教學課程:以 parquet 格式擷取事件中樞資料,並使用 Azure Synapse Analytics 進行分析
本教學課程示範如何使用串流分析,而不需要程式碼編輯器來建立作業,以 Parquet 格式擷取至 Azure Data Lake Storage Gen2 中的事件中樞資料。
在本教學課程中,您會了解如何:
- 部署可將範例事件傳送至事件中樞的事件產生器
- 使用無程式碼編輯器來建立串流分析工作
- 檢閱輸入資料和結構描述
- 設定將事件中樞資料擷取至其中的 Azure Data Lake Storage Gen2
- 執行串流分析作業
- 使用 Azure Synapse Analytics 來查詢 parquet 檔案
必要條件
開始之前,請確定您已完成下列步驟:
- 如果您沒有 Azure 訂閱,請建立免費帳戶。
- 將 TollApp 事件產生器應用程式部署至 Azure。 將 'interval' 參數設定為 1,並針對此步驟使用新的資源群組。
- 使用 Data Lake Storage Gen2 帳戶來建立 Azure Synapse Analytics 工作區。
使用無程式碼編輯器來建立串流分析工作
找出已部署 TollApp 事件產生器的資源群組。
選取 Azure 事件中樞命名空間。 您可能想要在另一個索引標籤或視窗中開啟它。
在 [事件中樞命名空間] 頁面上,選取左側功能表上 [實體] 底下的 [事件中樞]。
選取
entrystream執行個體。
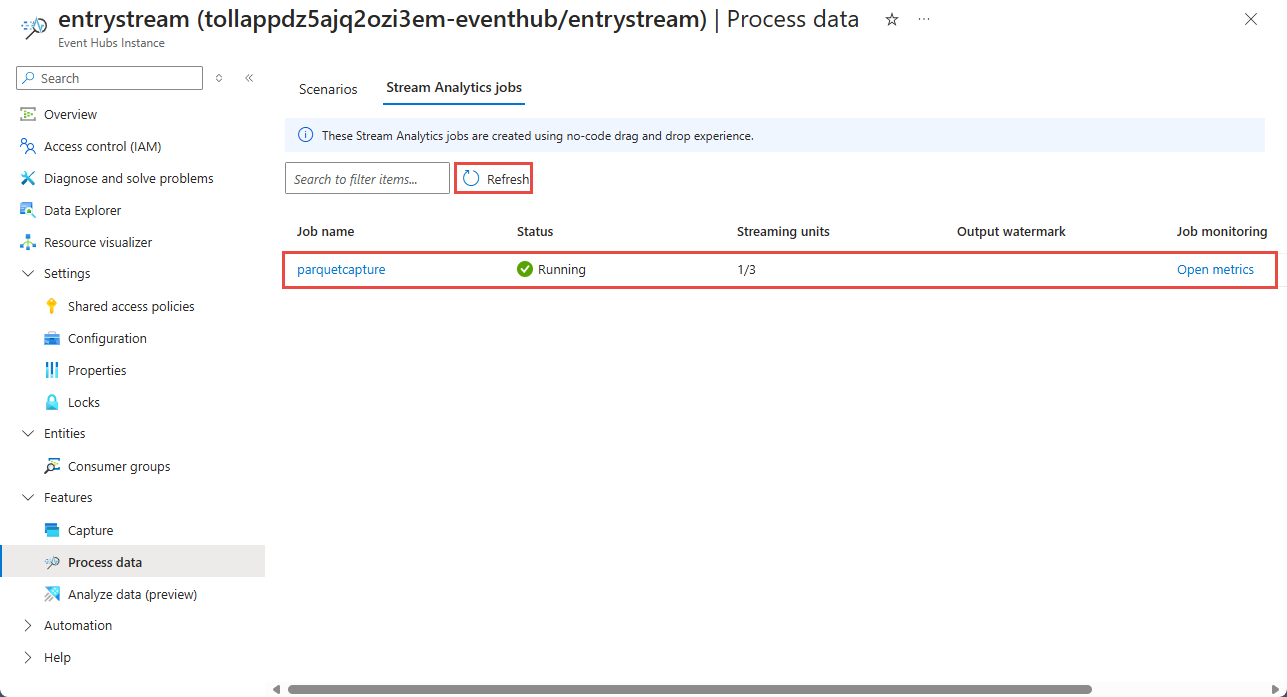
在 [事件中樞執行個體] 頁面上,選取左側功能表上 [功能] 區段中的 [處理資料]。
選取 [以 Parquet 格式將資料擷取至 ADLS Gen2] 圖格上選取 [開始]。
![顯示 [擷取數據至 Parquet 格式] 磚之 [將數據擷取至 ADLS Gen2] 圖格的螢幕快照。](media/stream-analytics-no-code/parquet-capture-start.png)
為您的作業
parquetcapture命名,然後選取 [建立]。![[新增串流分析作業] 頁面的螢幕快照。](media/stream-analytics-no-code/new-stream-analytics-job.png)
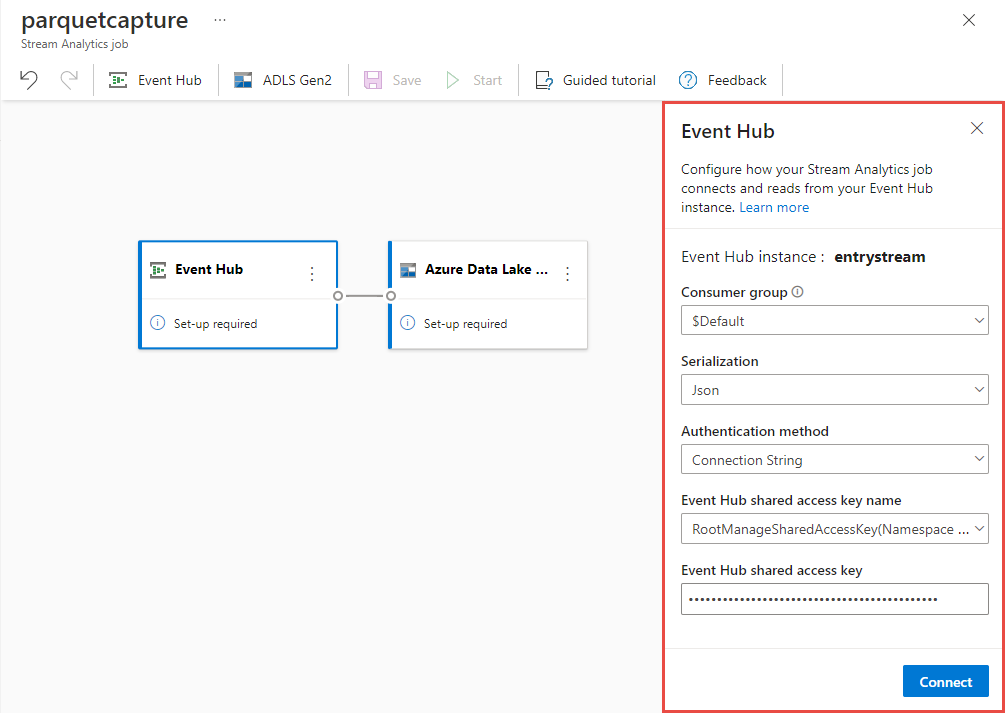
在事件中 樞 組態頁面上,遵循下列步驟:
針對 [ 取用者群組],選取 [ 使用現有]。
確認已
$Default選取取用者群組。確認 串行化 已設定為 JSON。
確認 驗證方法 已設定為 [連接字串]。
確認 事件中樞共用存取密鑰名稱 設定為 RootManageSharedAccessKey。
選取視窗底部的 [ 連線 ]。
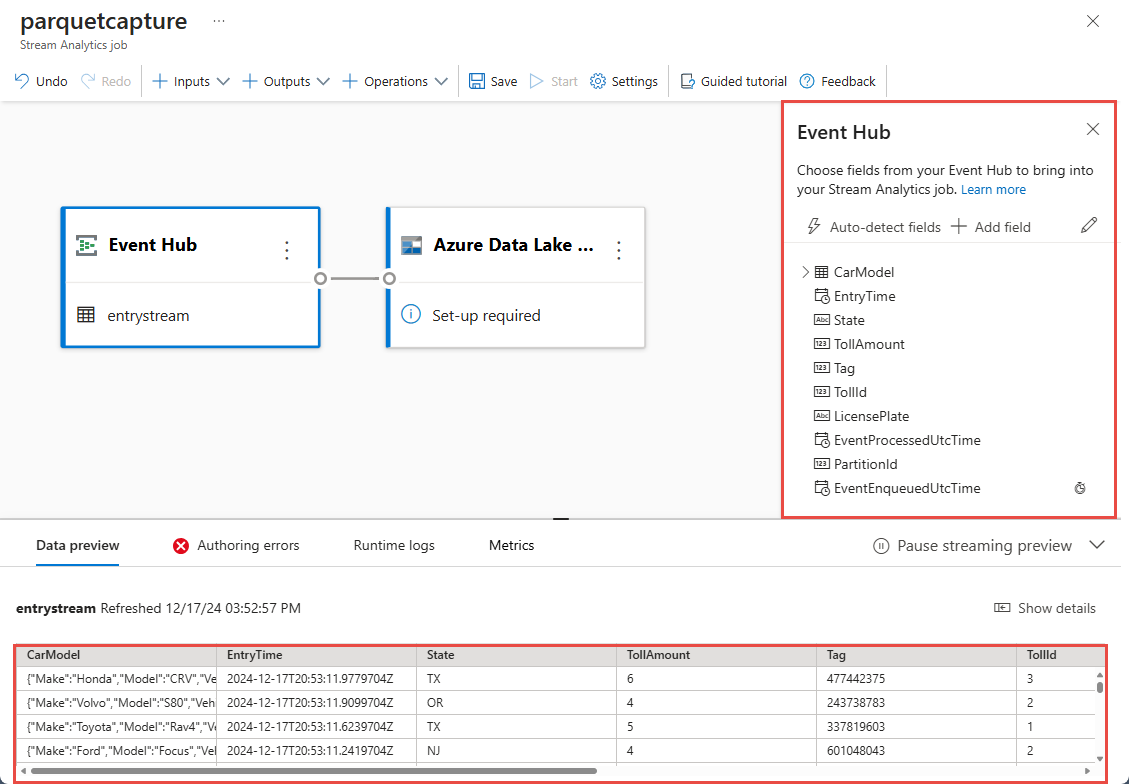
在幾秒鐘內,您會看到範例輸入資料和結構描述。 您可以選擇卸除欄位、重新命名字段或變更資料類型。
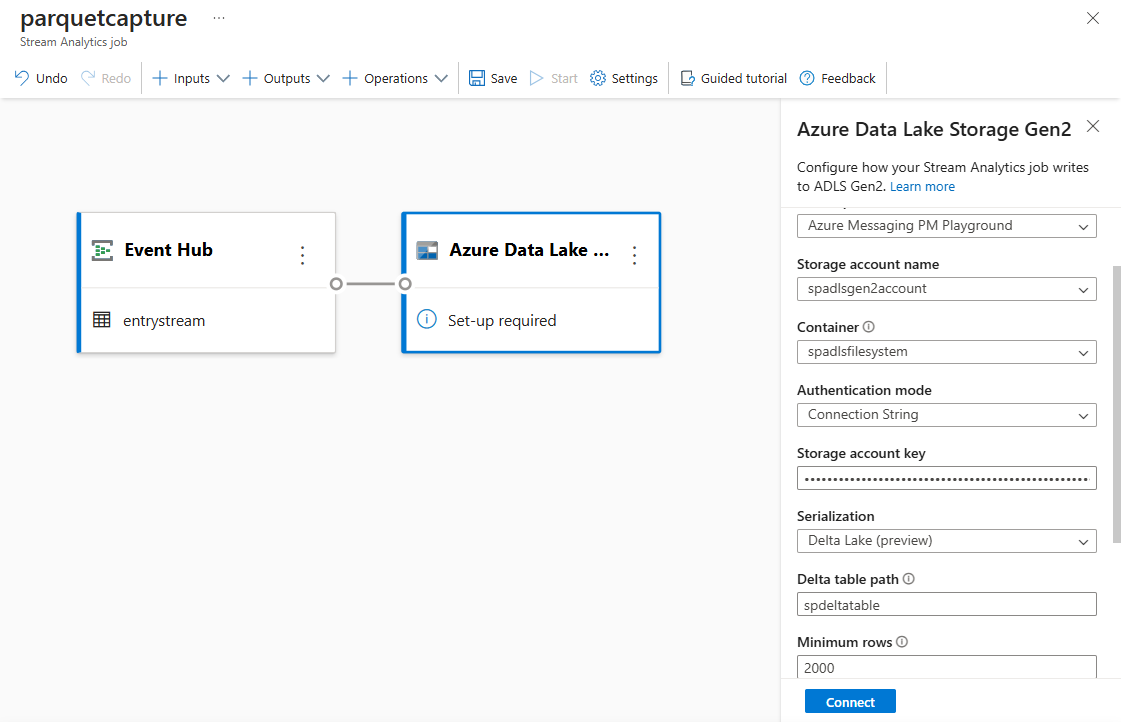
選取畫布上的 [Azure Data Lake Storage Gen2] 圖格,並指定下列項目來進行設定
Azure Data Lake Gen2 帳戶所在的訂用帳戶
儲存體帳戶名稱,這應該與您在<必要條件>一節中完成的 Azure Synapse Analytics 工作區一起使用的 ADLS Gen2 帳戶相同。
將在其內建立 Parquet 檔案的容器。
針對 Delta 資料表路徑,指定資料表的名稱。
日期和時間模式作為預設 yyyy-mm-dd 和 HH。
選取連線
選取頂端功能區中的 [儲存] 以儲存您的工作,然後選取 [開始] 以執行作業。 作業開始後,請選取右上角的 X 以關閉 [串流分析作業] 頁面。
![顯示 [開始串流分析作業] 頁面的螢幕快照。](media/event-hubs-parquet-capture-tutorial/start-job.png)
接著,您會看到已使用無程式碼編輯器建立的所有串流分析工作清單。 在兩分鐘內,您的工作將會進入 [執行中] 狀態。 選取頁面上的 [重新整理] 按鈕,以查看從 [已建立 -> 啟動中 -> 執行中] 的狀態變更。

![顯示 [擷取數據至 Parquet 格式] 磚之 [將數據擷取至 ADLS Gen2] 圖格的螢幕快照。](media/stream-analytics-no-code/parquet-capture-start.png#lightbox)
![[新增串流分析作業] 頁面的螢幕快照。](media/stream-analytics-no-code/new-stream-analytics-job.png#lightbox)



![顯示 [開始串流分析作業] 頁面的螢幕快照。](media/event-hubs-parquet-capture-tutorial/start-job.png#lightbox)

在 Azure Data Lake Storage Gen 2 帳戶中檢視輸出
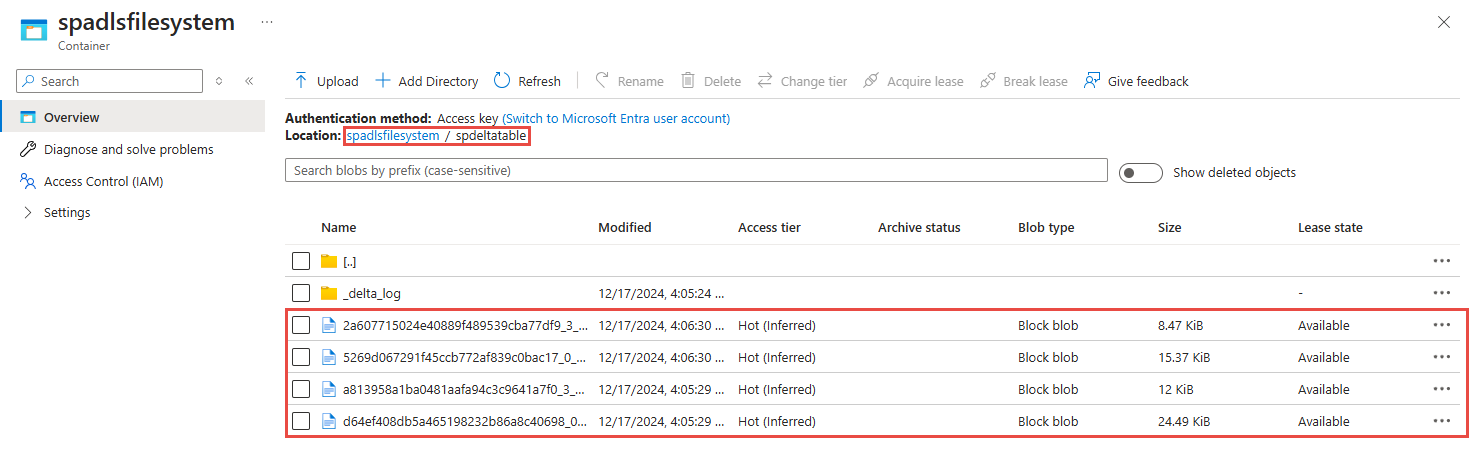
找出您已在上一個步驟中使用的 Azure Data Lake Storage Gen2 帳戶。
選取您已在上一個步驟中使用的容器。 您會看到在稍早指定資料夾中建立的 parquet 檔案。

使用 Azure Synapse Analytics 查詢以 Parquet 格式所擷取的資料
使用 Azure Synapse Spark 進行查詢
找出您的 Azure Synapse Analytics 工作區,然後開啟 Synapse Studio。
如果工作區中還沒有無伺服器 Apache Spark 集區,則請在工作區中建立無伺服器 Apache Spark 集區。
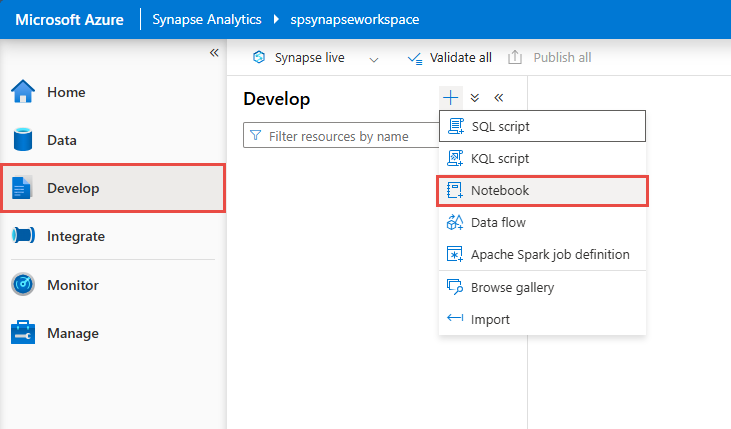
在 Synapse Studio 中,移至 [開發] 中樞內,然後建立新的 [筆記本]。
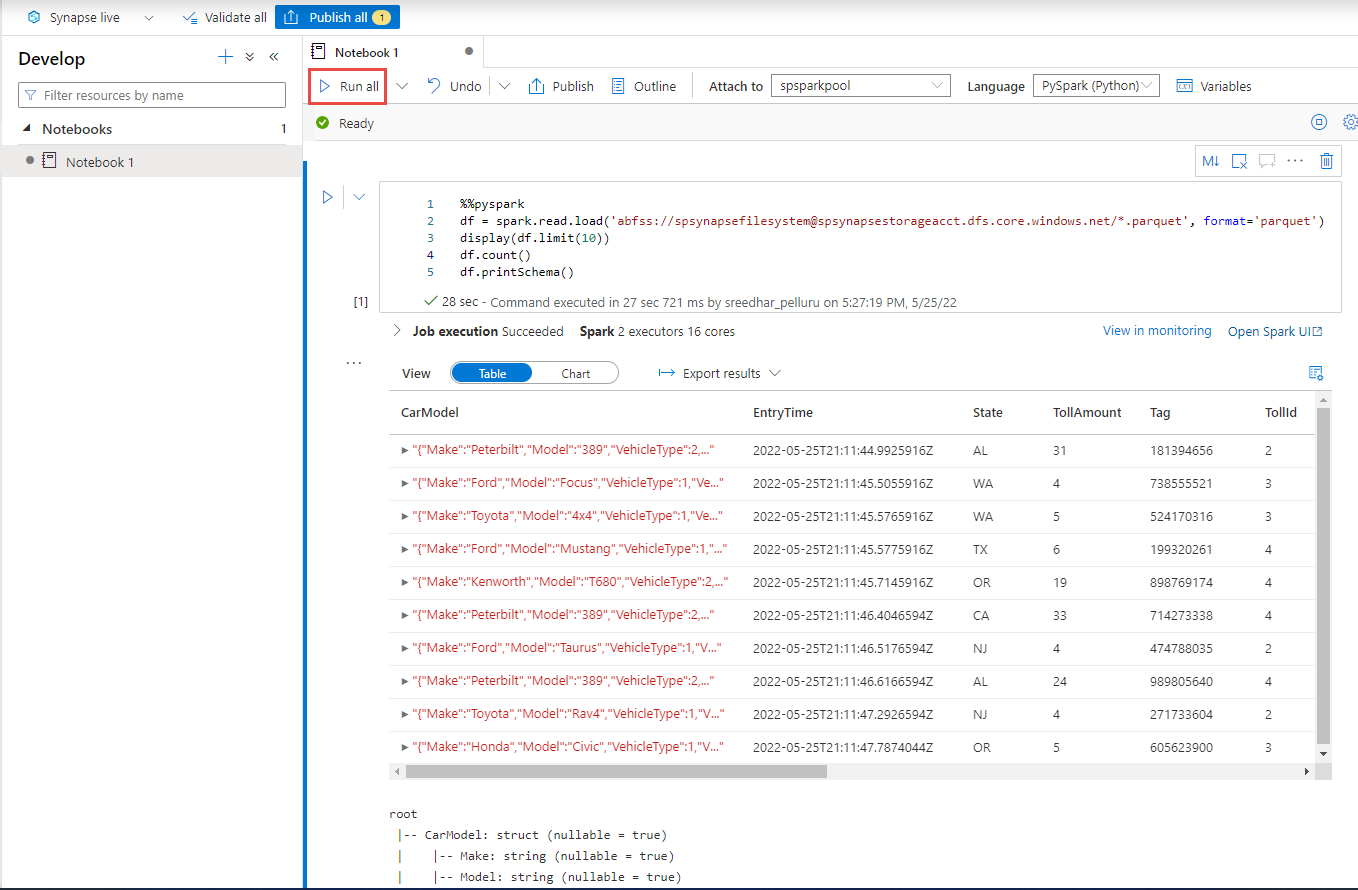
建立新的程式碼儲存格,並在該儲存格中貼上下列程式碼。 將 container 和 adlsname 取代為上一個步驟中使用的容器名稱和 ADLS Gen2 帳戶。
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()針對工具列上的 [連結至],從下拉式清單中選取您的 Spark 集區。
選取 [全部執行] 以查看結果

使用 Azure Synapse 無伺服器 SQL 進行查詢
在 [開發] 中樞內,建立新的 [SQL 指令碼]。
![顯示 [開發] 頁面的螢幕快照,其中已選取新的 SQL 腳本功能表。](media/event-hubs-parquet-capture-tutorial/develop-sql-script.png)
貼上下列指令碼,並使用「內建」無伺服器 SQL 端點來 [執行] 該指令碼。 將 container 和 adlsname 取代為上一個步驟中使用的容器名稱和 ADLS Gen2 帳戶。
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]

清除資源
- 找出您的事件中樞執行個體,並查看 [處理資料] 區段下的串流分析工作清單。 停止任何正在執行的工作。
- 移至部署 TollApp 事件產生器時所使用的資源群組。
- 選取 [刪除資源群組]。 輸入資源群組名稱以確認刪除。
下一步
在本教學課程中,您已了解如何使用無程式碼編輯器來建立串流分析工作,以 Parquet 格式擷取事件中樞資料串流。 接著,您已使用 Azure Synapse Analytics,同時使用 Synapse Spark 和 Synapse SQL 來查詢 parquet 檔案。