如何使用 Azure Machine Learning 所策展的開放原始碼基礎模型
在本文中,您將了解如何微調、評估及部署模型目錄中的基礎模型。
您可以使用模型卡片上的 [範例推斷] 表單,快速測試任何預先定型的模型,並提供您自己的範例輸入來測試結果。 此外,每個模型的模型卡片都包含模型的簡短描述,以及用於程式碼為基礎的推斷、微調和評估模型的範例連結。
如何使用您自己的測試資料評估基礎模型
您可以使用 [評估 UI] 表單或使用從模型卡片連結的程式碼型範例,根據測試資料集來評估基礎模型。
使用 Studio 進行評估
您可以針對任何基礎模型選取模型卡片上的 [評估] 按鈕,來叫用 [評估模型] 表單。
![此螢幕擷取畫面顯示使用者選取基礎模型模型卡片上的 [評估] 按鈕後,出現的評估設定表單。](media/how-to-use-foundation-models/evaluate-quick-wizard.png?view=azureml-api-2)
每個模型都可以針對模型將用於的特定推斷工作進行評估。
測試資料:
- 傳入您想要用來評估模型的測試資料。 您可以選擇上傳本機檔案 (JSONL 格式),或從工作區選取現有的已註冊資料集。
- 選取資料集之後,您必須根據工作所需的結構描述,從輸入資料對應資料行。 例如,對應文字分類之 'sentence' 和 'label' 索引鍵的相應資料行名稱

計算:
提供您想要用於微調模型的 Azure Machine Learning Compute 叢集。 評估需要在 GPU 計算上執行。 確定您想要使用的計算 SKU 有足夠的計算配額可用。
在 [評估] 表單中選取 [完成],以提交您的評估作業。 作業完成後,您可以檢視模型的評估計量。 根據評估計量,您可以決定是否要使用自己的定型資料微調模型。 此外,您可以決定是否要註冊模型,並將其部署至端點。
使用以程式碼型範例進行評估
為了讓用戶開始使用模型評估,我們已在 azureml-examples git 存放庫的評估範例中發佈了範例 (Python 筆記本和 CLI 範例)。 每個模型卡片也會連結至相應工作的評估範例
如何使用您自己的定型資料微調基礎模型
為了改善工作負載中的模型效能,您可能想要使用自己的定型資料微調基礎模型。 您可以使用 Studio 中的微調設定,或使用從模型卡片連結的程式碼型範例,輕鬆地微調這些基礎模型。
使用 Studio 進行微調
您可以針對任何基礎模型選取模型卡片上的 [微調] 按鈕,來叫用微調設定表單。
微調設定:
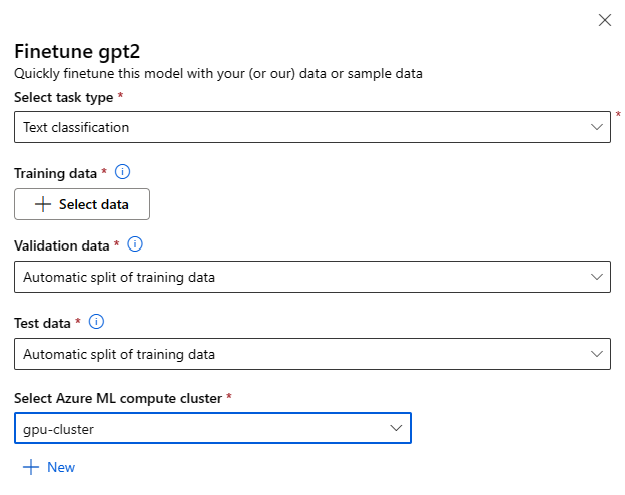
微調工作類型
- 模型目錄中的每個預先定型模型都可以針對特定的工作集進行微調 (例如:文字分類、權杖分類、問題解答)。 從下拉式清單中選取您想要使用的工作。
定型資料
傳入您想要用於微調模型的定型資料。 您可以選擇上傳本機檔案 (JSONL、CSV 或 TSV 格式),或從工作區選取現有的已註冊資料集。
選取了資料集之後,您必須根據工作所需的結構描述,從輸入資料對應資料行。 例如:對應文字分類之 'sentence' 和 'label' 索引鍵的相應資料行名稱

- 驗證資料:傳入您想要用來驗證模型的資料。 選取 [自動分割] 會保留定型資料的自動分割以進行驗證。 或者,您可以提供不同的驗證資料集。
- 測試資料:傳入您想要用來評估已微調模型的測試資料。 選取 [自動分割] 會保留訓練資料的自動分割以進行測試。
- 計算:提供您想要用來微調模型的 Azure Machine Learning Compute 叢集。 微調需要在 GPU 計算上執行。 建議您在微調時搭配 A100 / V100 GPU 使用計算 SKU。 確定您想要使用的計算 SKU 有足夠的計算配額可用。
- 在微調表單中選取 [完成],以提交微調作業。 作業完成後,您可以檢視已微調模型的評估計量。 然後,您可以透過微調作業來註冊微調後的模型輸出,並將此模型部署至端點以進行推斷。
使用程式碼型範例進行微調
目前,Azure Machine Learning 支援下列語言工作的微調模型:
- 文字分類
- 詞元分類
- 問題解答
- 摘要
- 翻譯
為了讓使用者快速開始使用微調,我們已針對 azureml-examples git 存放庫微調範例中的每個工作發佈了範例 (Python 筆記本和 CLI 範例)。 每個模型卡片也會連結至微調範例,以取得支援的微調工作。
將基礎模型部署至用於推斷的端點
您可以將基礎模型 (模型目錄中的預先定型模型和註冊到工作區後的已微調模型) 部署到可用於推斷的端點。 支援部署至無伺服器 API 和受控計算。 您可以使用 [部署 UI] 精靈或使用從模型卡片連結的程式碼型範例,來部署這些模型。
使用 Studio 進行部署
您可以針對任何基礎模型選取模型卡片上的 [部署] 按鈕,然後選取 [具有 Azure AI 內容安全無伺服器 API] 或 [沒有 Azure AI 內容安全的受控計算]
![此螢幕擷取畫面顯示基礎模型卡片上 [部署] 按鈕。](media/how-to-use-foundation-models/deploy-button.png?view=azureml-api-2#lightbox)
部署設定
由於評分指令碼和環境會自動包含在基礎模型內,因此您只需指定要使用的虛擬機器 SKU、執行個體數目,以及要用於部署的端點名稱。
![此螢幕擷取畫面顯示使用者選取 [部署] 按鈕後,出現在基礎模型卡片上的部署選項。](media/how-to-use-foundation-models/deploy-options.png?view=azureml-api-2)
共用配額
如果您要從模型目錄部署 Llama-2、Phi、Nemotron、Mistral、Dolly 或 Deci-DeciLM 模型,但沒有足夠的配額可供部署使用,Azure Machine Learning 允許您在有限的時間內使用共用配額集區中的配額。 如需共用配額的詳細資訊,請參閱 Azure 機器學習共用配額。

使用程式碼型範例進行部署
為了讓使用者快速開始使用部署和推斷,我們已在 azureml-examples git 存放庫的推斷範例中發佈了範例。 已發佈的範例包括 Python 筆記本和 CLI 範例。 每個模型卡片也會連結至即時和批次推斷的推斷範例。
匯入基礎模型
如果想要使用未包含在模型目錄中的開放原始碼模型,您可以將模型從 Hugging Face 匯入 Azure Machine Learning 工作區。 Hugging Face 是一種用於自然語言處理 (NLP) 的開放原始碼程式庫,可為常見 NLP 工作提供預先定型的模型。 模型匯入目前支援匯入下列工作的模型,只要該模型符合 Model Import Notebook 中列出的需求:
- fill-mask
- token-classification
- question-answering
- summarization
- text-generation
- text-classification
- 翻譯
- image-classification
- text-to-image
注意
來自 Hugging Face 的模型須受 Hugging Face 模型詳細資料頁面上的可用第三方授權條款之限制。 您有責任遵守模型的授權條款。
您可以選取模型目錄右上方的 [匯入] 按鈕,以使用 Model Import Notebook。
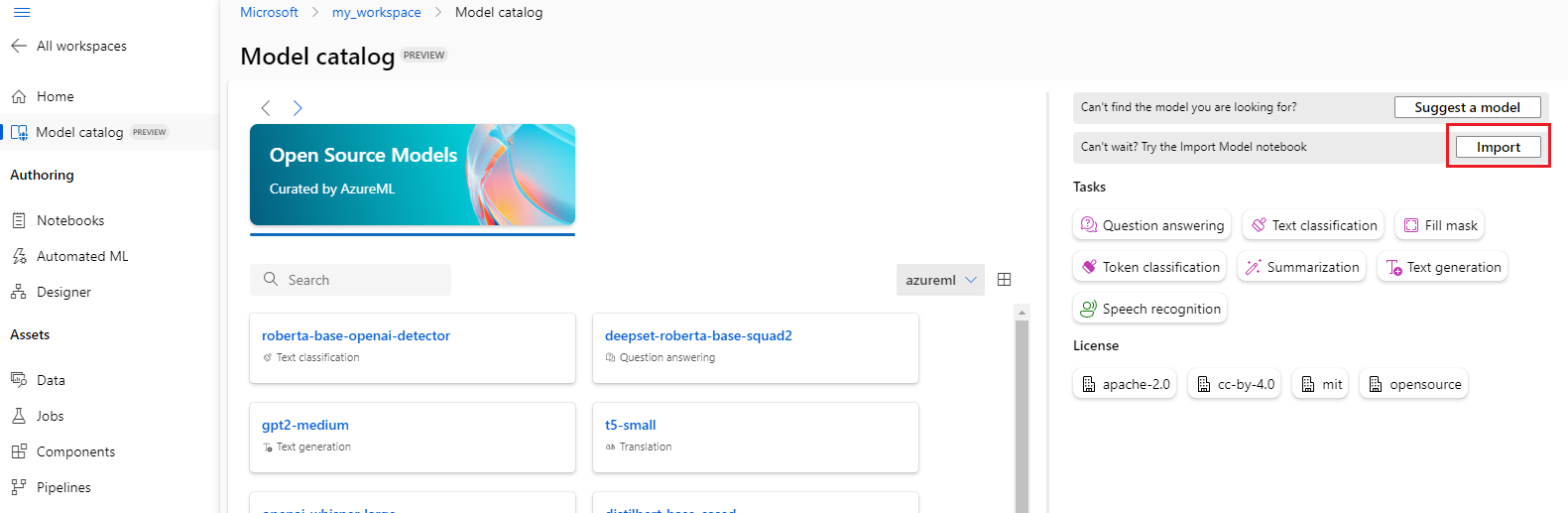
此處的 azureml-examples git 存放庫中也包含該 Model Import Notebook。
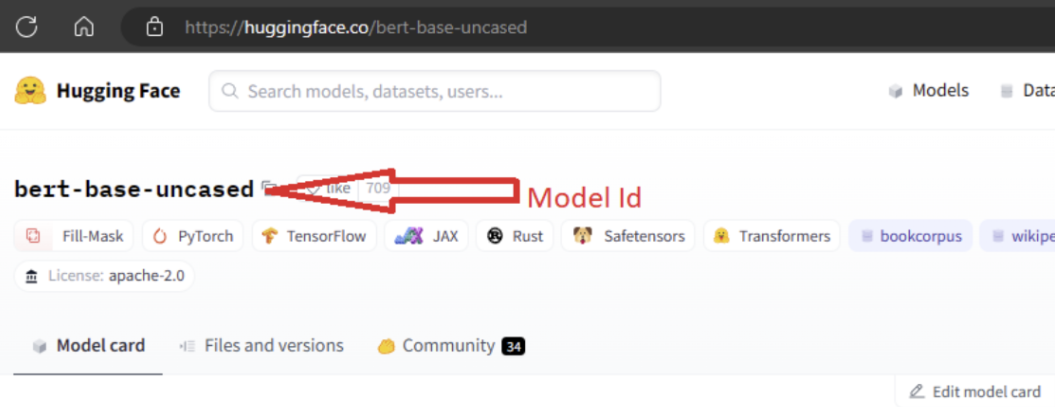
若要匯入模型,您必須傳入您想要從 Hugging Face 匯入之模型的 MODEL_ID。 瀏覽 Hugging Face 中樞上的模型,並找出要匯入的模型。 請確定模型的工作類型是支援的工作類型之一。 複製模型 ID,該 ID 可在頁面的 URI 中找到,也可以使用模型名稱旁的複製圖示進行複製。 將它指派給模型匯入筆記本中的變數 'MODEL_ID'。 例如:
您必須為要執行的模型匯入提供計算。 執行模型匯入會導致從 Hugging Face 匯入指定的模型,並註冊至您的 Azure Machine Learning 工作區。 然後,您可以微調此模型,或加以部署至端點進行推斷。
深入了解
- 探索 Azure Machine Learning 工作室中的模型目錄。 您需要 Azure Machine Learning 工作區,才能探索目錄。
- 探索模型目錄和集合