使用企業安全性套件在 HDInsight 中設定 Spark SQL 的 Apache Ranger 原則
本文說明如何在 HDInsight 中使用企業安全性套件設定 Spark SQL 的 Apache Ranger 原則。
在本文中,您將學會如何:
- 建立 Apache Ranger 原則。
- 確認套用的 Ranger 原則。
- 套用設定適用於 Spark SQL 的 Apache Ranger 的指導方針。
必要條件
- HDInsight 5.1 版中具有 企業安全性套件的 Apache Spark 叢集
連線 至 Apache Ranger 系統管理 UI
從瀏覽器,使用 URL
https://ClusterName.azurehdinsight.net/Ranger/連線到 Ranger 管理使用者介面。變更
ClusterName為Spark叢集的名稱。使用您的 Microsoft Entra 管理員認證登入。 Microsoft Entra 系統管理員認證與 HDInsight 叢集認證或 Linux HDInsight 節點安全殼層 (SSH) 認證不同。
建立網域使用者
如需如何建立 sparkuser 網域用戶的資訊,請參閱 使用 ESP 建立 HDInsight 叢集。 在生產案例中,網域用戶來自您的 Microsoft Entra 租使用者。
建立 Ranger 原則
在本節中,您會建立兩個 Ranger 原則:
- 從 Spark SQL 存取的
hivesampletable存取原則 - 模糊化數據行的遮罩原則
hivesampletable
建立 Ranger 存取原則
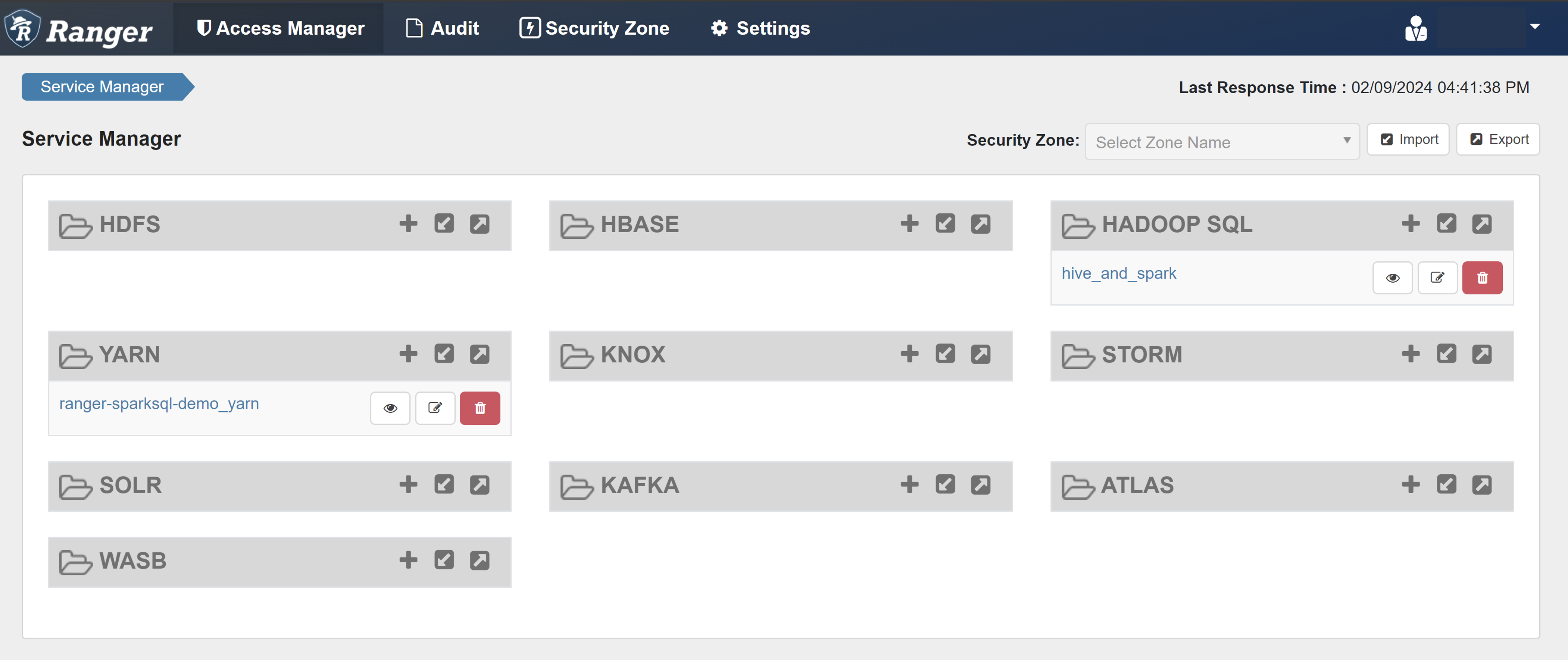
開啟 Ranger 系統管理員 UI。
在 [HADOOP SQL] 下,選取 [hive_and_spark]。
在 [存取] 索引標籤上,選取 [新增原則]。
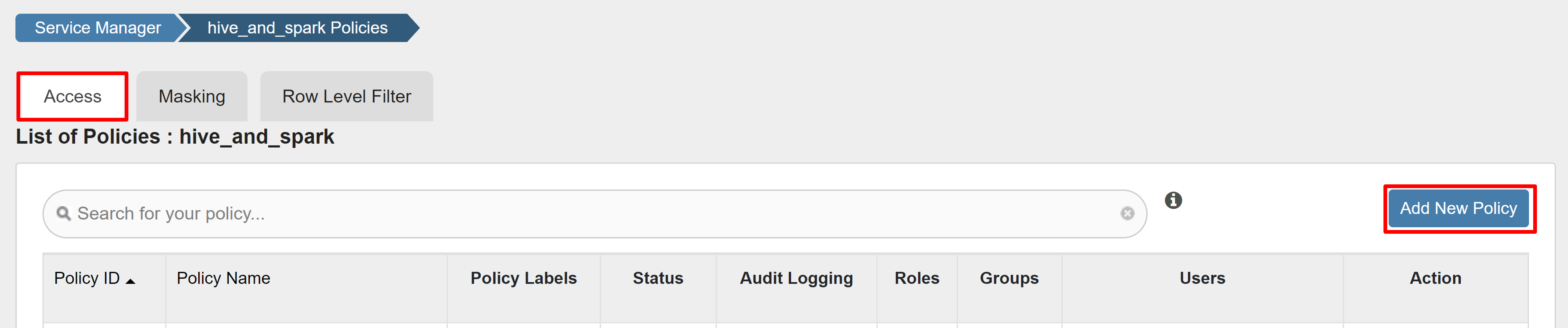
輸入下列值:
屬性 值 原則名稱 read-hivesampletable-all database 預設值 table hivesampletable column * 選取使用者 sparkuser權限 select 
如果未自動填入 [選取使用者] 的網域使用者,請稍候片刻,讓 Ranger 與 Microsoft Entra ID 同步。
選取 [ 新增 ] 以儲存原則。
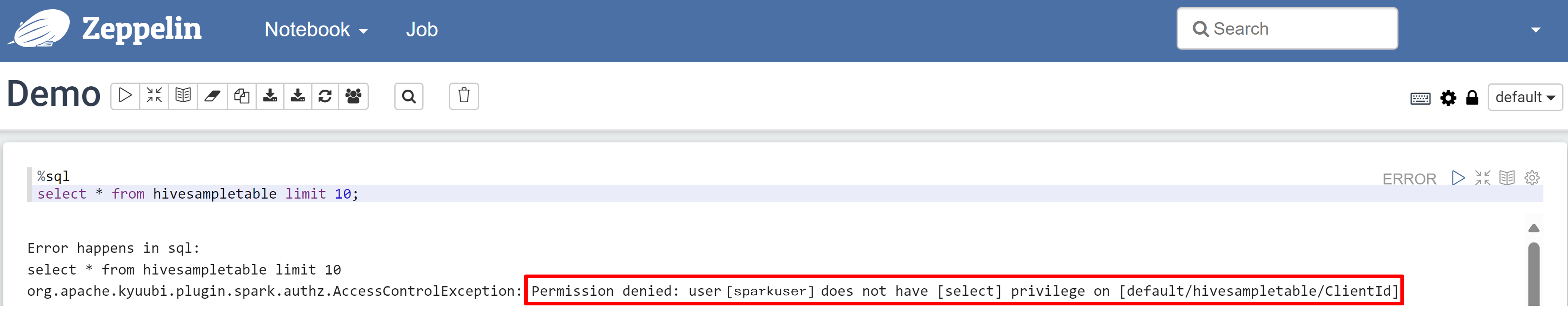
開啟 Zeppelin 筆記本,然後執行下列命令來驗證原則:
%sql select * from hivesampletable limit 10;以下是套用原則之前的結果:
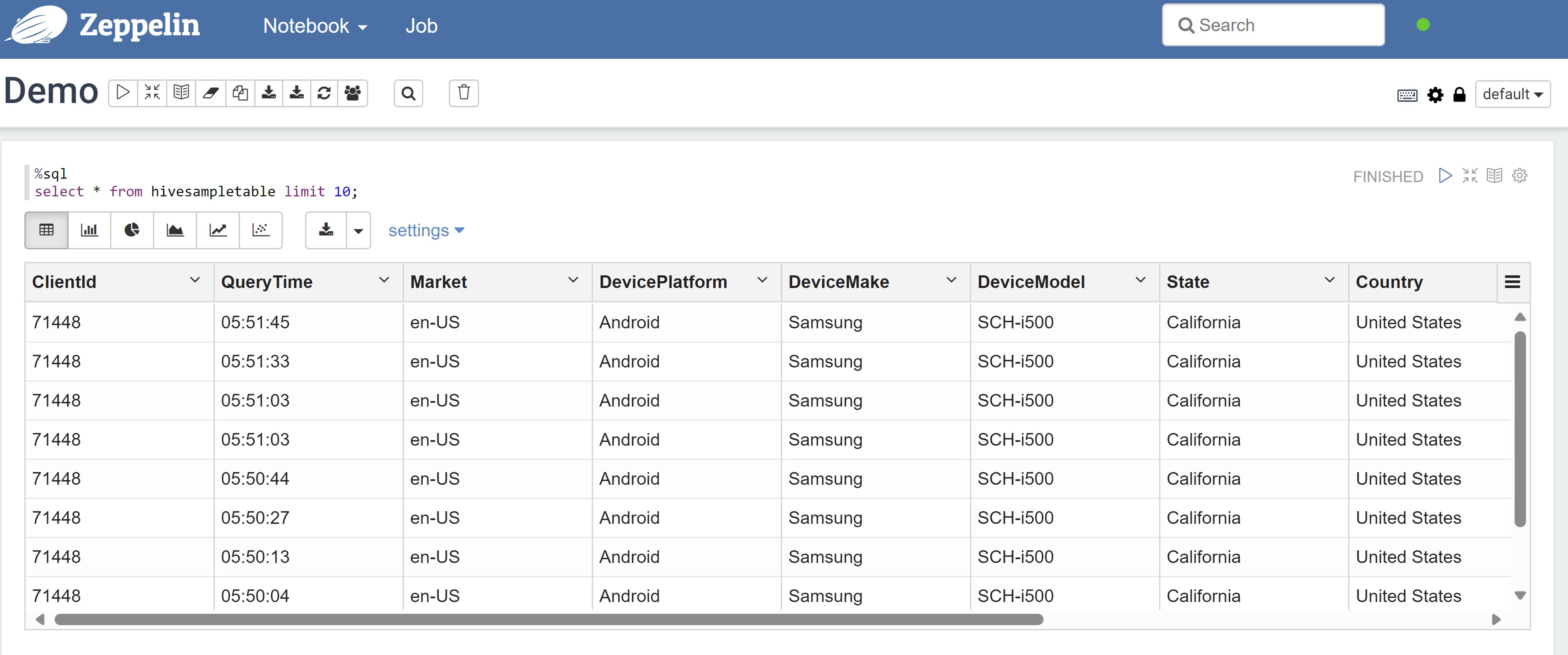
以下是套用原則之後的結果:




建立 Ranger 遮罩原則
下列範例示範如何建立原則來遮罩數據行:
在 [ 遮罩] 索引 標籤上,選取 [ 新增原則]。
輸入下列值:
屬性 值 原則名稱 mask-hivesampletable Hive 資料庫 預設值 Hive 數據表 hivesampletable Hive 資料行 devicemake 選取使用者 sparkuser存取類型 select 選取遮罩選項 雜湊 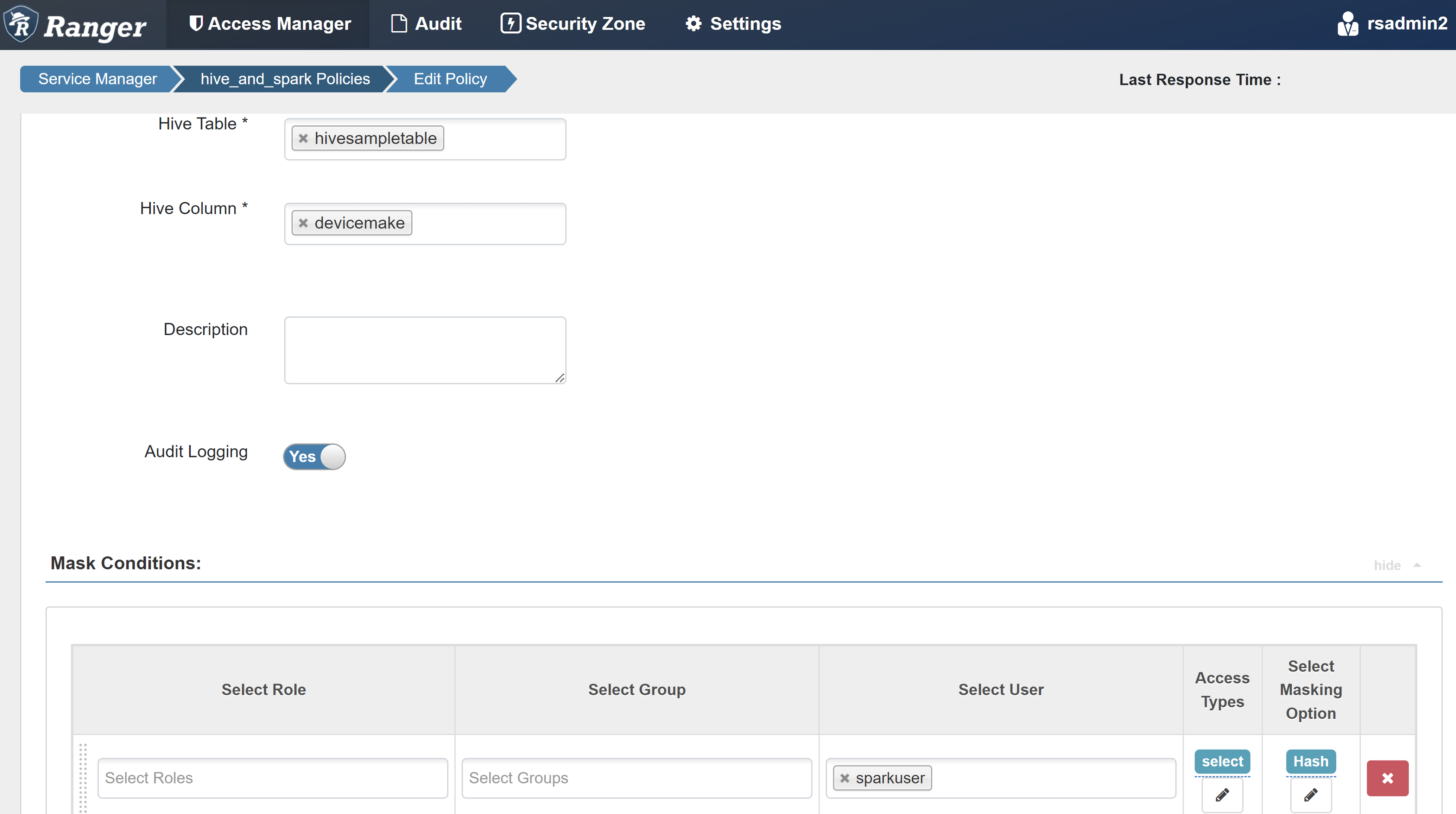
選取 [ 儲存] 以儲存原則。
開啟 Zeppelin 筆記本,然後執行下列命令來驗證原則:
%sql select clientId, deviceMake from hivesampletable;



注意
根據預設,Hive 和 Spark SQL 的原則在 Ranger 中很常見。
套用適用於 Spark SQL 的 Apache Ranger 設定指導方針
下列案例會探索使用新的 Ranger 資料庫和使用現有 Ranger 資料庫來建立 HDInsight 5.1 Spark 叢集的指導方針。
案例 1:建立 HDInsight 5.1 Spark 叢集時,使用新的 Ranger 資料庫
當您使用新的 Ranger 資料庫建立叢集時,包含 Hive 和 Spark Ranger 原則的相關 Ranger 存放庫會以 Ranger 資料庫中的 Hadoop SQL 服務名稱 hive_and_spark 建立。

如果您編輯原則,這些原則會同時套用至 Hive 和 Spark。
請考慮下列幾點:
如果您有兩個與 Hive 相同名稱的中繼存放區資料庫 (例如 DB1) 和 Spark (例如 DB1) 目錄:
- 如果 Spark 使用 Spark 目錄 (
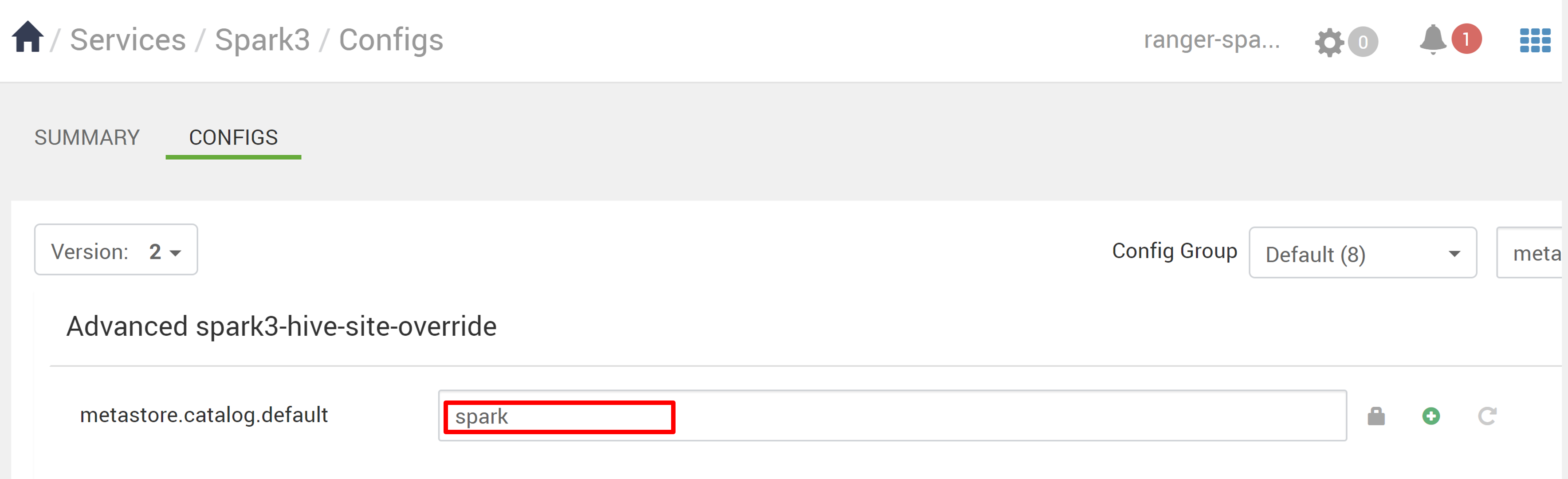
metastore.catalog.default=spark),則原則會套用至 Spark 目錄的 DB1 資料庫。 - 如果 Spark 使用 Hive 目錄 (
metastore.catalog.default=hive),則原則會套用至 Hive 目錄的 DB1 資料庫。
從 Ranger 的觀點來看,無法區分 Hive 和 Spark 目錄的 DB1 。
在這種情況下,建議您:
- 針對Hive和Spark使用Hive目錄。
- 維護Hive和Spark目錄的不同資料庫、資料表和數據行名稱,讓原則不會套用至跨目錄的資料庫。
- 如果 Spark 使用 Spark 目錄 (
如果您使用Hive和Spark的Hive目錄,請考慮下列範例。
假設您使用目前的 xyz 使用者透過 Hive 建立名為 table1 的數據表。 它會建立名為 table1.db 其擁有者是 xyz 使用者的 Hadoop 分散式文件系統 (HDFS) 檔案。
現在假設您使用使用者 abc 來啟動 Spark SQL 工作階段。 在使用者 abc 的這個工作階段中,如果您嘗試將任何專案 寫入 table1,它就會因為數據表擁有者為 xyz 而失敗。
在這種情況下,建議您在Hive和Spark SQL中使用相同的使用者來更新數據表。 該用戶應該有足夠的許可權來執行更新作業。
案例 2:在建立 HDInsight 5.1 Spark 叢集時,使用現有的 Ranger 資料庫(含現有原則)
當您使用現有的 Ranger 資料庫建立 HDInsight 5.1 叢集時,會以下列格式再次在此資料庫上建立新的 Ranger 存放庫: hive_and_spark。

假設您已在 Hadoop SQL 服務內現有 Ranger 資料庫的名稱 oldclustername_hive 下,在 Ranger 存放庫中定義原則。 您想要在新 HDInsight 5.1 Spark 叢集中共用相同的原則。 若要達成此目標,請使用下列步驟。
注意
具有Ambari系統管理員許可權的使用者可以執行設定更新。
從新的 HDInsight 5.1 叢集開啟 Ambari UI。
移至 Spark3 服務,然後移至 [設定]。
開啟進 階 ranger-spark-security 組態。
或者,您也可以使用 SSH 在 /etc/spark3/conf 中開啟此組態。
編輯兩個組態(ranger.plugin.spark.service.name 和 ranger.plugin.spark.policy.cache.dir),以指向舊的原則存放庫 oldclustername_hive,然後儲存組態。
Ambari:

XML 檔案:
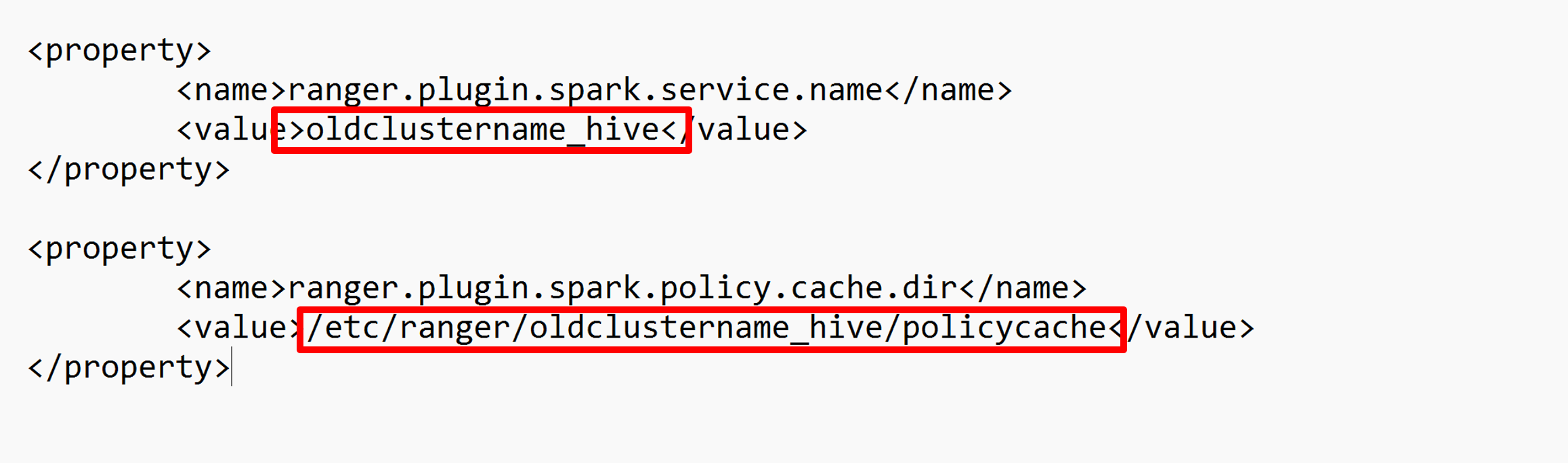
從Ambari重新啟動 Ranger 和 Spark 服務。
開啟 Ranger 管理員 UI,然後按兩下 HADOOP SQL 服務下的 [編輯] 按鈕。
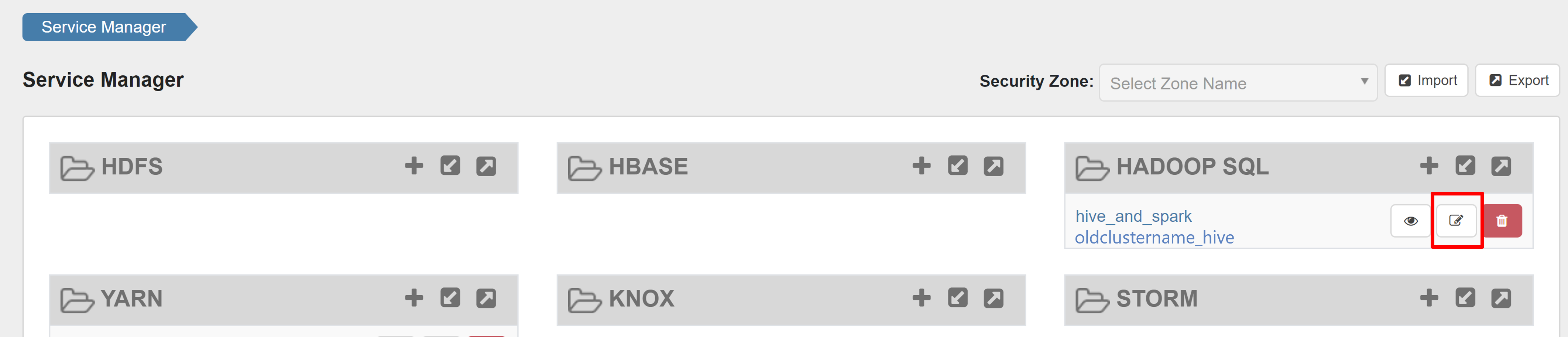
針對oldclustername_hive服務,請在 policy.download.auth.users 和 tag.download.auth.users 清單中新增 rangersparklookup 使用者,然後按兩下 [儲存]。






原則會套用至 Spark 目錄中的資料庫。 如果您要存取 Hive 目錄中的資料庫:
在Ambari中,移至Spark3>設定。
將 metastore.catalog.default 從 spark 變更為 hive。

已知問題
- 如果 Ranger 系統管理員關閉,Apache Ranger 與 Spark SQL 整合將無法運作。
- 在 Ranger 稽核記錄中,當您將滑鼠停留在 [資源 ] 資料行上時,它無法顯示您執行的整個查詢。