從 Azure 開放資料集建立 Azure Machine Learning 資料集
在本文中,您會了解如何使用 Azure Machine Learning 資料集和 Azure 開放資料集,將策劃的擴充資料帶入本機或遠端機器學習實驗。
透過 Azure Machine Learning 資料集,您可以建立資料來源位置的參考,以及其中繼資料的複本。 因為資料集會延遲評估,且因為資料保留在現有位置,您
- 不會有意外變更原始資料來源的風險
- 不會產生額外的儲存體成本。
- 改善 ML 工作流程效能速度
如需資料集如何融入整體 Azure Machine Learning 資料存取工作流程的詳細資訊,請參閱安全地存取資料一文。
Azure 開放資料集是策劃的公用資料集,可用來新增案例特定的功能,以擴充預測解決方案並改善解決方案的正確性。 請參閱開放資料集目錄資源,以取得可協助您定型機器學習模型的公用網域資料,例如:
開放資料集託管於 Microsoft Azure 上的雲端中。 Azure Machine Learning Python SDK 和 Azure Machine Learning 工作室都包含它們。
必要條件
您需要:
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
已安裝適用於 Python 的 Azure Machine Learning SDK,其包含
azureml-datasets套件。- 建立 Azure Machine Learning 計算執行個體 - 完整設定和受控的開發環境,其中已安裝整合式筆記本和 SDK。
OR
- 在您自己的 Python 環境中作業,並使用這些指示自行安裝 SDK。
注意
某些資料集類別具有 azureml-dataprep 套件的相依性。 此套件僅與 64 位元 Python 相容。 針對 Linux 使用者,這些類別僅於這些 Linux 散發套件上支援:
- Debian (8、9)
- Fedora (27、28)
- Red Hat Enterprise Linux (7、8)
- Ubuntu (14.04、16.04、18.04)
建立具有 SDK 的資料集
若要透過 Python SDK 中的 Azure 開放資料集類別建立 Azure Machine Learning 資料集,請確定您使用 pip install azureml-opendatasets 安裝套件。 在 SDK 中,每個離散資料集的類別都代表該類別,而且特定類別可作為 Azure Machine Learning FileDataset 資料類型、Azure Machine Learning TabularDataset 資料類型或兩者使用。 請瀏覽參考文件以取得 opendatasets 類別的完整清單。
您可以將特定 opendatasets 類別擷取為 TabularDataset 或 FileDataset 資源。 然後,您可以操作和/或直接下載檔案。 其他類別只能使用來自 Python SDK 中 Dataset 類別的 get_tabular_dataset() 或 get_file_dataset() 函式來擷取資料集。
下列程式碼顯示 MNIST opendatasets 類別可以傳回 TabularDataset 或 FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
在此範例中,糖尿病 opendatasets 類別只能作為 TabularDataset。 這需要使用 get_tabular_dataset()。
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
註冊資料集
向工作區註冊 Azure Machine Learning 資料集,以便與其他人共用資料集,並在工作區中的實驗之間重複使用。 當您註冊從開放資料集建立的 Azure Machine Learning 資料集時,不會立即下載任何資料,但是稍後向中央儲存位置提出要求時 (例如定型期間) 資料會變得可供存取。
若要向工作區註冊資料集,請使用 register() 方法。
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
建立具有工作室的資料集
您也可以使用 Azure Machine Learning 工作室,從 Azure 開放資料集建立 Azure Machine Learning 資料集。 此整合 Web 介面包含機器學習工具,可為所有技能等級的資料科學從業人員執行資料科學案例。
注意
透過 Azure Machine Learning 工作室建立的資料集會自動註冊到工作區。
在您的工作區中,選取左側導覽中的 [資料]。 在 [資料資產] 索引標籤上,選取 [建立],如此螢幕擷取畫面所示:
![顯示 [資料資產] 索引標籤上 [建立] 控制項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/data-assets-tab.png)
在下一個畫面中,新增新資料資產的名稱和選用描述。 然後,選取 [類型] 下拉式清單中的 [表格式],如此螢幕擷取畫面所示:
![顯示選取 [類型] 下拉式清單中 [表格式] 選項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-tabular-dropdown-option.png)
在下一個畫面中,選取 [從 Azure 開放資料集],然後選取 [下一步],如此螢幕擷取畫面所示:
![顯示選取 [從 Azure 開放資料集] 選項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-from-azure-open-datasets.png)
在下一個畫面中,選取可用的 Azure 開放資料集。 在此螢幕擷取畫面中,我們選取了 San Francisco Safety Data 資料集:
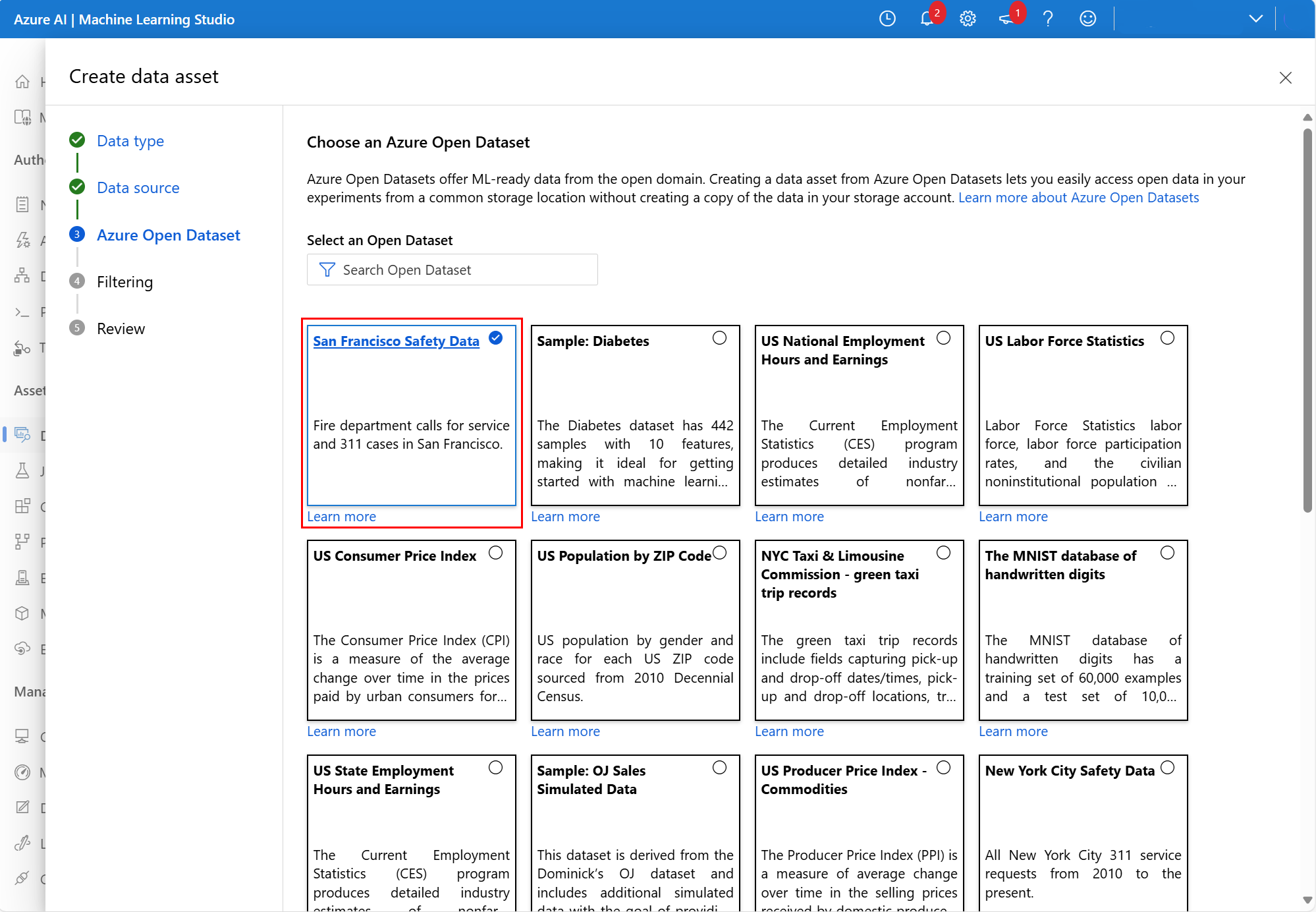
視需要向下捲動,然後選取 [下一步],如此螢幕擷取畫面所示:
![顯示選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-next.png)
或者,使用適用於所選資料集的可用篩選來篩選資料。 針對 San Francisco Safety Data 資料集,我們會設定開始日期介於 2024 年 7 月 1 日和 2024 年 7 月 17 日之間的篩選日期範圍。 選取 [下一步],如此螢幕擷取畫面所示:
![顯示選取篩選值,以及選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/data-asset-filter-example.png)
在下一個畫面中,檢閱新資料資產的設定,並進行任何必要的變更。 看起來都正常時,選取 [建立],如此螢幕擷取畫面所示:
![顯示檢閱所選設定,以及選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/create-the-data-asset.png)
如需有關 San Francisco Safety Data 資料集的欄位描述和日期範圍的詳細資訊,請瀏覽 San Francisco Safety Data 資源。 如需其他資料集的詳細資訊,請瀏覽 Azure 開放資料集目錄資源。
![顯示 [資料資產] 索引標籤上 [建立] 控制項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/data-assets-tab.png#lightbox)
![顯示選取 [類型] 下拉式清單中 [表格式] 選項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-tabular-dropdown-option.png#lightbox)
![顯示選取 [從 Azure 開放資料集] 選項的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-from-azure-open-datasets.png#lightbox)

![顯示選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/select-next.png#lightbox)
![顯示選取篩選值,以及選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/data-asset-filter-example.png#lightbox)
![顯示檢閱所選設定,以及選取 [下一步] 按鈕的螢幕擷取畫面。](media/how-to-create-dataset-from-open-dataset/create-the-data-asset.png#lightbox)
資料集現在可在工作區的 [資料集] 下取得。 您可以使用與您建立的其他資料集相同的方式使用它。
存取實驗的資料集
在機器學習實驗中使用資料集來定型 ML 模型。 如需詳細資訊,請瀏覽深入了解如何使用資料集定型。
Notebook 範例
如需開放資料集功能的範例和示範,請檢閱這些範例筆記本。