版本和追蹤 Azure Machine Learning 資料集
適用於:  Python SDK azureml v1 (部分機器翻譯)
Python SDK azureml v1 (部分機器翻譯)
在本文中,您將瞭解如何針對重現性設定 Azure Machine Learning 資料集的版本和進行追蹤。 資料集版本設定會將資料的特定狀態設為書籤,使得您可以套用特定版本的資料集,以供未來實驗之用。
您可能想要在這些一般案例中為 Azure Machine Learning 資源建立版本:
- 當新資料變得可供重新定型時
- 當您套用不同的資料準備或功能工程方法時
必要條件
適用於 Python 的 Azure Machine Learning SDK。 此 SDK 包含 azureml-datasets 套件
Azure Machine Learning 工作區。 建立新的工作區,或使用此程式碼範例來擷取現有的工作區:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
註冊並擷取資料集版本
您可以建立版本、重複使用並跨實驗及與同事共用已註冊的資料集。 您可以使用相同的名稱來註冊多個資料集,並依名稱和版本號碼來擷取特定版本。
註冊資料集版本
此程式碼範例會將 titanic_ds 資料集的 create_new_version 參數設定為 True,以註冊該資料集的新版本。 如果未向工作區註冊任何現有的 titanic_ds 資料集,程式碼會以名稱 titanic_ds 建立新的資料集,並將其版本設定為 1。
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
依名稱擷取資料集
依預設,Dataset 類別 get_by_name() 方法會傳回向工作區註冊的最新版本資料集。
此程式碼會傳回 titanic_ds 資料集的第 1 版。
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
版本設定最佳做法
建立資料集版本時,您不會使用工作區建立額外的資料複本。 資料集是儲存體服務中資料的參考,因此您具備儲存體服務所管理的單一真實來源。
重要
如果您的資料集所參考的資料遭到覆寫或刪除,則呼叫特定版本的資料集並不會還原變更。
當您從資料集載入資料時,一律會載入資料集所參考的目前資料內容。 如果您想要確保每個資料集版本都可重現,建議您避免修改資料集版本所參考的資料內容。 當新資料進入時,請將新的資料檔案儲存至不同的資料夾,然後建立新的資料集版本,以包含該新資料夾中的資料。
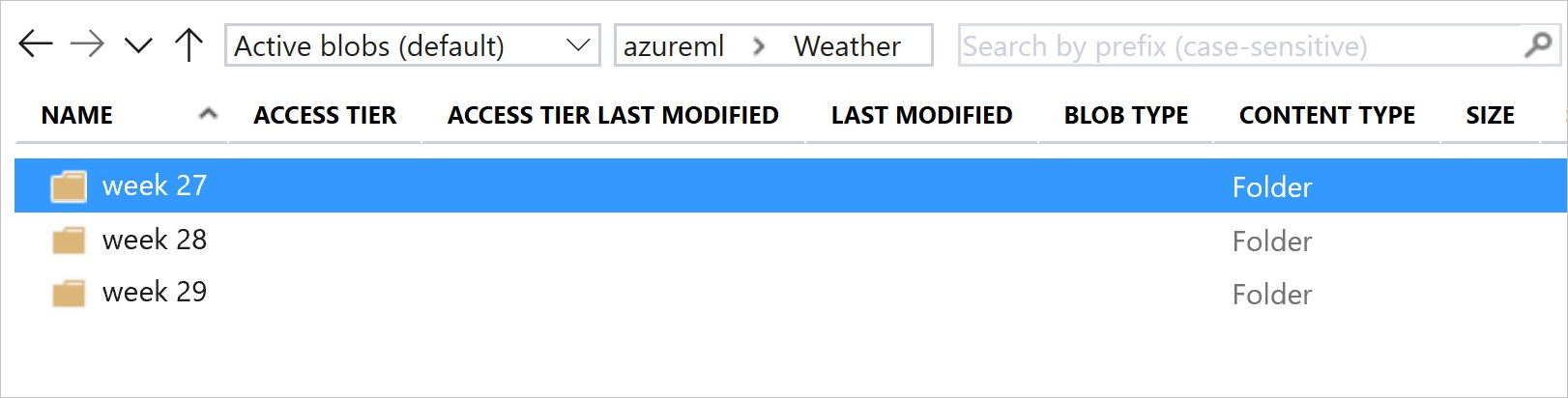
此圖和範例程式碼顯示建構您的資料夾並建立參考這些資料夾的資料集版本的建議方式:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
設定 ML 管線輸出資料集的版本
您可以使用資料集做為每個 ML 管線步驟的輸入和輸出。 當您重新執行管線時,每個管線步驟的輸出都會註冊為新的資料集版本。
Machine Learning 管線會在每次管線重新執行時,將每個步驟的輸出填入至新的資料夾。 然後,版本設定的輸出資料集會變得可重現。 如需詳細資訊,請瀏覽管線中的資料集。
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
追蹤實驗中的資料
Azure Machine Learning 會在整個實驗中追蹤您的資料做為輸入和輸出資料集。 在這些案例中,您的資料會追蹤為輸入資料集:
以
DatasetConsumptionConfig物件形式,在提交實驗工作時,透過ScriptRunConfig物件的inputs或arguments參數當您的指令碼呼叫特定方法時,例如
get_by_name()或get_by_id()。 在您向工作區註冊該資料集時指派給資料集的名稱是顯示的名稱
在這些案例中,您的資料會追蹤為輸出資料集:
在提交實驗工作時,透過
outputs或arguments參數傳遞OutputFileDatasetConfig物件。OutputFileDatasetConfig物件也可以在管線步驟之間保存資料。 如需詳細資訊,請瀏覽在 ML 管線步驟之間移動資料在您的指令碼中註冊資料集。 當您將資料集註冊到工作區時,指派給該資料集的名稱是顯示的名稱。 在此程式碼範例中,
training_ds是顯示的名稱:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )在指令碼中使用未註冊的資料集提交子工作。 此提交會導致匿名儲存的資料集
追蹤實驗作業中的資料集
針對每個 Machine Learning 實驗,您可以追蹤實驗 Job 物件的輸入資料集。 此程式碼範例會使用 get_details() 方法來追蹤用於實驗執行的輸入資料集:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
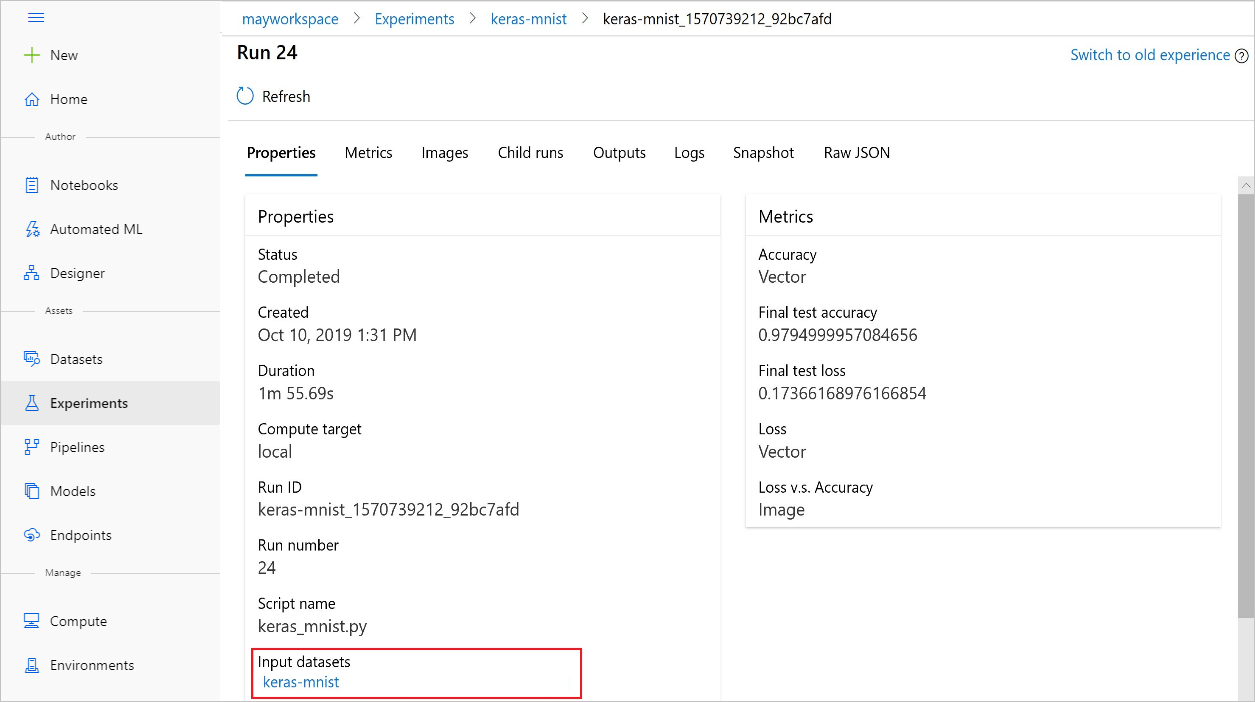
您也可以使用 Azure Machine Learning 工作室,從實驗中尋找 input_datasets。
此螢幕擷取畫面顯示在 Azure Machine Learning 工作室中尋找實驗的輸入資料集的位置。 在此範例中,從 [實驗] 窗格開始,然後開啟實驗特定執行 (keras-mnist) 的 [屬性] 索引標籤。
此程式碼會向資料集註冊模型:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
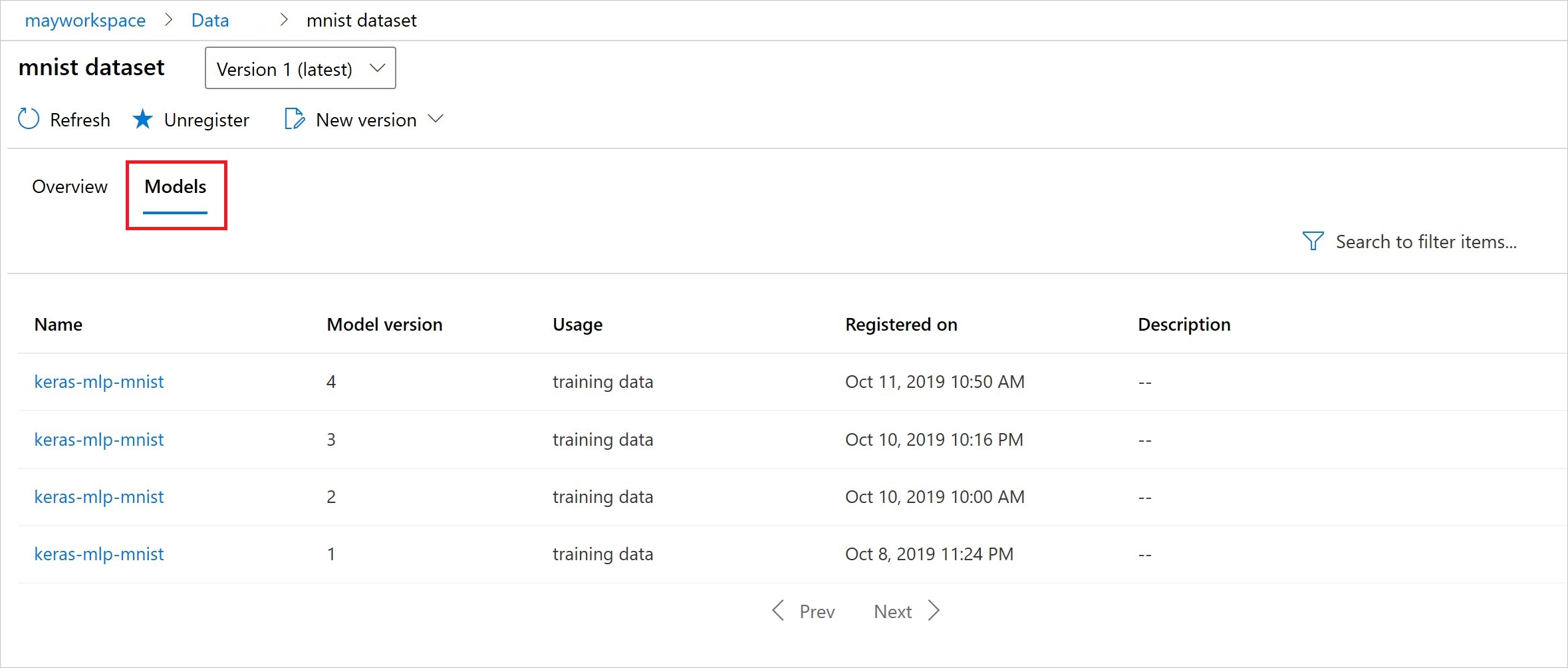
註冊之後,您可以使用 Python 或工作室來查看向資料集註冊的模型清單。
此螢幕擷取畫面來自 [資產] 底下的 [資料集] 窗格。 選取資料集,然後選取 [模型] 索引標籤,以取得已向資料集註冊的模型清單。