微調,其是指在初始、廣泛定型之後,進一步將模型定型至特定數據集的程式,目標是調整模型,以便更妥善地處理工作或瞭解與該數據集相關的概念。 此程式可協助模型特製化或改善其處理特定類型輸入或定義域的正確性和效率。
下列各節將更詳細地說明這兩種機制。
了解 RAG
RAG 通常用來啟用「透過我的數據聊天」案例,其中具有大量文字內容(內部檔、檔等)的公司想要使用此主體作為使用者提示解答的基礎。
概括而言,您會為每個檔建立資料庫專案(或稱為「區塊」的檔部分)。 區塊會在其內嵌上編製索引,這是代表檔 Facet 的數位向量(陣列)。 當使用者提交查詢時,您可以搜尋資料庫以尋找類似的檔,然後將查詢和檔提交至 LLM 以撰寫答案。
注意
“擷取增強世代”(RAG)一詞可容納。 您可以套用本文中所述實作以RAG為基礎的聊天系統的程式,無論是想要使用外部數據用於支援容量(RAG)還是作為回應的中心部分(RCG)。 在與RAG相關的大部分閱讀中,不會處理此細微差別。
建立向量化文件的索引
建立以RAG為基礎的聊天系統的第一個步驟是建立包含檔內嵌的向量數據存放區(或檔的一部分)。 請考慮下圖,概述建立檔向量化索引的基本步驟。

此圖表代表 數據管線,負責擷取、處理和管理系統使用的數據。 這包括要儲存在向量資料庫中的前置處理數據,並確保送入 LLM 的數據格式正確。
整個程式是由內嵌的概念所驅動,這是數據的數值表示法(通常是單字、片語、句子,甚至整個檔),以機器學習模型可以處理的方式擷取輸入的語意屬性。
若要建立內嵌,您可以將內容區塊(句子、段落或整個文件)傳送至 Azure OpenAI 內嵌 API。 從內嵌 API 傳回的內容是向量。 向量中的每個值都代表內容的一些特性(維度)。 維度可能包括主題、語意意義、語法和文法、文字和片語使用方式、關係關係、樣式和語氣等。一起,向量的所有值都代表內容的 維度空間。 換句話說,如果您可以想出具有三個值的向量 3D 表示法,指定的向量會存在於 x、y、z 平面的特定區域中。 如果您有 1000 個或更多值,該怎麼辦? 雖然人類不可能在紙張上繪製一個 1000 維度的圖形,使其更容易理解,但計算機對維度空間的程度沒有問題。
圖表的下一個步驟描述將向量連同內容本身儲存(或內容位置的指標)和其他元數據儲存在向量資料庫中。 向量資料庫就像任何類型的資料庫,有兩個差異:
- 向量資料庫會使用向量做為索引來搜尋數據。
- 向量資料庫會實作稱為餘弦相似搜尋的演算法,也稱為 最接近的鄰近搜尋,其使用最符合搜尋準則的向量。
透過儲存在向量資料庫中的文件主體,開發人員可以建 置擷取器元件 ,以擷取符合使用者查詢的檔,以提供 LLM 以回應使用者的查詢。
使用您的檔回答查詢
RAG 系統會先使用語意搜尋來尋找撰寫答案時對 LLM 有説明的文章。 下一個步驟是將相符的文章連同使用者的原始提示傳送給 LLM 以撰寫答案。
將下圖視為簡單的RAG實作(有時稱為「天真RAG」)。
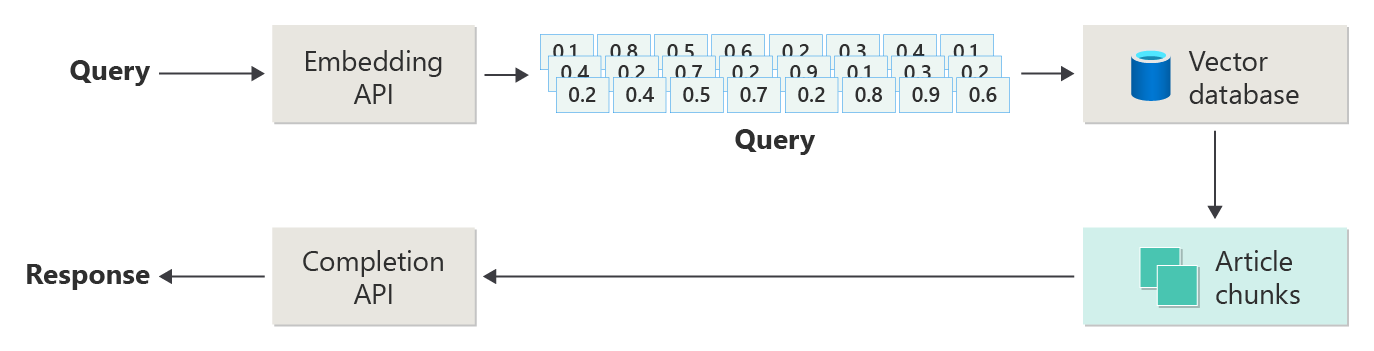
在圖表中,使用者提交查詢。 第一個步驟是為使用者的提示建立內嵌,以取得向量。 下一個步驟是搜尋向量資料庫,尋找與「最接近鄰近」相符的檔(或部分檔)。
餘弦相似度 是用來判斷兩個向量相似程度的措施,基本上評估兩個向量之間的餘弦值。 接近 1 的餘弦相似度表示高度相似度(小角度),而接近 -1 的相似度則表示不同(角度接近 180 度)。 此計量對於檔相似度等工作至關重要,其中目標是尋找具有類似內容或意義的檔。
「近鄰」演演算法的運作 方式是尋找最接近向量空間中指定點的向量(芳鄰)。 在 K 近鄰 (KNN) 演算法中,'k' 是指要考慮的近鄰數目。 此方法廣泛使用於分類和回歸中,其中演算法會根據定型集中 『k』 最接近鄰的多數標籤來預測新數據點的標籤。 KNN 和餘弦相似度通常會一起使用在建議引擎等系統中,其中目標是尋找最類似於使用者喜好設定的專案,以內嵌空間中的向量表示。
您可以從該搜尋取得最佳結果,並傳送比對內容,以及使用者的提示,以產生回應,希望透過比對內容來通知。
挑戰和考慮
實作RAG系統伴隨著一組挑戰。 數據隱私權是最重要的,因為系統必須負責處理用戶數據,尤其是在從外部來源擷取和處理資訊時。 計算需求也可能相當重要,因為擷取和產生式進程都是資源密集的。 確保響應的正確性和相關性,同時管理數據或模型中存在的偏差是另一個重要考慮。 開發人員必須仔細流覽這些挑戰,以建立有效率、道德且有價值的RAG系統。
本系列中的下一篇文章, 建置進階擷取擴增世代系統 提供更詳細的建置數據和推斷管線,以啟用生產就緒的RAG系統。
如果您想要立即開始實驗建置產生式 AI 解決方案,建議您先 看看使用您自己的 Python 數據範例開始使用聊天。 .NET、Java 和 JavaScript 也提供教學課程版本。
微調模型
在 LLM 的內容中,微調是指在一開始在大型、多樣化的數據集上定型之後,調整特定領域數據集上的模型參數的程式。
LLM 會在廣泛的數據集上定型(預先定型),並掌握語言結構、內容和廣泛的知識。 這個階段涉及學習一般語言模式。 微調會根據較小的特定數據集,將更多定型新增至預先定型的模型。 這個次要定型階段旨在調整模型,以更妥善地處理特定工作或瞭解特定領域,提高其精確度和這些特殊應用程式的相關性。 微調期間,會調整模型的權數,以進一步預測或了解這個較小數據集的細微差別。
一些考慮:
- 特製化:微調會針對特定工作量身打造模型,例如法律檔分析、醫學文字解譯或客戶服務互動。 這可讓模型在這些區域中更有效率。
- 效率:微調特定工作的預先定型模型比從頭開始定型模型更有效率,因為微調需要較少的數據和計算資源。
- 適應性:微調可讓您適應不屬於原始定型數據的新工作或網域,讓 LLM 針對各種應用程式使用多功能工具。
- 改善效能:對於與模型原本定型的數據不同的工作,微調可能會導致更好的效能,因為它會調整模型,以瞭解新定義域中所使用的特定語言、樣式或術語。
- 個人化:在某些應用程式中,微調有助於個人化模型的回應或預測,以符合使用者或組織的特定需求或喜好設定。 不過,微調有某些缺點和限制。 瞭解這些有助於決定何時選擇微調,而不是擷取增強世代 (RAG) 等替代專案。
- 數據需求:微調需要目標工作或網域特有的足夠大且高質量的數據集。 收集和策劃此數據集可能會很困難,而且需要大量資源。
- 過度學習風險:過度學習的風險,尤其是小型數據集。 過度學習可讓模型在定型數據上表現良好,但在新、看不見的數據上表現不佳,因而降低其一般性。
- 成本和資源:雖然比從頭開始定型的資源較少,但微調仍然需要計算資源,特別是對於大型模型和數據集而言,這可能會對某些使用者或專案造成阻礙。
- 維護和更新:微調的模型可能需要定期更新,才能隨著領域特定資訊隨著時間變更而保持有效。 這項持續維護需要額外的資源和數據。
- 模型漂移:當模型針對特定工作進行微調時,它可能會失去一些一般語言理解和多功能性,導致一種稱為模型漂移的現象。
使用微調 自定義模型說明如何微調模型。 概括而言,您會提供一組可能的問題和慣用答案的 JSON 數據集。 文件建議,提供 50 到 100 對問答組,但正確的數位會因使用案例而有很大的差異。
微調與擷取增強的產生
表面上,微調和擷取增強世代之間似乎有相當多的重疊。 在微調和擷取增強世代之間選擇取決於工作的特定需求,包括效能預期、資源可用性,以及網域特定度與一般性的需求。
何時偏好微調,而不是擷取擴增世代:
- 工作特定效能 - 當特定工作的高效能 十分重要時,最好進行微調,而且有足夠的領域特定數據可以有效定型模型,而不會有顯著的過度學習風險。
- 控制數據 - 如果您有專屬或高度特製化的數據,與基底模型定型的數據有顯著差異,微調可讓您將此獨特的知識併入模型中。
- 即時更新 的需求有限 - 如果工作不需要以最新信息持續更新模型,微調可能會更有效率,因為 RAG 模型通常需要存取最新的外部資料庫或因特網來提取最近的數據。
何時偏好使用擷取增強產生,而不是微調:
- 動態或不斷演進的內容 - RAG 更適合具有最新資訊的工作非常重要。 由於RAG模型可以即時從外部來源提取數據,因此更適合新聞產生或回答最近事件的問題等應用程式。
- 對特製化進行一般化 - 如果目標是在各種主題中保持強大的效能,而不是在窄領域表現,則RAG可能比較好。 它會使用外部 知識庫,允許它跨不同網域產生回應,而不需要過度學習特定數據集的風險。
- 資源條件約束 - 對於具有數據收集和模型定型有限資源的組織,使用RAG方法可能會提供符合成本效益的微調替代方案,特別是如果基底模型已對所需工作執行得相當良好時。
可能會影響應用程式設計決策的最終考慮
以下是本文所要考慮的事項清單,以及其他會影響應用程式設計決策的專案:
- 根據應用程式的特定需求,決定微調和擷取增強的產生。 微調可能會為特製化工作提供更好的效能,而RAG可為動態應用程式提供彈性和最新內容。