使用 Azure Toolkit for IntelliJ (預覽) 對失敗的 Spark 作業進行偵錯
此文章將逐步指引如何使用 Azure Toolkit for IntelliJ 中的 HDInsight 工具,執行 Spark 失敗偵錯應用程式。
必要條件
Oracle Java Development Kit。 本教學課程使用 Java 8.0.202 版。
IntelliJ IDEA。 此文章使用 IntelliJ IDEA Community 2019.1.3 (英文)。
Azure Toolkit for IntelliJ。 請參閱安裝 Azure Toolkit for IntelliJ。
連線到 HDInsight 叢集。 請參閱連線到 HDInsight 叢集。
Microsoft Azure 儲存體總管。 請參閱下載 Microsoft Azure 儲存體總管。
使用偵錯範本建立專案
建立 spark2.3.2 專案以繼續進行失敗偵錯,並取得此文件中的失敗作業偵錯範例檔案。
開啟 IntelliJ IDEA。 開啟 [New Project] \(新增專案\) 視窗。
a. 選取左窗格中的 [Azure Spark/HDInsight]。
b. 從主視窗選取 [Spark Project with Failure Task Debugging Sample(Preview)(Scala)] \(具有失敗工作偵錯範例的 Spark 專案 (預覽) (Scala)\)。
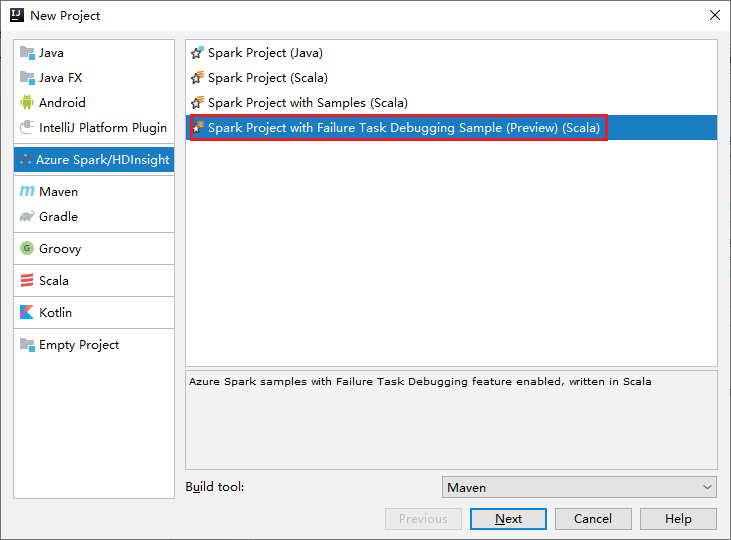
c. 選取 [下一步]。
在 [New Project] \(新增專案\) 視窗中,執行下列步驟:
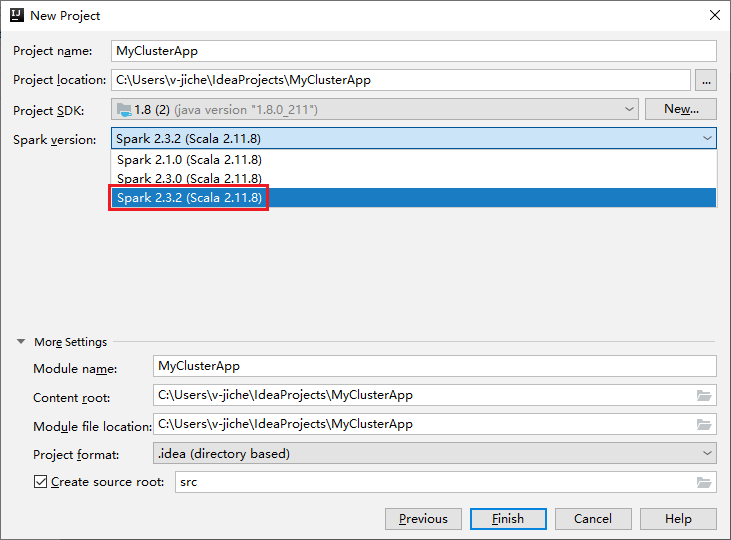
a. 輸入專案名稱和專案位置。
b. 在 [Project SDK] \(專案 SDK\) 下拉式清單中,針對 [Spark 2.3.2] 叢集選取 [Java 1.8]。
c. 在 [Spark Version] \(Spark 版本\) 下拉式清單中,選取 [Spark 2.3.2 (Scala 2.11.8)]。
d. 選取 [完成]。
選取 src>main \(主要\)>scala 以在專案中開啟您的程式碼。 此範本使用 AgeMean_Div() 指令碼。
在 HDInsight 叢集上執行 Spark Scala/JAVA 應用程式
建立 spark Scala/JAVA 應用程式,然後執行下列步驟,在 Spark 叢集上執行應用程式:
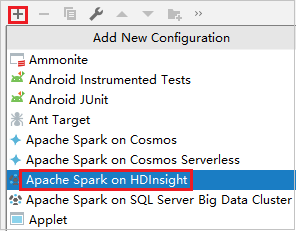
按一下 [Add Configuration] \(新增設定\) 以開啟 [Run/Debug Configurations] \(執行/偵錯設定\) 視窗。

在 [Run/Debug Configurations] \(執行/偵錯設定) 對話方塊中,選取加號 (+)。 然後,選取 [Apache Spark on HDInsight] \(HDInsight 上的 Apache Spark\) 選項。
切換至 [在叢集中遠端執行] 索引標籤。輸入 [Name] \(名稱\)、[Spark cluster] \(Spark 叢集\) 和 [Main class name] \(主要類別名稱\)。 我們的工具支援使用執行程式進行偵錯。 numExecutors,預設值為 5,而且您最好不會設定高於 3。 若要減少執行階段,您可以將 spark.yarn.maxAppAttempts 新增至 [job Configurations] \(作業設定\),並將值設定為 1。 按一下 [OK] \(確定\) 按鈕以儲存設定。
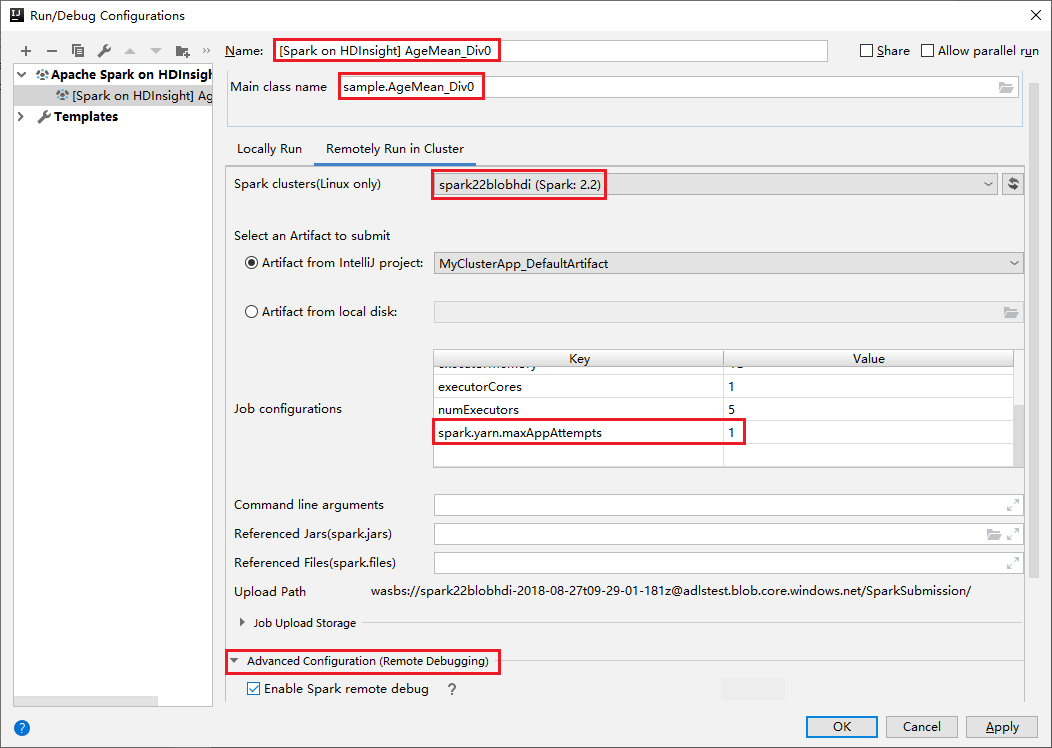
設定現在會使用您提供的名稱儲存。 若要檢視設定詳細資訊,請選取設定名稱。 若要進行變更,請選取 [Edit Configurations] \(編輯設定\)。
完成組態設定之後,您可以針對遠端叢集執行專案。

您可以從輸出視窗檢查應用程式識別碼。

下載失敗的作業設定檔
如果作業提交失敗,您可以將失敗的作業設定檔下載到本機電腦,以進行進一步偵錯。
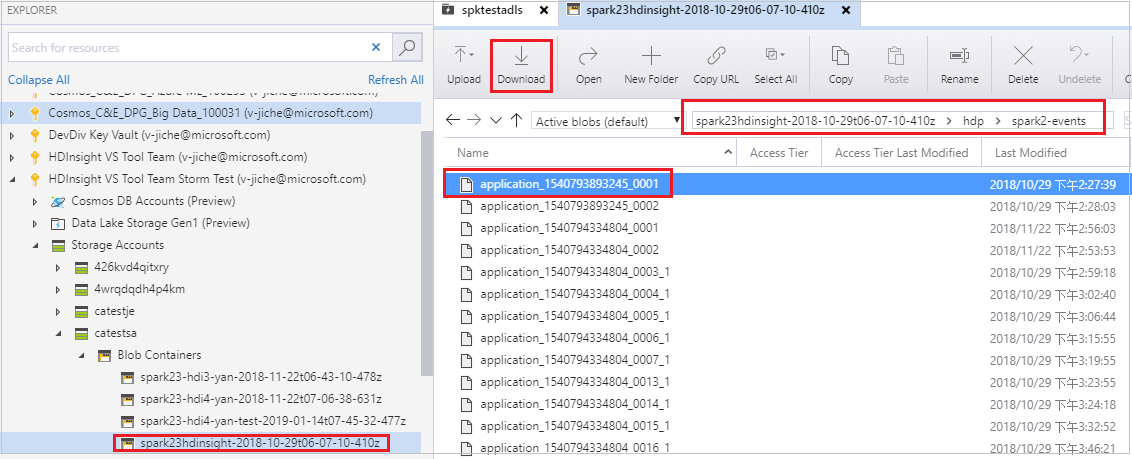
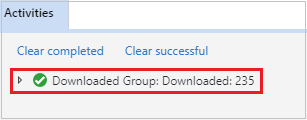
開啟 [Microsoft Azure 儲存體總管]、找出失敗作業之叢集的 HDInsight 帳戶、從對應的位置 (\hdp\spark2-events\.spark-failures\<應用程式識別碼>) 將失敗的作業資源下載至本機資料夾。[活動] 視窗將顯示下載進度。
設定本機偵錯環境並在失敗時進行偵錯
開啟原始專案或建立新的專案,並將它與原來的原始程式碼產生關聯。目前僅支援 spark2.3.2 版本進行失敗偵錯。
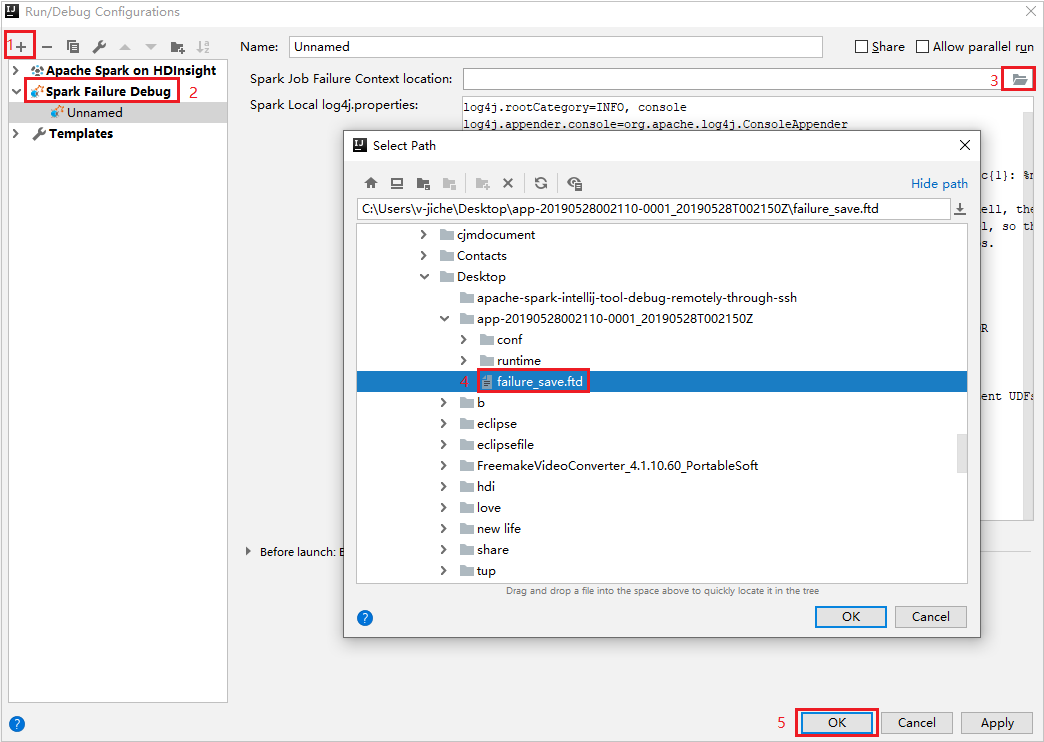
在 IntelliJ IDEA 中,建立 [Spark Failure Debug] \(Spark 失敗偵錯\) 設定檔,並針對 [Spark Job Failure Context location] \(Spark 作業失敗內容位置\) 欄位,選取先前下載之失敗作業資源中的 FTD 檔案。
按一下工具列中的本機執行按鈕,錯誤將顯示於 [Run] \(執行\) 視窗中。
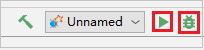
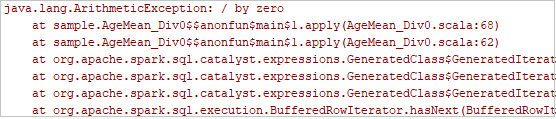
按照記錄指示設定中斷點,然後按一下本機偵錯按鈕以執行本機偵錯,就像您在 IntelliJ 中的一般 Scala/Java 專案一樣。
偵錯之後,如果專案成功完成,您可以將失敗的作業重新提交至 HDInsight 叢集上的 Spark。
下一步
案例
- Apache Spark 和 BI:在 HDInsight 中搭配 BI 工具使用 Spark 進行互動式資料分析
- Apache Spark 和機器學習服務:在 HDInsight 中利用 HVAC 資料使用 Spark 分析建築物溫度
- Apache Spark 和機器學習服務:在 HDInsight 中使用 Spark 預測食品檢查結果
- 在 HDInsight 中使用 Apache Spark 進行網站記錄分析
建立及執行應用程式
工具和延伸模組
- 使用 Azure Toolkit for IntelliJ 為 HDInsight 叢集建立 Apache Spark 應用程式
- 使用 Azure Toolkit for IntelliJ 透過 VPN 遠端偵錯 Apache Spark 應用程式
- 使用 Azure Toolkit for Eclipse 中的 HDInsight 工具建立 Apache Spark 應用程式
- 在 HDInsight 上搭配使用 Apache Zeppelin Notebook 和 Apache Spark 叢集
- HDInsight 的 Apache Spark 叢集中 Jupyter Notebook 可用的核心
- 搭配 Jupyter Notebook 使用外部套件
- 在電腦上安裝 Jupyter 並連接到 HDInsight Spark 叢集