在管線中使用平行作業
適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
本文說明如何使用 CLI v2 和 Python SDK v2 在 Azure Machine Learning 管線中執行平行作業。 平行作業可藉由在功能強大的多節點計算叢集上,散發重複的工作來加速作業執行。
機器學習工程師一律在其定型或推斷工作上具有調整需求。 例如,當資料科學家提供單一指令碼來定型銷售預測模型時,機器學習工程師必須將此定型工作套用至每個個別資料商店。 此向外延展程式的挑戰包括造成延遲的長時間執行時間,以及需要手動介入才能讓工作保持執行的非預期問題。
Azure Machine Learning 平行處理的核心作業是將單一序列工作分割成迷你批次,並將這些迷你批次分派至多個計算,以平行方式執行。 平行作業可大幅減少端對端執行時間,並自動處理錯誤。 請考慮使用 Azure Machine Learning 平行作業,在分割的資料之上定型許多模型,或加速大規模批次推斷工作。
例如,在大型映像集上執行物件偵測模型的情況下,Azure Machine Learning 平行作業可讓您輕鬆地散發映像,以在特定的計算叢集上平行執行自訂程式碼。 平行處理可大幅降低時間成本。 Azure Machine Learning 平行作業也可簡化和自動化程式,使其更有效率。
必要條件
- 擁有 Azure Machine Learning 帳戶和工作區。
- 了解 Azure Machine Learning 管線。
- 安裝 Azure CLI 和
ml擴充功能。 如需詳細資訊,請參閱安裝、設定和使用 CLI (v2)。 第一次執行az ml命令時會自動安裝ml延伸模組。 - 了解如何使用 CLI v2 建立和執行 Azure Machine Learning 管線和元件。
使用平行作業步驟建立和執行管線
Azure Machine Learning 平行作業只能當做管線作業中的步驟使用。
下列範例來自在 Azure Machine Learning 範例存放庫中使用管線中的平行作業執行管線作業。
準備平行處理
此平行作業步驟需要準備。 您需要實作預先定義函式的輸入腳本。 您也需要在平行作業定義中設定屬性,以便:
- 定義並繫結您的輸入資料。
- 設定資料分割方法。
- 設定計算資源。
- 呼叫輸入腳本。
下列各節說明如何準備平行作業。
宣告輸入和資料分割設定
平行作業需要一個主要輸入以平行方式分割和處理。 主要輸入資料格式可以是表格式資料或一組檔案。
不同的資料格式具有不同的輸入類型、輸入模式和資料分割方法。 下表描述這些選項:
| 資料格式 | Input type | 輸入模式 | 資料分割方法 |
|---|---|---|---|
| 檔案清單 | mltable 或 uri_folder |
ro_mount 或 download |
依大小 (檔案數目) 或依資料分割 |
| 表格式資料 | mltable |
direct |
依大小 (估計的實體大小) 或依資料分割 |
注意
如果您使用表格式 mltable 作為主要輸入資料,您需要:
您可以使用平行作業 YAML 或 Python 中的 input_data 屬性來宣告主要輸入資料,並使用 ${{inputs.<input name>}} 來繫結資料與您平行作業的已定義 input。 然後,您會根據資料分割方法,為您的主要輸入定義資料分割屬性。
| 資料分割方法 | Attribute name | 屬性類型 | 作業範例 |
|---|---|---|---|
| 依大小 | mini_batch_size |
字串 | Iris 批次預測 |
| 依據磁碟分割 | partition_keys |
字串清單 | 柳橙汁銷售預測 |
設定用於平行處理的計算資源
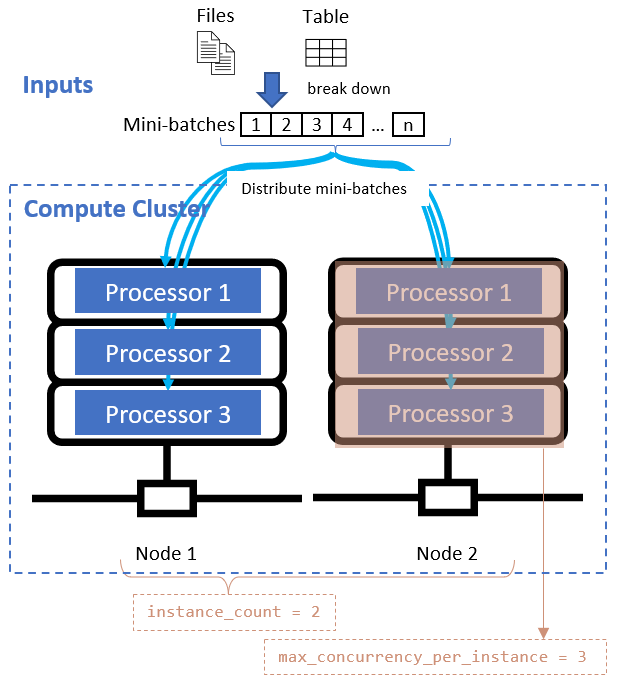
定義資料除法屬性之後,請藉由設定 instance_count 和 max_concurrency_per_instance 屬性來設定平行處理的計算資源。
| Attribute name | 類型 | 描述 | 預設值 |
|---|---|---|---|
instance_count |
整數 | 要用於作業的節點數目。 | 1 |
max_concurrency_per_instance |
整數 | 每個節點上的處理器數目。 | 針對 GPU 計算 1。 針對 CPU 計算: 核心數目。 |
這些屬性會與指定的計算叢集一起運作,如下圖所示:
呼叫輸入腳本
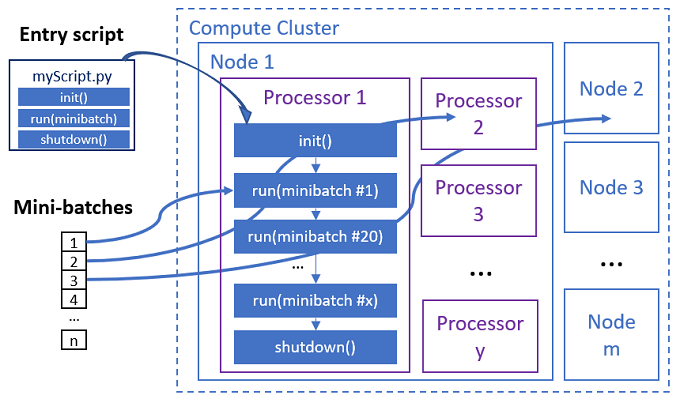
輸入腳本是單一 Python 檔案,可實作下列三個具有自訂程式碼的預先定義函式。
| 函式名稱 | 必要 | Description | 輸入 | 傳回 |
|---|---|---|---|---|
Init() |
Y | 在開始執行迷你批次之前的一般準備。 例如,使用此函式將模型載入至全域物件。 | -- | -- |
Run(mini_batch) |
Y | 實作 mini_batches 的主要執行邏輯。 | mini_batch 如果輸入資料是表格式資料,則為 pandas 資料框架,如果輸入資料是目錄,則為檔案路徑清單。 |
Dataframe、List 或 Tuple。 |
Shutdown() |
否 | 選擇性函式會先進行自訂清除,再將計算傳回集區。 | -- | -- |
重要
若要避免在 Init() 或 Run(mini_batch) 函式中剖析引數時發生例外狀況,請使用 parse_known_args 而非 parse_args。 如需具有引數剖析器的輸入腳本,請參閱 iris_score 範例。
重要
Run(mini_batch) 函式需要傳回資料框架、清單或 Tuple 項目。 平行作業會使用傳回的計數來測量該迷你批次下的成功項目。 如果所有項目都已處理,迷你批次計數應該等於傳回清單計數。
平行作業會在每個處理器中執行函式,如下圖所示。
請參閱下列輸入腳本範例:
若要呼叫輸入腳本,請在平行作業定義中設定下列兩個屬性:
| Attribute name | 類型 | 描述 |
|---|---|---|
code |
字串 | 要上傳並用於作業的原始程式碼目錄本機路徑。 |
entry_script |
字串 | 包含預先定義平行函式實作的 Python 檔案。 |
平行作業步驟範例
下列平行作業步驟會宣告輸入類型、模式和資料除法方法、繫結輸入、設定計算,以及呼叫輸入腳本。
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
考慮自動化設定
Azure Machine Learning 平行作業會公開許多選用設定,以便在不手動介入的情況下自動控制作業。 下表描述了這些設定。
| 機碼 | 類型 | 描述 | 允許的值 | 預設值 | 在屬性或程式引數中設定 |
|---|---|---|---|---|---|
mini_batch_error_threshold |
整數 | 此平行作業中要忽略的失敗迷你批次數目。 如果失敗的迷你批次計數高於此閾值,便會將平行作業標示為失敗。 如果出現下列情況,會將迷你批次標示為失敗: - run() 傳回的計數小於迷你批次輸入計數。- 自訂 run() 程式碼中攔截到例外狀況。 |
[-1, int.max] |
-1,這表示忽略所有失敗的迷你批次 |
屬性 mini_batch_error_threshold |
mini_batch_max_retries |
整數 | 迷你批次失敗或逾時重試次數。如果所有重試失敗,則迷你批次會根據 mini_batch_error_threshold 計算標示為失敗。 |
[0, int.max] |
2 |
屬性 retry_settings.max_retries |
mini_batch_timeout |
整數 | 執行自訂 run() 函式的秒數逾時。 如果執行時間高於此閾值,便會中止迷你批次,並標示為失敗以觸發重試。 |
(0, 259200] |
60 |
屬性 retry_settings.timeout |
item_error_threshold |
整數 | 失敗項目的臨界值。 失敗項目會依輸入與每個迷你批次傳回之間的間距來計算。 如果失敗項目的總和高於此閾值,便會將平行作業標示為失敗。 | [-1, int.max] |
-1,這表示忽略平行作業期間的所有失敗 |
程式引數--error_threshold |
allowed_failed_percent |
整數 | 類似 mini_batch_error_threshold,但會使用失敗的迷你批次百分比,而不是計數。 |
[0, 100] |
100 |
程式引數--allowed_failed_percent |
overhead_timeout |
整數 | 每個迷你批次初始化作業的逾時 (以秒為單位)。 例如,載入迷你批次資料並傳遞至 run() 函式。 |
(0, 259200] |
600 |
程式引數--task_overhead_timeout |
progress_update_timeout |
整數 | 監視迷你批次執行進度的逾時 (以秒為單位)。 如果沒有在此設定的逾時內收到任何進度更新,便會將平行作業標示為失敗。 | (0, 259200] |
由其他設定動態計算 | 程式引數--progress_update_timeout |
first_task_creation_timeout |
整數 | 監視作業開始到執行第一個迷你批次之間時間的逾時 (以秒為單位)。 | (0, 259200] |
600 |
程式引數--first_task_creation_timeout |
logging_level |
字串 | 要傾印至使用者記錄檔的記錄層級。 | INFO、 WARNING或 DEBUG |
INFO |
屬性 logging_level |
append_row_to |
字串 | 彙總每個迷你批次執行的所有傳回內容,並輸出到此檔案中。 可以使用 ${{outputs.<output_name>}} 運算式來參考平行作業的其中一個輸出 |
屬性 task.append_row_to |
||
copy_logs_to_parent |
字串 | 是否將作業進度、概觀和記錄複製到父平行作業的佈林值選項。 | True 或 False |
False |
程式引數--copy_logs_to_parent |
resource_monitor_interval |
整數 | 將節點資源使用量 (例如 CPU 或記憶體) 傾印到 logs/sys/perf 路徑下記錄資料夾的時間間隔 (以秒為單位)。 注意: 頻繁傾印資源記錄的執行速度會稍慢。 將此值設定為 0 即可停止傾印資源使用量。 |
[0, int.max] |
600 |
程式引數--resource_monitor_interval |
下列範例程式碼會更新這些設定:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
使用平行作業步驟建立管線
下列範例顯示內嵌平行作業步驟的完整管線作業:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
提交管線作業
檢查 Studio UI 中的平行步驟
提交管線作業之後,SDK 或 CLI Widget 會提供 Azure Machine Learning 工作室 UI 中管線圖形的 Web URL 連結。
若要檢視平行作業結果,請按一下管線圖形中的平行步驟,選取詳細資料面板中的 [設定] 索引標籤,展開 [執行設定],然後展開 [平行] 區段。

若要偵錯平行作業失敗,請選取 [輸出 + 記錄] 索引標籤、展開 [記錄] 資料夾,然後檢查 job_result.txt 以了解平行作業失敗的原因。 如需平行作業記錄結構的相關資訊,請參閱相同資料夾中的 readme.txt。
![[作業] 索引標籤上 Azure Machine Learning 工作室的螢幕擷取畫面,其中顯示平行作業結果。](media/how-to-use-parallel-job-in-pipeline/screenshot-for-parallel-job-result.png?view=azureml-api-2#lightbox)