使用 Apache Flink® DataStream API 將事件訊息寫入 Azure Data Lake Storage Gen2
注意
AKS 上的 Azure HDInsight 將於 2025 年 1 月 31 日退場。 請於 2025 年 1 月 31 日之前,將工作負載移轉至 Microsoft Fabric 或對等的 Azure 產品,以免工作負載突然終止。 訂用帳戶中剩餘的叢集將會停止,並會從主機移除。
在淘汰日期之前,只有基本支援可用。
重要
此功能目前為預覽功能。 Microsoft Azure 預覽版增補使用規定包含適用於 Azure 功能 (搶鮮版 (Beta)、預覽版,或尚未正式發行的版本) 的更多法律條款。 若需此特定預覽版的相關資訊,請參閱 Azure HDInsight on AKS 預覽版資訊。 如有問題或功能建議,請在 AskHDInsight 上提交要求並附上詳細資料,並且在 Azure HDInsight 社群上追蹤我們以獲得更多更新資訊。
Apache Flink 會使用檔案系統來取用並持續儲存資料,無論是應用程式的結果,還是容錯和復原。 在本文中,了解如何使用 DataStream API 將事件訊息寫入 Azure Data Lake Storage Gen2。
必要條件
- AKS 上的 HDInsight 上的 Apache Flink 叢集
- HDInsight 上的 Apache Kafka 叢集
- 您需要確保網路設定按照「在 HDInsight 上使用 Apache Kafka」上所述進行處理。 請確定 AKS 上的 HDInsight 和 HDInsight 叢集位於相同的虛擬網路中。
- 使用 MSI 存取 ADLS Gen2
- IntelliJ 用於在 AKS 虛擬網路上 HDInsight 中的 Azure VM 上進行開發
Apache Flink FileSystem 連接器
此文件系統連接器為 BATCH 和 STREAMING 提供相同的保證,其設計目的是為 STREAMING 執行提供一次語意。 如需詳細資訊,請參閱 Flink DataStream Filesystem。
Apache Kafka 連接器
Flink 提供了一個 Apache Kafka 連接器,用於從 Kafka 主題讀取資料,以及將資料寫入 Kafka 主題,並具有剛好一次的保證。 如需詳細資訊,請參閱Apache Kafka 連接器。
建置 Apache Flink 的專案
在 IntelliJ IDEA 開啟 pom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ADLS Gen2 接收器程式
abfsGen2.java
注意
將 HDInsight 叢集上的 Apache Kafka bootStrapServers 取代為您自己適用於 Kafka 3.2 的代理程式
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
封裝 JAR 並提交至 Apache Flink。
將 jar 上傳至 ABFS。
在
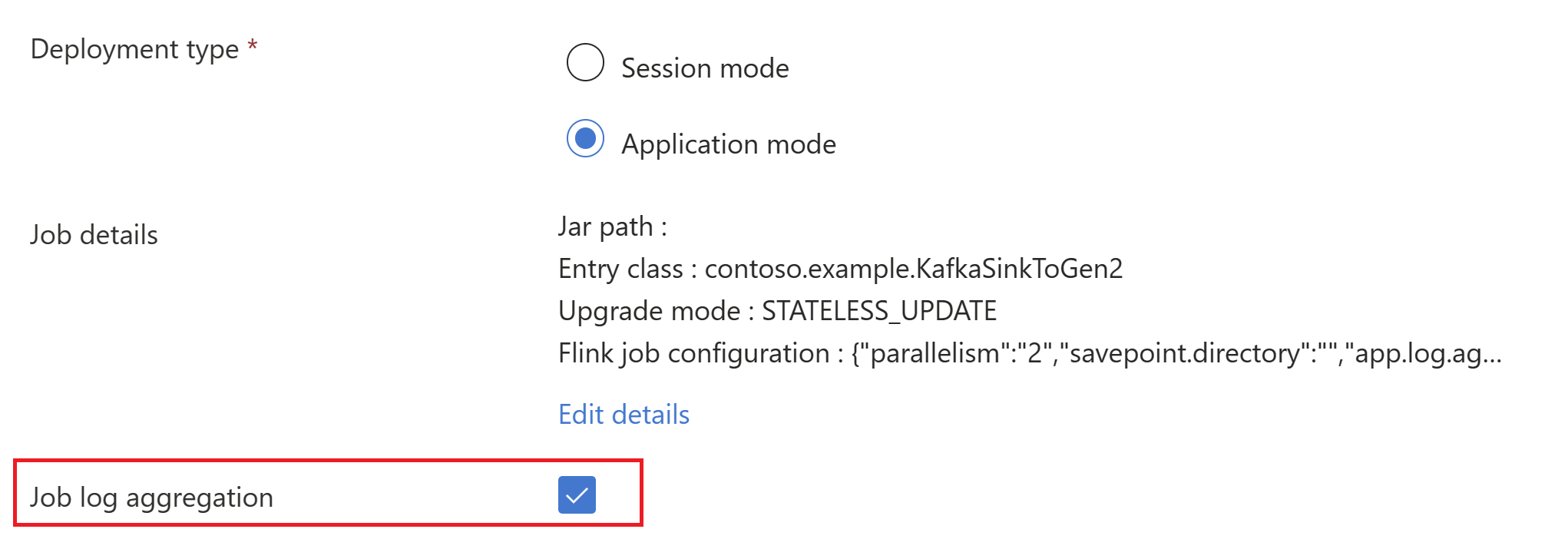
AppMode叢集建立中傳遞作業 JAR 資訊。
注意
請務必將 classloader.resolve-order 新增為 'parent-first',並將 hadoop.classpath.enable 新增為
true選取 [作業記錄彙總] 以將作業記錄推送至儲存體帳戶。
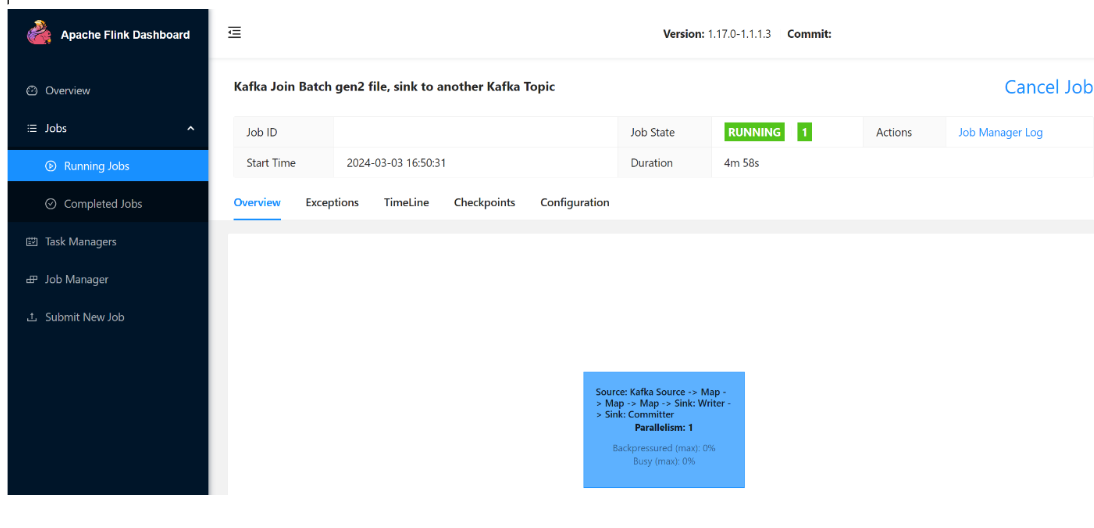
您可以看到作業正在執行。




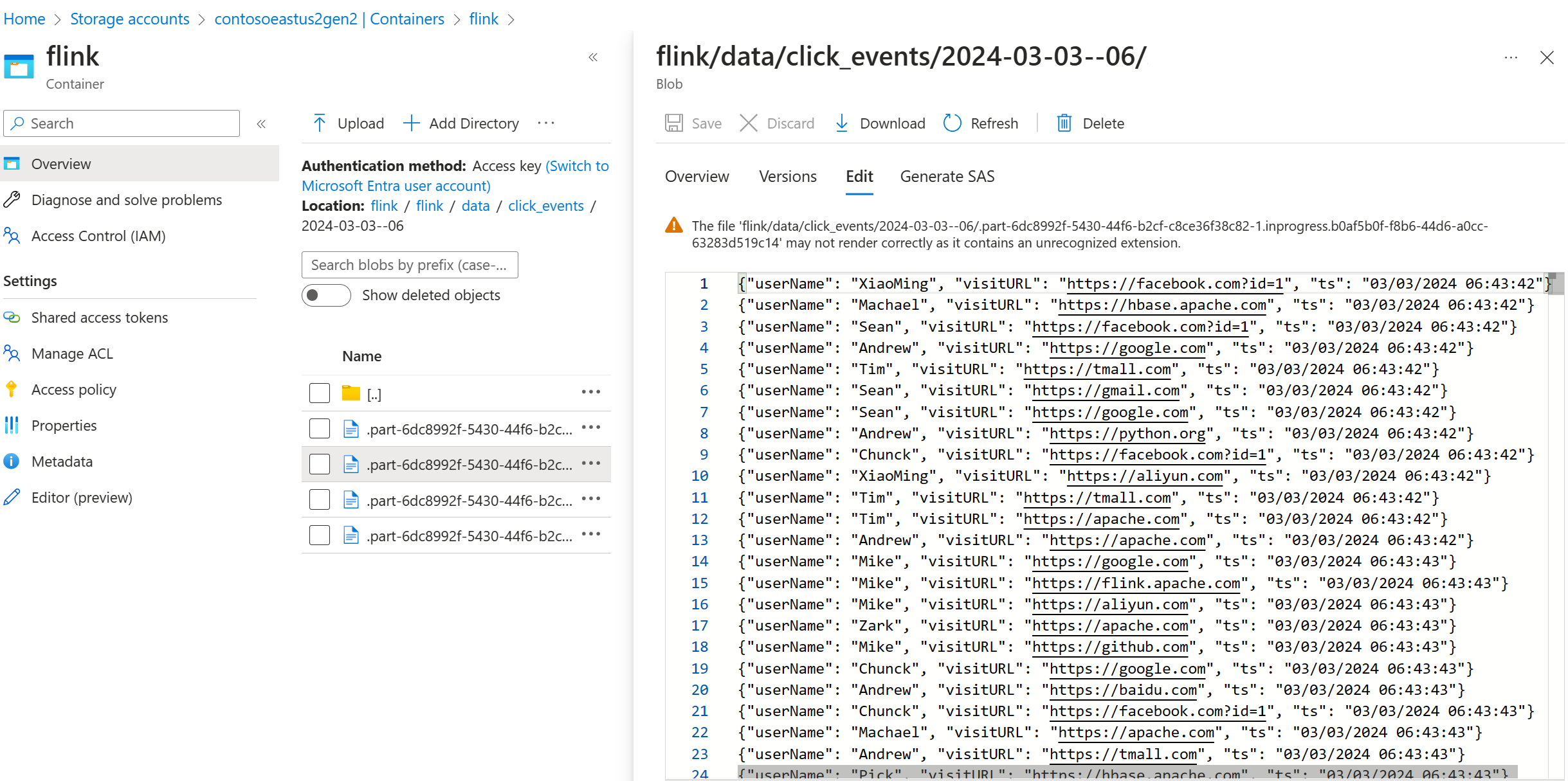
驗證 ADLS Gen2 上的串流資料
我們看到 click_events 串流至 ADLS Gen2。

您可以指定滾動原則,以在下列三個條件中輪替進行中的元件檔案:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
參考
- Apache Kafka 連接器
- Flink DataStream Filesystem
- Apache Flink 網站
- Apache、Apache Kafka、Kafka、Apache Flink、Flink 和相關聯的開放原始碼專案名稱是 Apache Software Foundation (ASF) 的商標。