從 Azure Data Factory 執行批次端點
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
巨量資料需要以下服務:可協調和運作程序,將這些龐大的未經處理資料存放區精簡成可操作的商業見解。 Azure Data Factory 是一個可處理這些複雜混合式「擷取、轉換和載入」(ETL)、「擷取、載入和轉換」(ELT) 及資料整合專案的受控雲端服務。
Azure Data Factory 允許您建立管線以協調多種資料轉換作業,並將其視為單一單位來管理。 想將這項工作納入這類處理工作流程的步驟,使用批次端點是絕佳首選。
您可在本文中,了解如何仰賴 Web Invoke 活動和 REST API,在 Azure Data Factory 活動中使用批次端點。
提示
在 Fabric 中使用資料管線時,您可以使用 Azure Machine Learning 活動直接叫用批次端點。 建議您盡可能使用 Fabric 進行資料協調流程,以利用最新的功能。 Azure Data Factory 中的 Azure Machine Learning 活動只能使用來自 Azure Machine Learning V1 的資產。 如需詳細資訊,請參閱使用批次端點,從 Fabric 執行 Azure Machine Learning 模型 (預覽版)。
必要條件
部署作為批次端點的模型。 使用在批次部署中使用 MLflow 模型所建立的核心條件分類器。
Azure Data Factory 資源。 若要建立資料處理站,請遵循快速入門:使用 Azure 入口網站建立資料處理站中的步驟。
建立資料處理站之後,請在 Azure 入口網站中瀏覽至該處理站,然後選取 [啟動工作室]:
![Azure Data Factory 首頁的螢幕擷取畫面,其中標示出已醒目提示的 [開啟 Azure Data Factory Studio] 和 [啟動工作室]。](media/how-to-use-batch-adf/data-factory-home-page.png?view=azureml-api-2)
![Azure Data Factory 首頁的螢幕擷取畫面,其中標示出已醒目提示的 [開啟 Azure Data Factory Studio] 和 [啟動工作室]。](media/how-to-use-batch-adf/data-factory-home-page.png?view=azureml-api-2#lightbox)
針對批次端點執行驗證
Azure Data Factory 可使用 Web Invoke 活動叫用批次端點的 REST API。 批次端點支援 Microsoft Entra ID 的授權作業,因此對 API 提出的要求需經過適當的驗證處理。 如需詳細資訊,請參閱 Azure Data Factory 和 Azure Synapse Analytics 中的 Web 活動。
您可以使用服務主體或受控識別,對批次端點進行驗證。 我們之所以建議您使用受控識別,是因為受控識別可簡化祕密的使用過程。
您可以使用 Azure Data Factory 受控識別與批次端點通訊。 在此情況下,您只需確認您已使用受控識別部署 Azure Data Factory 資源。
管線簡介
在此範例中,我們會在 Azure Data Factory 中建立管線,該管線會透過某些資料叫用指定的批次端點。 管線會使用 REST 與 Azure Machine Learning 批次端點通訊。 若要深入了解如何使用批次端點的 REST API,請參閱建立批次端點的作業和輸入資料。
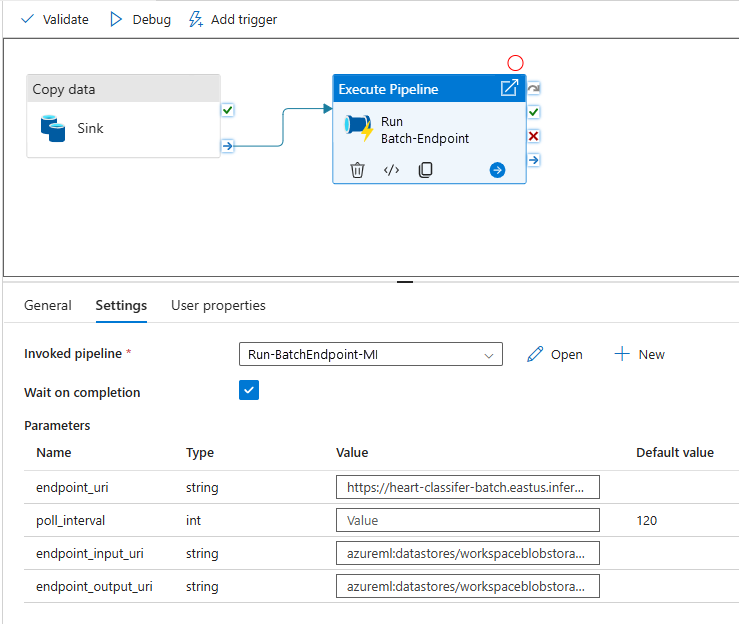
管線如下所示:

此管線包含下列活動:
執行 Batch-Endpoint:這是使用批次端點 URI 叫用端點的 Web 活動。 這麼做會傳遞資料所在位置的輸入資料 URI,以及預期的輸出檔案。
等候作業完成:這個迴圈活動會檢查所建立作業的狀態,並等候其完成,包括已完成或失敗。 此活動會依序使用下列活動:
- 檢查狀態:這個 Web 活動會查詢作業資源的狀態,以回應執行 Batch-Endpoint 活動的形式傳回。
- 等候:這個等候活動可控制作業狀態的輪詢頻率。 預設值設定為 120 (即 2 分鐘)。
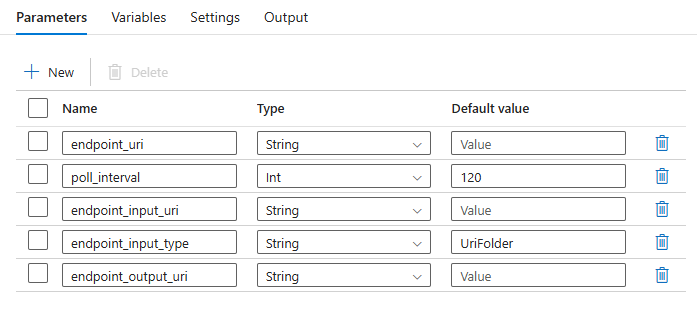
管線會要求您設定下列參數:
| 參數 | 描述 | 範例值 |
|---|---|---|
endpoint_uri |
端點評分 URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
檢查作業狀態是否完成前等待的秒數。 預設為 120。 |
120 |
endpoint_input_uri |
端點的輸入資料。 支援多種資料輸入類型。 請確定您用來執行作業的受控識別可以存取基礎位置。 或者,如果使用的是資料存放區,請確認您清楚存放區的認證。 | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
您提供的輸入資料類型。 目前批次端點支援資料夾 (UriFolder) 和檔案 (UriFile)。 預設為 UriFolder。 |
UriFolder |
endpoint_output_uri |
端點的輸出資料檔案。 這必須是 Machine Learning 工作區所連結資料存放區中的輸出檔案路徑。 不支援其他類型的 URI。 您可以使用預設的 Azure Machine Learning 資料存放區,名為 workspaceblobstore。 |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

警告
請記住,endpoint_output_uri 應該是尚不存在的檔案路徑, 否則作業會失敗,並發生路徑已存在的錯誤。
建立管線
若要在現有的 Azure Data Factory 中建立此管線並叫用批次端點,請遵循下列步驟:
請確定批次端點執行所在的計算有權掛接 Azure Data Factory 提供作為輸入的資料。 叫用端點的實體仍會授與存取權。
在此案例中,其是 Azure Data Factory。 不過,批次端點執行所在的計算必須有權掛接 Azure Data Factory 所提供的儲存體帳戶。 如需詳細資訊,請參閱存取儲存體服務。
開啟 Azure Data Factory Studio。 選取鉛筆圖示以開啟 [作者] 窗格,然後在 [Factory 資源] 底下選取加號。
依序選取 [管線] > [從管線範本匯入]。
選取 .zip 檔案。
管線的預覽會在入口網站中顯示。 選取使用此範本。
所建立的管線會使用 Run-BatchEndpoint 作為名稱。
設定批次部署的參數:
警告
提交作業前,請確認批次端點已設定預設部署。 建立的管線會叫用此端點。 必須建立和設定預設部署。
提示
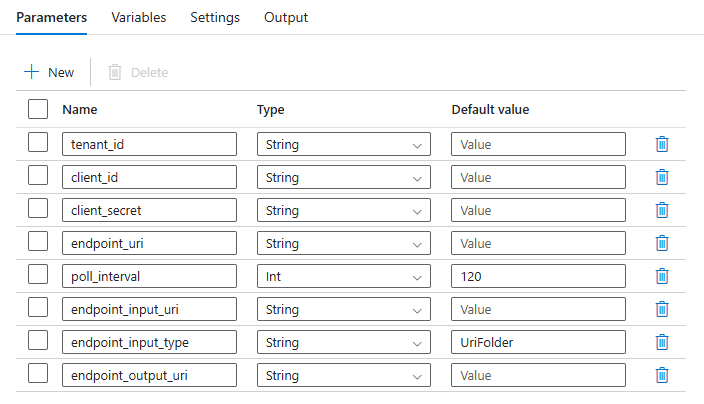
為獲得最理想的重複使用成效,請使用所建立的管線作為範本,並利用執行管線活動,從其他 Azure Data Factory 管線內呼叫該範本。 在此情況下,請勿在內部管線中設定參數,而是從外部管線傳遞參數,如下圖所示:
管線已準備就緒,可供開始使用。
限制
使用 Azure Machine Learning 批次部署時,請將以下限制納入考量:
資料輸入
- 僅支援從 Azure Machine Learning 資料存放區或 Azure 儲存體帳戶 (Azure Blob 儲存體、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2) 輸入資料。 如果您的輸入資料位於其他來源,請在執行批次作業前,使用 Azure Data Factory 複製活動,將資料接收至相容的存放區。
- 批次端點作業不會探索巢狀資料夾。 其無法與巢狀資料夾結構搭配使用。 如果資料分散在多個資料夾中,則必須將結構壓平合併。
- 您在部署中提供的評分指令碼預期會匯入作業中執行,請確認該指令碼可以處理資料。 如果模型是 MLflow,如需所支援檔案類型的限制,請參閱在批次部署中部署 MLflow 模型。
資料輸出
- 僅支援已註冊的 Azure Machine Learning 資料存放區。 建議您註冊 Azure Data Factory 所使用的儲存體帳戶作為 Azure Machine Learning 中的資料存放區。 如此一來,您就可以寫回到要讀取的相同儲存體帳戶。
- 僅支援將資料輸出至 Azure Blob 儲存體帳戶, 例如批次部署作業不支援將 Azure Data Lake Storage Gen2 作為輸出目的地。 如果您需要將資料輸出到不同位置或接收器,請在執行批次作業後,使用 Azure Data Factory 複製活動。