在 AKS 上 HDInsight 的 Apache Flink® 上建立 Apache Kafka® 資料表
注意
AKS 上的 Azure HDInsight 將於 2025 年 1 月 31 日退場。 請於 2025 年 1 月 31 日之前,將工作負載移轉至 Microsoft Fabric 或對等的 Azure 產品,以免工作負載突然終止。 訂用帳戶中剩餘的叢集將會停止,並會從主機移除。
在淘汰日期之前,只有基本支援可用。
重要
此功能目前為預覽功能。 Microsoft Azure 預覽版增補使用規定包含適用於 Azure 功能 (搶鮮版 (Beta)、預覽版,或尚未正式發行的版本) 的更多法律條款。 若需此特定預覽版的相關資訊,請參閱 Azure HDInsight on AKS 預覽版資訊。 如有問題或功能建議,請在 AskHDInsight 上提交要求並附上詳細資料,並且在 Azure HDInsight 社群上追蹤我們以獲得更多更新資訊。
使用此範例了解如何在 Apache FlinkSQL 上建立 Kafka 資料表。
必要條件
Apache Flink 上的 Kafka SQL 連接器
Kafka 連接器可讓您從 Kafka 主題讀取資料,並將資料寫入其中。 如需詳細資訊,請參閱 Apache Kafka SQL 連接器。
在 Flink SQL 上建立 Kafka 資料表
在 HDInsight Kafka 上準備主題和資料
使用 weblog.py 準備訊息
import random
import json
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://google.com',
'https://facebook.com?id=1',
'https://tmall.com',
'https://baidu.com',
'https://taobao.com',
'https://aliyun.com',
'https://apache.com',
'https://flink.apache.com',
'https://hbase.apache.com',
'https://github.com',
'https://gmail.com',
'https://stackoverflow.com',
'https://python.org'
]
def main():
while True:
if random.randrange(10) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Kafka 主題的管線
sshuser@hn0-contsk:~$ python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
其他命令:
-- create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- consume topic
sshuser@hn0-contsk:~$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Tom", "visitURL": "https://stackoverflow.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Chunck", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Chunck", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Andrew", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Pick", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Mike", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Zheng Hu", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Luke", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:44"}
Apache Flink SQL 用戶端
有關如何為 Flink SQL 用戶端使用安全殼層的詳細指示。
將 Kafka SQL 連接器和相依性下載至 SSH
我們在下列步驟中即將使用 Kafka 3.2.0 相依性,您必須根據 HDInsight 叢集上的 Kafka 版本來更新命令。
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.2.0/kafka-clients-3.2.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.0/flink-connector-kafka-1.17.0.jar
連線至 Apache Flink SQL 用戶端
現在讓我們使用 Kafka SQL 用戶端 Jar 連線到 Flink SQL 用戶端。
msdata@pod-0 [ /opt/flink-webssh ]$ bin/sql-client.sh -j flink-connector-kafka-1.17.0.jar -j kafka-clients-3.2.0.jar
在 Apache Flink SQL 上建立 Kafka 資料表
讓我們在 Flink SQL 上建立 Kafka 資料表,然後選取 Flink SQL 上的 Kafka 資料表。
您必須更新下列程式碼片段中的 Kafka 啟動程序伺服器 IP。
CREATE TABLE KafkaTable (
`userName` STRING,
`visitURL` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = '<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092',
'properties.group.id' = 'my_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
select * from KafkaTable;
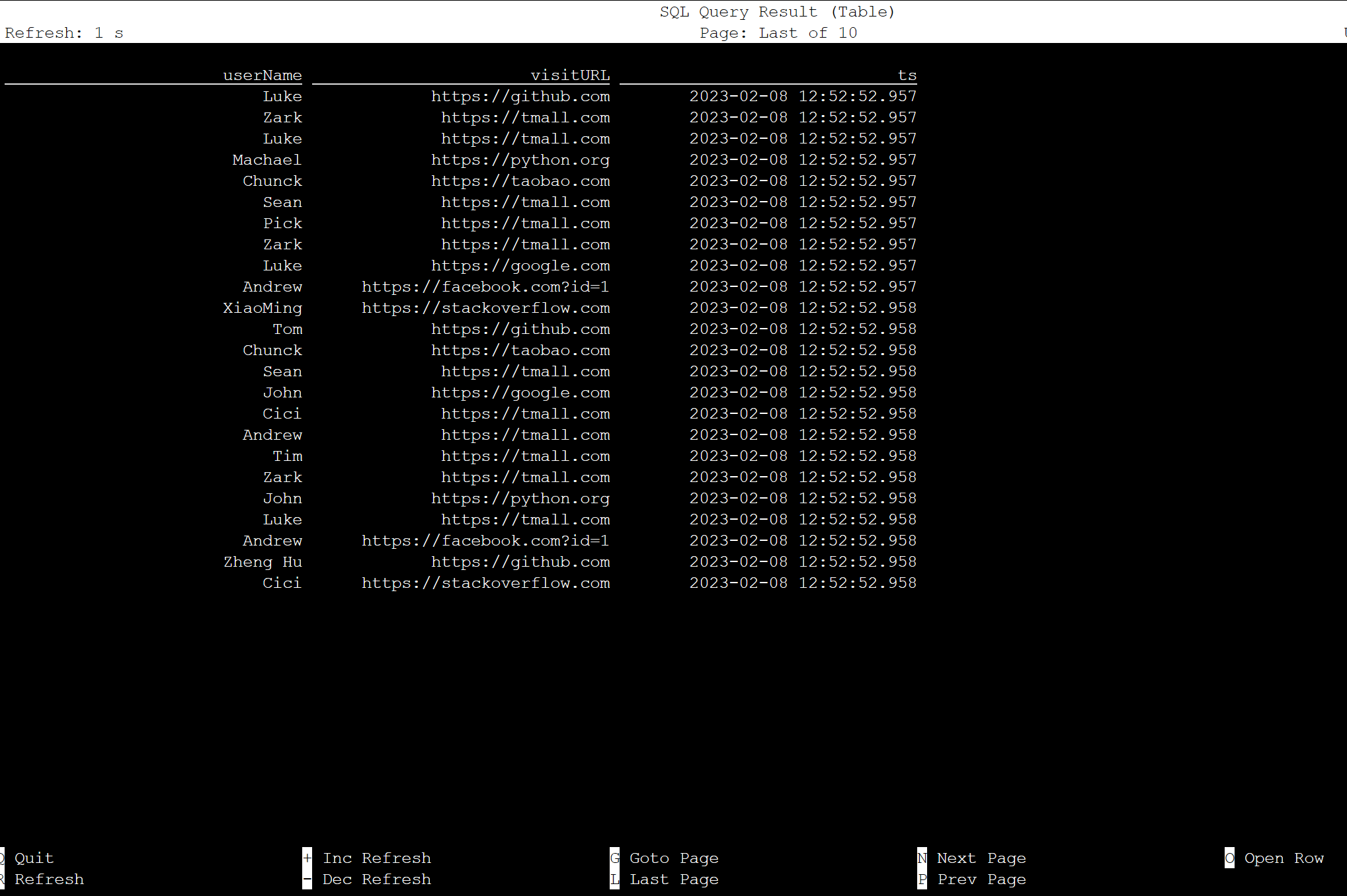
產生 Kafka 訊息
現在讓我們使用 HDInsight Kafka 產生相同個主題的 Kafka 訊息。
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Apache Flink SQL 上的資料表
您可以監視 Flink SQL 上的資料表。
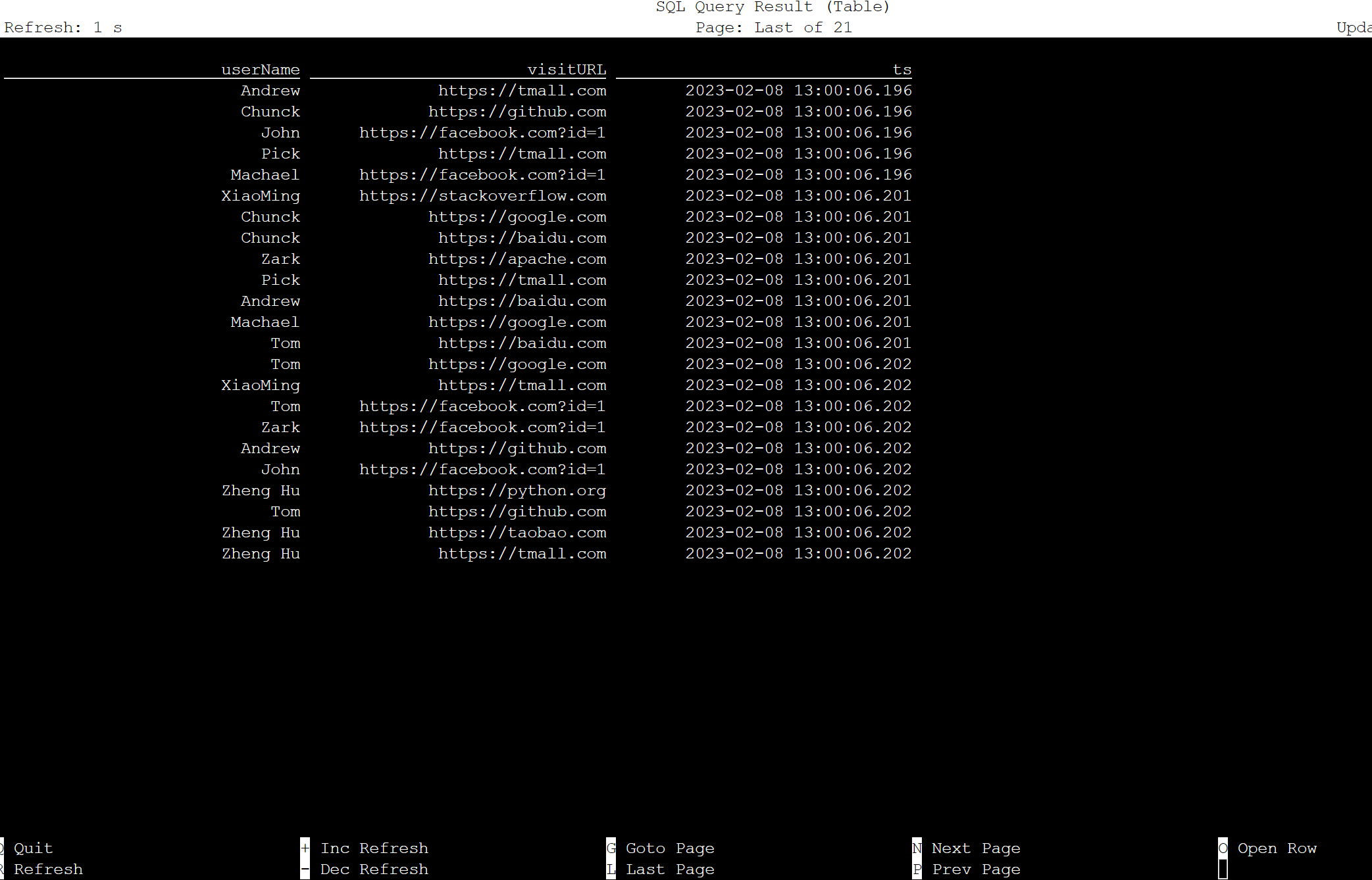
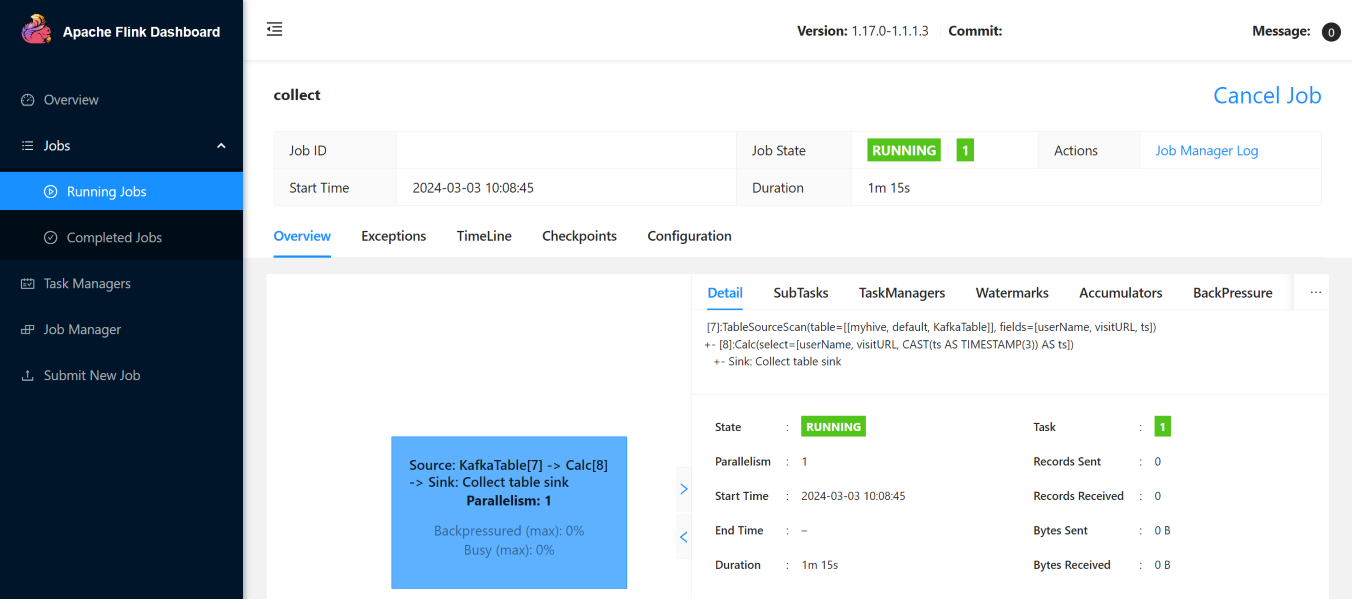
以下是在 Flink Web UI 上的串流作業。
參考
- Apache Kafka SQL 連接器
- Apache、Apache Kafka、Kafka、Apache Flink、Flink 和相關聯的開放原始碼專案名稱是 Apache Software Foundation (ASF) 的商標。