開始在 JavaScript 的聊天應用程式中評估答案
本文說明如何針對一組正確或理想的答案來評估聊天應用程式的答案(稱為基礎真相)。 每當您以影響答案的方式變更聊天應用程式時,請執行評估來比較變更。 此示範應用程式提供您目前可以使用的工具,讓您更輕鬆地執行評估。
依照本文中的指示,您可以:
- 使用針對主旨網域量身打造的範例提示。 這些提示已經在存放庫中。
- 從您自己的文件產生範例用戶問題和基礎真相解答。
- 使用範例提示搭配產生的用戶問題來執行評估。
- 檢閱答案的分析。
注意
本文使用一或多個 AI 應用程式範本 作為本文範例和指引的基礎。 AI 應用程式範本提供易於部署且維護良好的參考實作。 它們可協助您確保 AI 應用程式的高品質起點。
架構概觀
結構的重要元件包括:
- Azure 裝載的聊天應用程式:聊天應用程式會在 Azure App 服務 中執行。
- Microsoft AI 聊天協定:通訊協定會跨 AI 解決方案和語言提供標準化的 API 合約。 聊天應用程式符合 MICROSOFT AI 聊天通訊協定,可讓評估應用程式針對符合通訊協定的任何聊天應用程式執行。
- Azure AI 搜尋:聊天應用程式會使用 Azure AI 搜尋來儲存您自己的文件中的數據。
- 範例問題產生器:此工具可以為每個檔案產生許多問題,並提供真實答案。 問題越多,評估時間越長。
- 評估工具:此工具會針對聊天應用程式執行範例問題和提示,並傳回結果。
- 檢閱工具:此工具會檢閱評估的結果。
- 差異工具:此工具會比較評估之間的答案。
當您將此評估部署到 Azure 時,會為 GPT-4 模型建立 Azure OpenAI 服務端點,其具有本身的 容量。 當您評估聊天應用程式時,重要的是評估者透過使用自身的 Azure OpenAI 資源及其對應的容量 GPT-4,來進行評估。
必要條件
Azure 訂閱。 免費建立一個
部署聊天應用程式。
這些聊天應用程式會將數據載入 Azure AI 搜尋服務資源。 評估應用程式需要此資源才能運作。 請勿完成 上一個程式的清除資源 區段。
您需要該部署的下列 Azure 資源資訊,這稱為本文中的 聊天應用程式:
- 聊天 API URI:進程結束時
azd up顯示的服務後端端點。 - Azure AI 搜尋服務 (部分機器翻譯) 需要下列值:
- 資源名稱:Azure AI 搜尋服務資源名稱,在程式中回報為
Search serviceazd up。 - 索引名稱:儲存檔之 Azure AI 搜尋服務索引的名稱。 這可以在 搜尋服務 的 Azure 入口網站 中找到。
- 資源名稱:Azure AI 搜尋服務資源名稱,在程式中回報為
聊天 API URL 可讓評估透過後端應用程式提出要求。 Azure AI 搜尋資訊可讓評估腳本使用與後端相同的部署,並載入檔。
收集此資訊之後,您就不需要再次使用 聊天應用程式 開發環境。 本文稍後會參考數次,以指出評估應用程式如何使用聊天應用程式。 除非您完成本文中的整個程序, 否則請勿刪除聊天應用程式 資源。
- 聊天 API URI:進程結束時
開發容器環境可提供完成本文所需的所有相依性。 您可以在 GitHub Codespaces (瀏覽器中) 或使用 Visual Studio Code 在本機執行開發容器。
- GitHub 帳戶
開啟開發環境
立即使用已安裝所有相依性的開發環境開始,以完成本文。 調整您的螢幕工作區,以便同時查看此文件和開發環境。
本文已針對 switzerlandnorth 評估部署使用區域進行測試。
GitHub Codespaces 會使用網頁版 Visual Studio Code 作爲使用者介面,執行由 GitHub 管理的開發容器。 如需最直接的開發環境,請使用 GitHub Codespaces,使得您有已預先安裝的正確開發人員工具和相依性,以便完成本文。
重要
所有 GitHub 帳戶每月可免費使用 GitHub Codespaces 最多 60 小時,並可同時運行兩個核心實例。 如需詳細資訊,請參閱 GitHub Codespaces 每月包含的儲存體和核心時數。
開始程式,在 Azure-Samples/ai-rag-chat-評估工具 GitHub 存放庫的
main分支上建立新的 GitHub 程式代碼空間。若要同時顯示開發環境和檔案,請以滑鼠右鍵按下列按鈕,然後選取 [在新視窗中 開啟連結。

在 建立代碼空間 頁面上,檢閱代碼空間組態設定,然後選取 建立新的代碼空間。
等候 Codespace 開始。 此啟動程序可能需要幾分鐘的時間。
在畫面底部的終端機中,使用 Azure 開發人員 CLI 登入 Azure:
azd auth login --use-device-code從終端機複製程式碼,然後將它貼到瀏覽器中。 遵循指示使用 Azure 帳戶進行驗證。
為評估應用程式佈建必要的 Azure 資源 Azure OpenAI 服務:
azd up此
AZD命令不會部署評估應用程式,但會創建 Azure OpenAI 資源,並且要求必須有GPT-4部署才能在本地開發環境中執行評估。
本文中的其餘工作會在此開發容器的內容中進行。
GitHub 存放庫的名稱會出現在搜尋列中。 此視覺指標可協助您區分評估應用程式與聊天應用程式。 本文中,此 ai-rag-chat-evaluator 存放庫稱為 評估應用程式。

準備環境值和組態資訊
使用您在評估應用程式 必要條件 期間收集的資訊,更新環境值和組態資訊。
根據
.env.sample建立.env檔案。cp .env.sample .env執行此命令,從已部署的資源群組取得
AZURE_OPENAI_EVAL_DEPLOYMENT和AZURE_OPENAI_SERVICE所需的值。 將這些值貼到.env檔案中。azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICE將您在 必要條件 一節中收集的下列值,從聊天應用程式中用於它的 Azure AI 搜尋實例,新增到
.env檔案中。AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
使用 Microsoft AI 聊天通訊協定進行設定資訊
聊天應用程式和評估應用程式都實現了符合 Microsoft AI 聊天協定規範的開放原始碼 AI 端點 API 合約,這是一種與雲端和語言無關的協定,用於取用和評估。 當您的用戶端和中介層端點遵守此 API 規格時,您可以一致地取用並執行 AI 後端的評估。
建立名為
my_config.json的新檔案,並將下列內容複製到其中:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }評估文本會
my_results建立資料夾。overrides物件包含應用程式所需的任何組態設定。 每個應用程式都會定義自己的一組設定屬性。使用下表瞭解傳送至聊天應用程式的設定屬性的意義。
設定屬性 描述 semantic_ranker是否要使用 語意排名器,此模型會根據使用者查詢的語意相似性來重新產生搜尋結果。 我們停用本教學課程以降低成本。 retrieval_mode要使用的擷取模式。 預設值為 hybrid。temperature模型的溫度設定。 預設值為 0.3。top要傳回的搜尋結果數目。 預設值為 3。prompt_template用來根據問題和搜尋結果產生答案的提示覆寫。 seed對 GPT 模型的任何呼叫的種子值。 設定種子會導致跨評估產生更一致的結果。 將
target_url值變更為您聊天應用程式的 URI 值,這是您在 先決條件 區段中收集的值。 聊天應用程式必須符合聊天通訊協定。 URI 格式如下:https://CHAT-APP-URL/chat。 請確定通訊協定和chat路由是 URI 的一部分。
產生範例資料
若要評估新的答案,它們必須與 基礎真理 答案進行比較,這是特定問題的理想答案。 從儲存在 Azure AI 搜尋服務中聊天應用程式的檔案產生問題和解答。
將
example_input資料夾複製到名為my_input的新資料夾。在終端機中,執行下列命令來產生範例數據:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
問答組會產生並儲存在 my_input/qa.jsonl 中(JSONL 格式),作為下一個步驟中所用評估工具的輸入。 針對生產評估,您將會產生更多問答組。 此數據集會產生超過 200 個。
注意
每個來源僅產生少量問題和答案,以便您快速完成此程序。 這不是生產評估,每個來源應該有更多的問題和答案。
使用精簡提示執行第一個評估
編輯
my_config.json組態檔屬性。屬性 新值 results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txt精簡的提示是關於主旨網域的特定提示。
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].在終端機中,執行下列命令以執行評估:
python -m evaltools evaluate --config=my_config.json --numquestions=14此文稿會使用評估在 中
my_results/建立新的實驗資料夾。 資料夾包含評估的結果。檔名 描述 config.json用於評估的組態檔複本。 evaluate_parameters.json用於評估的參數。 類似於 config.json,但包含時間戳等其他元數據。eval_results.jsonl每個問題和答案,以及每個問答組的 GPT 指標。 summary.json整體結果,例如平均 GPT 計量。
使用弱提示進行第二次評估
編輯
my_config.json組態檔屬性。屬性 新值 results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txt該弱式提示沒有關於主旨領域的內容。
You are a helpful assistant.在終端機中,執行下列命令以執行評估:
python -m evaltools evaluate --config=my_config.json --numquestions=14
使用特定溫度執行第三個評估
使用允許更多創造力的提示。
編輯
my_config.json組態檔屬性。Existing 屬性 新值 Existing results_dirmy_results/experiment_ignoresources_temp09Existing prompt_template<READFILE>my_input/prompt_ignoresources.txt新增 temperature0.9預設值
temperature為 0.7。 溫度越高,答案就越有創意。ignore指令提示很短。Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!組態對象看起來應該像下列範例,不同之處在於您將
results_dir取代為您的路徑:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }在終端機中,執行下列命令以執行評估:
python -m evaltools evaluate --config=my_config.json --numquestions=14
檢閱評估結果
您根據不同的提示和應用程式設定執行三項評估。 結果會儲存在 my_results 資料夾中。 檢閱結果如何根據設定而有所不同。
使用檢閱工具來查看評估的結果。
python -m evaltools summary my_results結果看起來會像這樣:

每個值都會以數位和百分比傳回。
使用下表來瞭解值的意義。
值 描述 根據性 檢查模型的回應在多大程度上是根據事實和可驗證的信息。 如果回應實際上是準確的,並反映現實,就會被視為有基礎的。 相關性 測量模型回應與內容或提示的對齊程度。 相關的回應會直接解決使用者的查詢或語句。 連貫性 檢查模型回應的邏輯一致性。 一致的回應會維護邏輯流程,而且本身不會相互矛盾。 引文 指出回應是否以提示中所要求的格式傳回。 長度 測量回應的長度。 結果應該表示這三個評估都有很高的相關性,而
experiment_ignoresources_temp09具有最低的相關性。選取資料夾以查看評估的組態。
輸入 ctrl + C,以結束應用程式並返回終端機。
比較答案
比較評估中傳回的答案。
選取兩個要比較的評估,然後使用相同的檢閱工具來比較答案。
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09檢閱結果。 您的結果可能會有所不同。

輸入 ctrl + C,以結束應用程式並返回終端機。
進一步評估的建議
- 編輯 中的
my_input提示,以量身打造答案,例如主旨領域、長度和其他因素。 - 編輯檔案
my_config.json以變更 的參數,例如temperature、 和semantic_ranker和 ,然後重新執行實驗。 - 比較不同的答案,以瞭解提示和問題如何影響答案品質。
- 針對 Azure AI 搜尋索引中的每個文件產生個別的問題和基礎真相解答。 然後重新執行評估,以查看答案的差異。
- 藉由將需求新增至提示結尾,改變提示以指出較短或更長的答案。 例如
Please answer in about 3 sentences.
清除資源和相依性
下列步驟會逐步引導您完成清理所用資源的程序。
清除 Azure 資源
在本文中建立的 Azure 資源會向您的 Azure 訂用帳戶計費。 如果您預計未來不需要這些資源,請將其刪除,以避免產生更多費用。
若要刪除 Azure 資源並移除原始程式碼,請執行下列 Azure 開發人員 CLI 命令:
azd down --purge
清理 GitHub Codespaces 和 Visual Studio Code
刪除 GitHub Codespaces 環境可確保您能充分利用帳戶的免費每核心時數配額。
重要
如需 GitHub 帳戶權利的詳細資訊,請參閱 GitHub Codespaces 每月包含的儲存體和核心時數。
登入
GitHub Codespaces 儀錶板。 找出您目前執行的程式代碼空間,其來源為 azure-Samples/ai-rag-chat-evaluator GitHub 存放庫
。 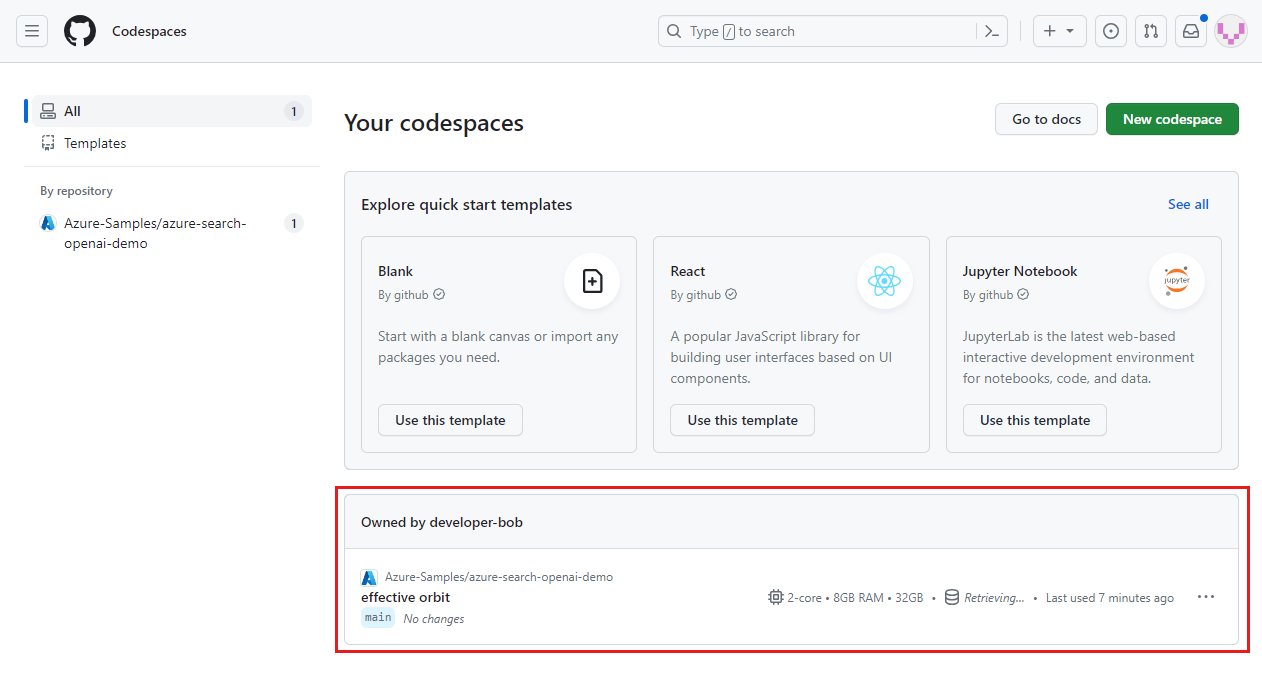
開啟 codespace 的操作選單,然後選取 [刪除]
。 ![顯示單一代碼空間「操作功能表」的螢幕快照,其中已醒目提示 [刪除] 選項。](../../ai/media/get-started-app-chat-evaluations/github-codespace-delete.png)
![顯示 [命令選擇區] 選項的螢幕快照,以重新開啟本機環境內的目前資料夾。](../../ai/media/get-started-app-chat-evaluations/reopen-local-command-palette.png)
返回聊天應用程式文章以清除這些資源。
相關內容
- 請參閱 評估存放庫。
- 請參閱 企業聊天應用程式的 GitHub 存放庫。
- 建置 聊天應用程式,使用 Azure OpenAI 的 最佳實踐解決方案架構。
- 瞭解在生成式 AI 應用程式中如何運用 Azure AI 搜尋來進行
存取控制。 - 使用 Azure API 管理建置
企業就緒的 Azure OpenAI 解決方案。 - 請參閱 azure AI 搜尋 :使用混合式擷取和排名功能來超越向量搜尋,。