教學課程:使用 SynapseML 和 Azure AI 搜尋服務為 Apache Spark 大型資料編製索引
本 Azure AI 搜尋服務教學課程將介紹如何為載入自 Spark 叢集的大型資料編製索引並進行查詢。 設定 Jupyter Notebook 執行下列動作:
- 將各種表單 (發票) 載入至 Apache Spark 工作階段中的資料框架
- 分析這些資料以判斷其特徵
- 將產生的輸出組合成表格式資料結構
- 將輸出寫入 Azure AI 搜尋服務中裝載的搜尋索引
- 探索和查詢您所建立的內容
本教學課程相依於 SynapseML,這是一個開放原始碼程式庫,可支援巨量資料的大規模平行機器學習。 在 SynapseML 中,搜尋索引編製和機器學習會透過執行特定工作的轉換器公開。 轉換器會利用各種 AI 功能。 在此練習中,使用 AzureSearchWriter API 進行分析和 AI 擴充。
雖然 Azure AI 搜尋服務具有原生 AI 擴充功能,但本教學課程會示範如何在 Azure AI 搜尋服務外部存取 AI 功能。 藉由使用 SynapseML,而不是索引子或技能,您便不會受限於這些物件相關的資料限制或其他條件約束。
提示
請觀賞此示範的短片:https://www.youtube.com/watch?v=iXnBLwp7f88。 影片會以更多步驟和視覺效果呈現本教學課程。
必要條件
您需要 synapseml 程式庫和數個 Azure 資源。 可能的話,請在您的 Azure 資源使用相同的訂用帳戶和區域,並將所有內容放在同一資源群組中,以便稍後可輕鬆將其清除。 下列連結適用於入口網站安裝。 範例資料會從公用網站匯入。
- SynapseML 套件 1
- Azure AI 搜尋服務 (任意服務層級) 2
- Azure AI 服務 (任意服務層級) 3
- Azure Databricks (任意服務層級) 4
1 此連結會解析為載入套件的教學課程。
2 您可以使用免費的搜尋服務層級來編製範例資料的索引,但如果您的資料磁碟區很大,請選擇更高的服務層級。 針對計費層,請在後續的設定相依項目步驟中提供搜尋 API 金鑰。
3 本教學課程會使用 Azure AI 文件智慧服務和 Azure AI 翻譯工具。 在後續指示中,提供多重服務金鑰和區域。 相同的金鑰適用於這兩個服務。
4 在本教學課程中,Azure Databricks 提供 Spark 運算平台。 我們已使用入口網站指示來設定工作區。
注意
上述所有 Azure 資源都支援 Microsoft 身分識別平台的安全性功能。 為了簡單起見,本教學課程假設使用從每個服務 Azure 入口網站 頁面複製的端點和金鑰,進行密鑰型驗證。 如果您在實際執行環境中實作此工作流程,或與他人分享此解決方案,請記得以整合式安全性或加密密鑰取代硬式編碼金鑰。
步驟 1:建立 Spark 叢集和筆記本
在本節中,請建立叢集、安裝 synapseml 程式庫,以及建立筆記本來執行程式碼。
在 Azure 入口網站中找到您的 Azure Databricks 工作區,然後選取 [啟動工作區]。
在左側功能表上,選取 [計算]。
選取 [建立計算]。
接受預設組態。 建立叢集需要幾分鐘的時間。
在建立叢集之後安裝
synapseml程式庫:從叢集頁面頂端的索引標籤選取 [程式庫]。
選取 [安裝新的]。
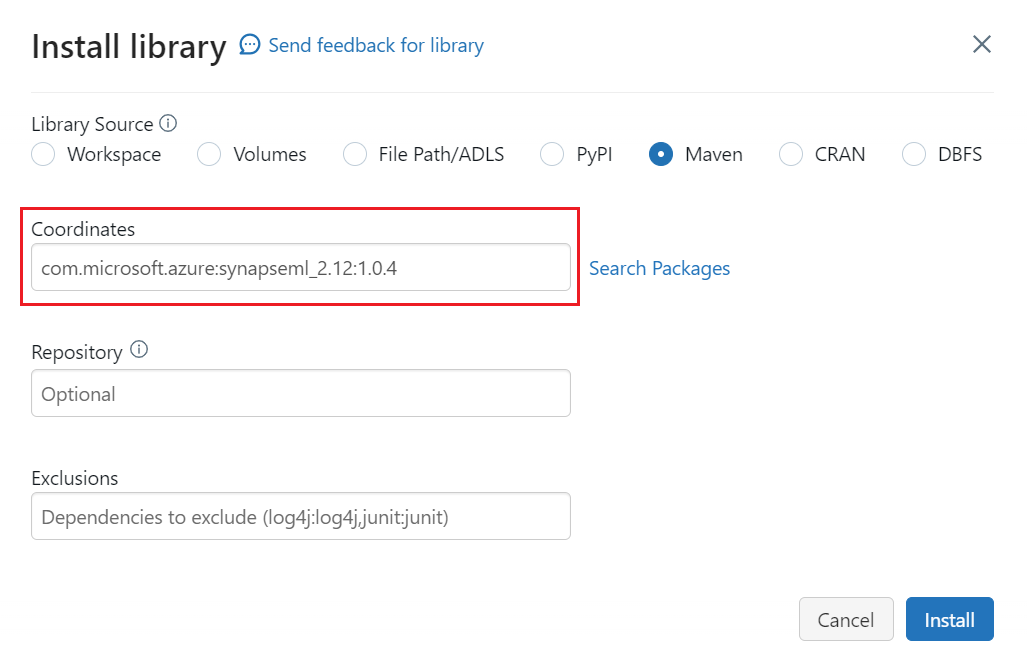
![[安裝新的] 命令的螢幕擷取畫面。](media/search-synapseml-cognitive-services/install-library.png)
選取 [Maven]。
在 [座標] 中,輸入
com.microsoft.azure:synapseml_2.12:1.0.4選取安裝。
在左側功能表上,選取 [建立]>[筆記本]。
![[建立筆記本] 命令的螢幕擷取畫面。](media/search-synapseml-cognitive-services/create-notebook.png)
指定筆記本的名稱、選取 [Python] 作為預設語言,然後選取具有
synapseml程式庫的叢集。建立七個連續的儲存格。 將程式碼貼到每個儲存格中。
步驟 2:設定相依性
將下列程式碼貼到筆記本的第一個儲存格中。
以端點和存取金鑰取代每個資源的預留位置。 為新的搜尋索引提供名稱。 其他內容不需要修改,當您準備好時即可執行程式碼。
此程式碼會匯入多個套件,並設定此工作流程中使用的 Azure 資源存取權。
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
步驟 3:將資料載入 Spark
將下列程式碼貼到第二個儲存格中。 無需其他修改,當您準備好時即可執行程式碼。
此程式碼會載入一些 Azure 儲存體帳戶的外部檔案。 這些檔案是各種發票,並且會讀取到資料框架中。
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
步驟 4:新增文件智慧服務
將下列程式碼貼到第三個儲存格中。 無需其他修改,當您準備好時即可執行程式碼。
此程式碼會載入 AnalyzeInvoices 轉換器,並傳遞包含發票的資料框架參考。 其會呼叫 Azure AI 文件智慧服務預先建置的發票模型,藉此擷取發票資訊。
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
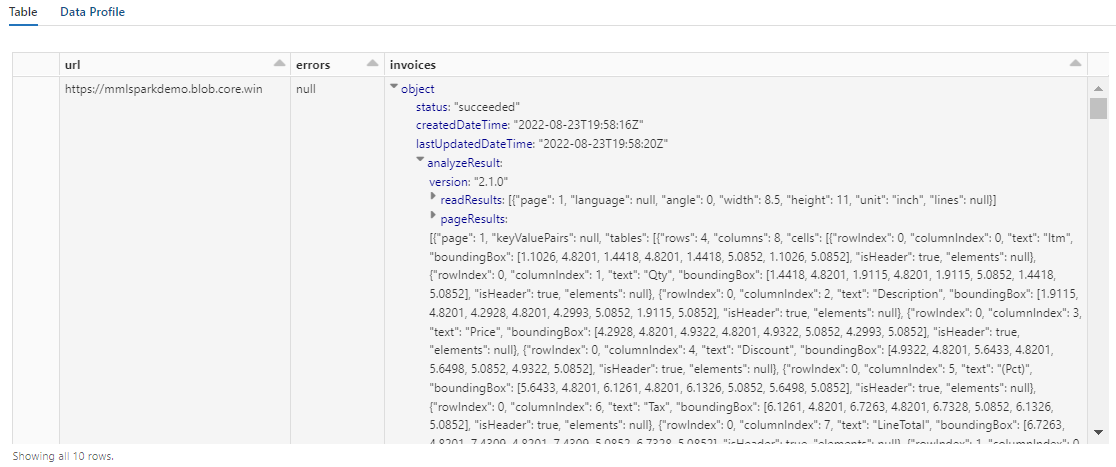
此步驟的輸出應該類似於下方螢幕擷取畫面。 請注意表單分析如何封裝成密集結構化資料行,這種格式很難使用。 下一個轉換會將資料行剖析成資料列和資料行,從而解決此問題。
步驟 5:重新建構文件智慧服務輸出
將下列程式碼貼到第四個儲存格中並執行。 不需要修改。
此程式碼會載入 FormOntologyLearner,此轉換器會分析「文件智慧服務」轉換器的輸出,並推斷表格式資料結構。 AnalyzeInvoices 的輸出並非固定,而是根據內容中偵測到的特徵而有所不同。 此外,轉換器會將輸出合併成單一資料行。 因為輸出不固定且經過合併,因此很難在需要更多結構的下游轉換中使用。
FormOntologyLearner 會尋找可用來建立表格式資料結構的模式,藉此擴充 AnalyzeInvoices 轉換器的應用範圍。 將輸出整理成多個資料行和資料列,使內容可用於其他轉換器,例如 AzureSearchWriter。
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
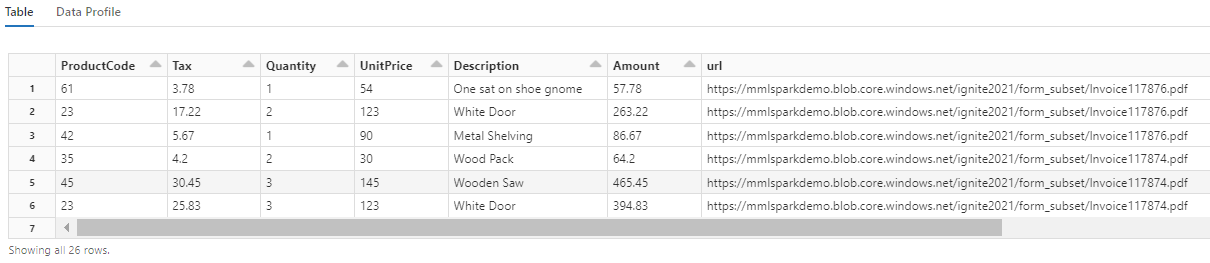
請注意此轉換如何將巢狀欄位重新轉換成資料表,從而支援後續的兩個轉換。 為保持簡潔,此螢幕擷取畫面已經過修剪。 如果您追蹤自己的筆記本,則會看到 19 個資料行和 26 個資料列。
步驟 6:新增翻譯
將下列程式碼貼到第五個儲存格。 無需其他修改,當您準備好時即可執行程式碼。
此程式碼會載入 Translate,此轉換器會在 Azure AI 服務中呼叫 Azure AI 翻譯工具服務。 原始文字 (「Description (描述)」資料行中的英文) 會以機器翻譯成各種語言。 所有輸出都會合併至「output.translations」陣列。
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
提示
若要檢查翻譯的字串,請捲動至資料列的結尾。
![資料表輸出的螢幕擷取畫面,其中顯示 [翻譯] 資料行。](media/search-synapseml-cognitive-services/translated-strings.png)
步驟 7:使用 AzureSearchWriter 新增搜尋索引
將下列程式碼貼到第六個儲存格中,然後執行。 不需要修改。
此程式碼會載入 AzureSearchWriter。 該轉換器會取用表格式資料集,並推斷搜尋索引架構,為每個資料行定義一個欄位。 因為翻譯結構是一個陣列,所以在索引中會以複雜集合的形式來呈現每個語言翻譯的子欄位。 產生的索引有文件索引鍵,並使用建立索引 REST API 所建立欄位的預設值。
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
您可以在 Azure 入口網站中檢查搜尋服務頁面,以探索 AzureSearchWriter 所建立的索引定義。
注意
如果您無法使用預設搜尋索引,可以在 JSON 中提供外部自訂定義,將其 URI 作為「indexJson」屬性中的字串傳遞。 請先產生預設索引,以便識別要指定的欄位,然後遵循自訂屬性,假如您需要特定的分析器。
步驟 8:查詢索引
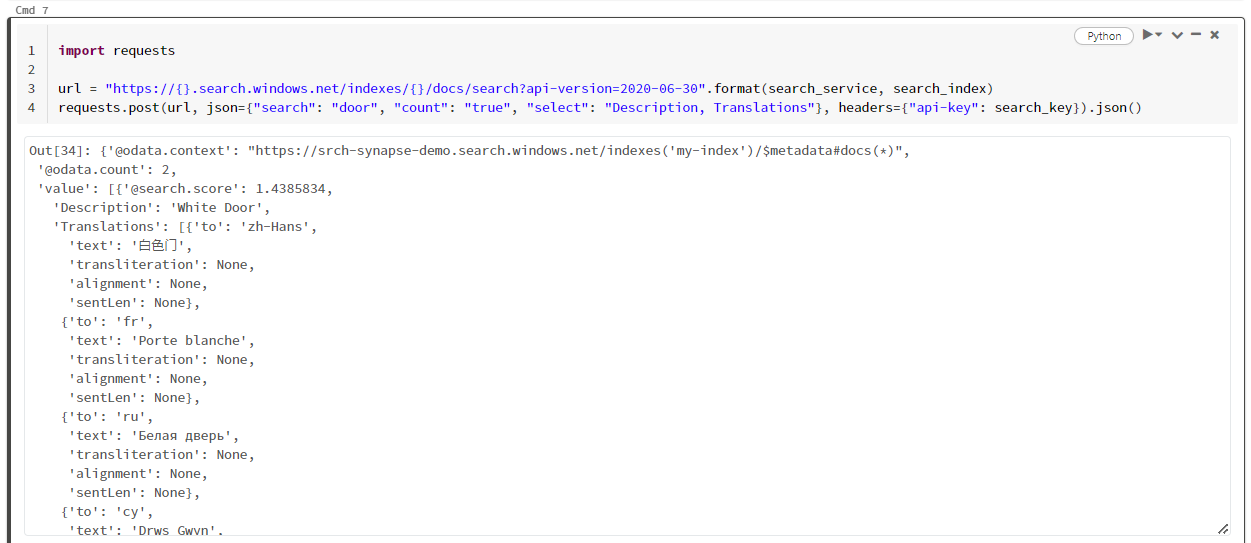
將下列程式碼貼到第七個儲存格中,然後執行。 不需要修改,但您可以改變語法或嘗試更多範例以進一步探索您的內容:
其中沒有發出查詢的轉換器或模組。 此儲存格是搜尋文件 REST API 的簡單呼叫。
此特定範例正在搜尋「door」一詞 ("search": "door")。 該搜尋也會傳回相符文件的「count (計數)」,並只針對結果選取「Description (描述)」和「Translations (翻譯)」欄位的內容。 如果您想要查看欄位的完整清單,請移除「select」參數。
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
下列螢幕擷取畫面顯示範例指令碼的儲存格輸出。
清除資源
如果您使用自己的訂用帳戶,當專案結束時,建議您移除不再需要的資源。 資源若繼續執行,將需付費。 您可以個別刪除資源,或刪除資源群組以刪除整組資源。
您可以使用左側瀏覽窗格中的 [所有資源] 或 [資源群組] 連結,在 Azure 入口網站 中找到和管理資源。
下一步
在本教學課程中,您已認識 SynapseML 中的 AzureSearchWriter 轉換器,這是在 Azure AI 搜尋服務中建立和載入搜尋索引的新方式。 轉換器會採用結構化 JSON 作為輸入。 FormOntologyLearner 可以提供 SynapseML 中檔案智慧服務轉換器產生輸出所需的結構。
作為下一步驟,請檢閱其他 SynapseML 教學課程,以產生您可能想透過 Azure AI 搜尋服務探索的轉換內容: