教學課程:將您的第一個機器學習模型 (SDK v1,3 部分之中的第 2 部分) 定型
適用於:  Python SDK azureml v1 (部分機器翻譯)
Python SDK azureml v1 (部分機器翻譯)
本教學課程說明如何在 Azure Machine Learning 中訓練機器學習模型。 本教學課程是兩部分教學課程系列的第 2 部分。
在系列的第 1 個部分:執行 "Hello world!" 時,您已了解如何使用控制指令碼在雲端中執行作業。
在本教學課程中,您會透過提交可訓練機器學習模型的指令碼來進行下一步。 此範例將協助您了解 Azure Machine Learning 如何在本機偵錯和遠端回合之間,輕鬆地達成一致的行為。
在本教學課程中,您已:
- 建立定型指令碼。
- 使用 Conda 來定義 Azure Machine Learning 環境。
- 建立控制指令碼。
- 了解 Azure Machine Learning 類別 (
Environment、Run、Metrics)。 - 提交並執行您的訓練指令碼。
- 在雲端中檢視程式碼輸出。
- 將計量記錄到 Azure Machine Learning。
- 在雲端中檢視您的計量。
必要條件
- 完成系列的第 1 個部分。
建立訓練指令碼
首先,您會在 model.py 檔案中定義神經網路架構。 您的所有訓練程式碼都會進入 src 子目錄,包括 model.py。
定型程式碼取自 PyTorch 的此簡介範例。 Azure Machine Learning 的概念適用於任何機器學習服務程式碼,而不只是 PyTorch。
在 src 子資料夾中建立 model.py 檔案。 將此程式碼複製到檔案:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x在工具列上,選取 [儲存] 以儲存檔案。 如果想要,請關閉索引標籤。
接下來,也在 src 子資料夾中定義定型指令碼。 此指令碼會使用 PyTorch
torchvision.datasetAPI 來下載 CIFAR10 資料集、設定 model.py 中定義的網路,以及使用標準 SGD 和交叉熵損失,針對兩個 epoch 來進行定型。在 src 子資料夾中建立 train.py 指令碼:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")您現在有下列資料夾結構:
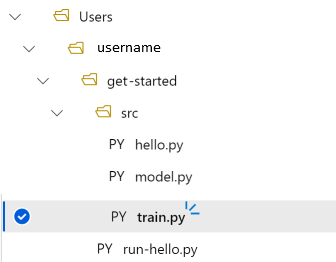
在本機進行測試
選取 [儲存並在終端機中執行指令碼],直接在計算執行個體上執行 train.py 指令碼。
指令碼完成後,請選取檔案資料夾上方的 [重新整理]。 您會看到名為 get-started/data 的新資料夾。展開此資料夾,以檢視下載的資料。
建立 Python 環境
Azure Machine Learning 提供環境概念來代表可重現且已建立版本的 Python 環境,用於執行實驗。 從本機 Conda 或 pip 環境中建立環境很容易。
首先,您將建立具有套件相依性的檔案。
在 get-started 資料夾中建立名為
pytorch-env.yml的新檔案:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvision在工具列上,選取 [儲存] 以儲存檔案。 如果想要,請關閉索引標籤。
建立控制項指令碼
下列控制指令碼與您用來提交 "Hello world!" 的控制之間的差異在於,您可以新增幾行額外的程式碼來設定環境。
在 get-started 資料夾中建立名為 run-pytorch.py 的新 Python 檔案:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
提示
如果您在建立計算叢集時使用不同的名稱,請務必同時調整程式碼 compute_target='cpu-cluster' 中的名稱。
了解程式碼變更
env = ...
參考您在上面建立的相依性檔案。
config.run_config.environment = env
將環境新增至 ScriptRunConfig。
提交回合至 Azure Machine Learning
選取 [儲存並在終端機中執行指令碼] 以執行 run-pytorch.py 指令碼。
您會在開啟的終端機視窗中看到連結。 選取連結以檢視作業。
注意
您可能會看到開頭為 Failure while loading azureml_run_type_providers... 的警告。您可以忽略這些警告。 使用這些警告底部的連結來檢視您的輸出。
檢視輸出
- 在開啟的頁面上,您會看到作業狀態。 第一次執行此指令碼時,Azure Machine Learning 會從您的 PyTorch 環境中建立新的 Docker 映像。 整個作業可能需要約 10 分鐘才能完成。 此映像將在未來作業中重複使用,因此執行速度會變得更快。
- 您可以在 Azure Machine Learning 工作室中檢視 Docker 組建記錄檔。 若要檢視組建記錄:
- 選取 [輸出 + 記錄] 索引標籤。
- 選取 [azureml-logs] 資料夾。
- 選取 20_image_build_log.txt。
- 當作業狀態為 [已完成] 時,請選取 [輸出 + 記錄]。
- 選取 user_logs 然後 std_log.txt 以檢視作業的輸出。
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
如果您看到錯誤 Your total snapshot size exceeds the limit,表示 data 目錄位於 ScriptRunConfig 所使用的 source_directory 值中。
選取資料夾結尾的 ...,然後選取 [移動] 以將 data 移至 get-started 資料夾。
記錄訓練計量
現在,您已在 Azure Machine Learning 中進行模型訓練,接著您可以開始追蹤一些效能計量。
目前的訓練指令碼會將計量列印到終端機。 Azure Machine Learning 提供一種機制來記錄具有更多功能的計量。 加入幾行程式碼,您就能將 Studio 中的計量視覺化,並將多項作業間的計量進行比較。
修改 train.py 以包含記錄
修改您的 train.py 指令碼,使其再多包含兩行程式碼:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')儲存此檔案,然後視需要關閉該索引標籤。
了解額外的兩行程式碼
在 train.py 中,您可以使用 Run.get_context() 方法,在定型指令碼本身內存取執行物件,並用其來記錄計量:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Azure Machine Learning 中的計量有以下特點:
- 透過實驗和回合進行整理,讓您可以輕鬆地追蹤和比較計量。
- 搭配 UI,讓您可以在 Studio 中將訓練效能視覺化。
- 專為擴充而設計,因此您可以在執行數百個實驗後,依然保有這些優點。
更新 Conda 環境檔案
train.py 指令碼只會在 azureml.core 上採用新的相依性。 更新 pytorch-env.yml 以反映這種變更:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
提交執行之前,請務必儲存此檔案。
提交回合至 Azure Machine Learning
選取 run-pytorch.py 指令碼的索引標籤,然後選取 [儲存並在終端機中執行指令碼],以重新執行 run-pytorch.py 指令碼。 請確定您已先將變更儲存至 pytorch-env.yml。
這次當您造訪 Studio 時,請移至 [計量] 索引標籤,您現在可以在此查看模型訓練損失的即時更新! 可能需要 1 到 2 分鐘的時間,定型才會開始。
![[計量] 索引標籤上的訓練損失圖形。](media/tutorial-1st-experiment-sdk-train/logging-metrics.png?view=azureml-api-1)
清除資源
如果您打算繼續進行另一個教學課程,或開始自己的訓練作業,請跳至相關資源。
停止計算執行個體
如果現在不打算使用,請停止計算執行個體:
- 在工作室的左側,選取 [計算]。
- 在頂端索引標籤中,選取 [計算執行個體]
- 選取清單中的計算執行個體。
- 在頂端工具列中,選取 [停止]。
刪除所有資源
重要
您所建立的資源可用來作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
如果不打算使用您建立的任何資源,請刪除以免產生任何費用:
在 Azure 入口網站 的搜尋方塊中,輸入 [資源群組],然後從結果中選取它。
從清單中,選取您所建立的資源群組。
在 [概觀] 頁面上,選取 [刪除資源群組]。
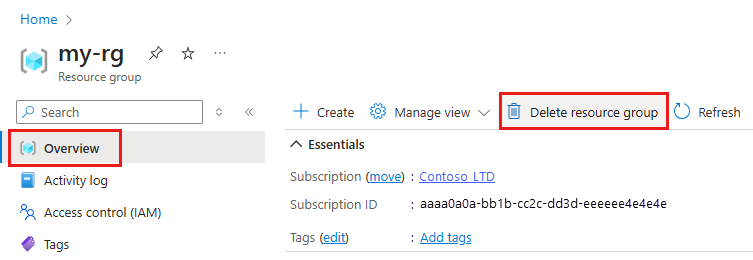
輸入資源群組名稱。 接著選取刪除。
您也可以保留資源群組,但刪除單一工作區。 顯示工作區屬性,然後選取 [刪除]。
相關資源
在此課程中,您已從基本的 "Hello world!" 指令碼升級為需要特定 Python 環境才能執行的更實際定型指令碼。 您已了解如何使用策展 Azure Machine Learning 環境。 最後,您已了解如何透過幾行程式碼,將計量記錄到 Azure Machine Learning。
還有其他方法可以建立 Azure Machine Learning 環境,包括從 pip requirements.txt,或從現有的本機 Conda 環境。