Azure Synapse 資料總管資料擷取概觀 (預覽)
資料擷取是一個程序,用來從一或多個來源載入資料記錄,再將資料匯入 Azure Synapse 資料總管集區中的資料表。 一旦擷取之後,資料就會變成可供查詢。
Azure Synapse 資料總管中負責資料擷取的資料管理服務可實作下列程序:
- 從外部來源批次或串流提取資料,並從擱置的 Azure 佇列中讀取要求。
- 流向相同資料庫和資料表的批次資料,已針對擷取輸送量最佳化。
- 初始資料會經過驗證,並在必要時轉換格式。
- 進一步資料操作包括比對結構描述、組織、編製索引、編碼以及壓縮資料。
- 資料會根據設定保留原則保存在儲存體中。
- 已內嵌的資料會認可到引擎中,以供查詢。
支援的資料格式、屬性和權限
擷取屬性 :會影響資料內嵌方式的屬性 (例如,標記、對應、建立時間)。
權限:若要內嵌資料,程序需要資料庫擷取器層級權限。 其他動作 (例如查詢) 可能需要資料庫管理員、資料庫使用者或資料表管理員權限。
批次處理與串流擷取
批次處理擷取會進行資料批次處理,並已針對高擷取輸送量進行最佳化。 這個方法是擷取慣用的最高效能類型。 資料會根據擷取屬性進行批次處理。 小型批次的資料會合併,並針對快速查詢結果進行最佳化。 您可以在資料庫或資料表上設定擷取批次處理原則。 根據預設,最大批次處理值為 5 分鐘、1000 個項目,或總大小為 1 GB。 批次擷取命令的資料大小限制為 4 GB。
串流擷取是從串流來源進行的資料擷取。 串流擷取可讓您以近乎即時的延遲來處理每個資料表的小型資料集。 資料一開始會內嵌到資料列存放區,然後移至資料行存放區範圍。
擷取方法和工具
Azure Synapse 資料總管支援數種擷取方法,而每種方法都有自己的目標案例。 這些方法包括擷取工具、各種服務的連接器和外掛程式、受控管線、使用 SDK 的程式設計擷取,以及擷取的直接存取權。
使用受控管線進行擷取
對於想要由外部服務進行管理 (節流、重試、監視、警示等) 的組織而言,使用連接器可能是最適當的解決方案。 已排入佇列的擷取適合大量資料。 Azure Synapse 資料總管支援下列 Azure Pipelines:
- 事件中樞:可將事件從服務轉送至 Azure Synapse 資料總管的管線。 如需詳細資訊,請參閱將資料從事件中樞內嵌至 Azure Synapse 資料總管。
- Synapse 管線:適用於 Synapse 管線中分析工作負載的完全受控資料整合服務,連接到超過 90 種支援來源,以提供有效率且可復原的資料傳輸。 Synapse 管線會準備、轉換及擴充資料,以提供可透過不同方式監視的見解。 此服務可作為一次性解決方案、用於定期的時間軸上,或由特定事件所觸發。
使用 SDK 進行程式設計擷取
Azure Synapse 資料總管會提供可用於查詢和資料擷取的 SDK。 程式設計擷取適合用於將擷取程序期間和之後的儲存體交易降至最低,藉此降低擷取成本 (COG)。
開始之前,請使用下列步驟取得資料總管集區端點,以設定程式設計擷取。
在 Synapse Studio 的左側窗格中,選取 [管理]>[資料總管集區]。
選取您要檢視詳細資料的資料總管集區。
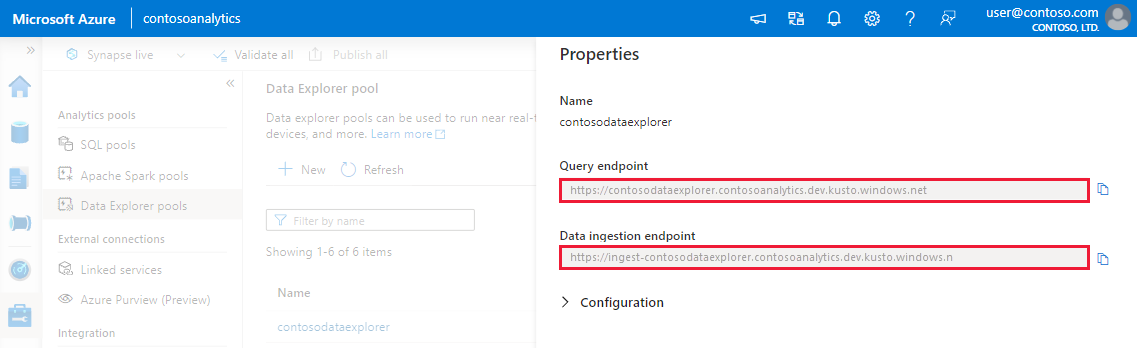
記下查詢端點和資料擷取端點。 設定資料總管集區的連線時,請使用查詢端點作為叢集。 設定 SDK 以便進行資料擷取時,請使用資料擷取端點。
可用的 SDK 及開放原始碼專案
工具
- 單鍵擷取:可讓您從各種來源類型建立和調整資料表,以便快速內嵌資料。 單鍵擷取會根據 Azure Synapse 資料總管中的資料來源,自動建議資料表和對應結構。 單鍵擷取可用於一次性擷取,或在資料內嵌所至的容器上透過事件方格定義連續擷取。
Kusto 查詢語言內嵌控制命令
有數種方法可經由 Kusto 查詢語言 (KQL) 命令,將資料直接內嵌至引擎。 因為此方法會略過資料管理服務,所以只適用於探索和原型設計。 請勿在生產或高容量的案例中使用此方法。
內嵌式擷取:系統會將控制命令 (.ingest inline) 傳送至引擎,並將資料內嵌為命令文字本身的一部分。 此方法適用於即興測試用途。
從查詢內嵌:系統會將控制命令 (.set、.append、.set-or-append 或 .set-or-replace) 傳送至引擎,並將資料間接指定為查詢或命令的結果。
從儲存體內嵌 (提取) :系統會將控制命令 (.ingest into) 傳送至引擎,並且讓儲存在某些外部儲存體 (例如 Azure Blob 儲存體) 中的資料可由引擎存取,並由命令指向。
如需使用內嵌控制命令的範例,請參閱使用資料總管進行分析.
擷取程序
一旦選擇了最符合您需求的擷取方法,請執行下列步驟:
設定保留原則
在 Azure Synapse 資料總管中內嵌至資料表的資料會受制於資料表的有效保留原則。 除非明確設定於資料表上,否則有效保留原則會衍生自資料庫的保留原則。 熱保留是叢集大小和保留原則的函式。 內嵌的資料超過您的可用空間,將會強制第一筆資料冷保留。
請確定資料庫的保留原則適合您的需求。 如果不是,請在資料表層級明確覆寫。 如需詳細資訊,請參閱保留原則。
建立資料表
為了內嵌資料,必須事先建立資料表。 使用下列其中一個選項:
使用命令建立資料表。 如需使用建立資料表命令的範例,請參閱使用資料總管進行分析.
使用單鍵擷取建立資料表。
注意
如果記錄不完整或無法將欄位剖析為所需的資料類型,則會將對應的資料表資料行填入 null 值。
建立結構描述對應
結構描述對應可協助將來源資料欄位繫結至目的地資料表資料行。 對應可讓您根據定義的屬性,將不同來源的資料放入相同的資料表。 支援不同類型的對應,包括資料列導向 (CSV、JSON 和 AVRO) 和資料行導向 (Parquet)。 在大多數的方法中,對應也可以在資料表上預先建立並從內嵌命令參數進行參考。
設定更新原則 (選擇性)
某些資料格式對應 (Parquet、JSON 和 Avro) 支援簡單且實用的內嵌時間轉換。 如果在內嵌時需要更複雜的處理,請使用更新原則,這可讓您使用 Kusto 查詢語言命令進行輕量型處理。 更新原則會自動對原始資料表上內嵌的資料執行擷取和轉換,並將結果產生的資料內嵌到一或多個目的地資料表。 將您的更新原則。