如何在 Azure Synapse Analytics 中使用無伺服器 SQL 集區使用 OPENROWSET
OPENROWSET(BULK...) 函式可讓您存取 Azure 儲存體中的檔案。 OPENROWSET 函式會讀取遠端資料來源 (例如檔案) 的內容,並以一組資料列傳回內容。 在無伺服器 SQL 集區資源中,OPENROWSET BULK 資料列集提供者可透過呼叫 OPENROWSET 函式及指定 BULK 選項加以存取。
您可以依照參考資料表名稱 OPENROWSET 的相同方式,在查詢的 FROM 子句中參考 OPENROWSET 函式。 其也支援透過內建 BULK 提供者執行大量作業,可讓檔案資料被讀取,並且當做資料列集傳回。
注意
專用 SQL 集區不支援 OPENROWSET 函式。
資料來源
Synapse SQL 中的 OPENROWSET 函式會從資料來源讀取檔案的內容。 資料來源是 Azure 儲存體帳戶,其可以在 OPENROWSET 函式中明確參考,也可以從您想要讀取的檔案 URL 進行動態推斷。
OPENROWSET 函式可以選擇性地包含 DATA_SOURCE 參數,以指定包含檔案的資料來源。
沒有
DATA_SOURCE的OPENROWSET可以用來直接從指定為BULK選項的 URL 位置讀取檔案內容:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
在沒有預先設定的情況下,這是可快速且簡便讀取檔案內容的方式。 此選項可讓您使用基本驗證選項來存取儲存體 (針對 Microsoft Entra 登入使用 Microsoft Entra 傳遞,針對 SQL 登入使用 SAS 權杖)。
具有
DATA_SOURCE的OPENROWSET可用來存取指定儲存體帳戶上的檔案:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]此選項可讓您在資料來源中設定儲存體帳戶的位置,並指定應該用來存取儲存體的驗證方法。
重要
沒有
DATA_SOURCE的OPENROWSET會提供快速且輕鬆的方式來存取儲存體檔案,但其提供的驗證選項有限。 例如,Microsoft Entra 主體只能使用其 Microsoft Entra 身分識別來存取檔案,或只能存取公用檔案。 如果您需要更強大的驗證選項,請使用DATA_SOURCE選項,並定義您要用來存取儲存體的認證。
安全性
資料庫使用者必須擁有 ADMINISTER BULK OPERATIONS 權限,才能使用 OPENROWSET 函式。
儲存體管理員也必須藉由提供有效的 SAS 權杖或啟用 Microsoft Entra 主體來存取儲存體檔案,才能讓使用者存取檔案。 若要深入了解儲存體的存取控制,請參閱本文。
OPENROWSET 會使用下列規則來決定如何向儲存體進行驗證:
- 在沒有
DATA_SOURCE的OPENROWSET中,驗證機制會視呼叫者類型而定。- 任何使用者都可使用
OPENROWSET讀取 Azure 儲存體上的公用檔案,而不需要DATA_SOURCE。 - 如果 Azure 儲存體允許 Microsoft Entra 使用者存取基礎檔案 (例如,如果呼叫者具有 Azure 儲存體的
Storage Reader權限),則 Microsoft Entra 登入可使用其本身的 Microsoft Entra 身分識別來存取受保護的檔案。 - SQL 登入也可以使用沒有
DATA_SOURCE的OPENROWSET來存取公用檔案、使用 SAS 權杖保護的檔案或 Synapse 工作區的受控識別。 您需要建立伺服器範圍的認證,以允許存取儲存體檔案。
- 任何使用者都可使用
- 在具有
DATA_SOURCE的OPENROWSET中,驗證機制會在指派給參考資料來源的資料庫範圍認證中定義。 此選項可讓您存取公用儲存體,或使用 SAS 權杖、工作區的受控識別或呼叫者的 Microsoft Entra 身分識別 (如果呼叫者是 Microsoft Entra 主體) 來存取儲存體。 如果DATA_SOURCE參照非公用的 Azure 儲存體,您就必須建立資料庫範圍的認證,並在DATA SOURCE中加以參考,才能允許存取儲存體檔案。
呼叫者必須具有認證的 REFERENCES 權限,才能使用該認證向儲存體進行驗證。
語法
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
引數
您有三個輸入檔選擇,其中皆包含要查詢的目標資料。 有效值為:
'CSV' - 包含具有資料列/資料行分隔符號的任何分隔文字檔。 任何字元都可以做為欄位分隔符號使用,例如 TSV: FIELDTERMINATOR = tab。
'PARQUET' - Parquet 格式的二進位檔案。
'DELTA' - 以 Delta Lake (預覽) 格式整理的一組 Parquet 檔案。
空白字元無效。 例如,'CSV ' 不是有效的值。
'unstructured_data_path'
建立資料路徑的 unstructured_data_path 可能是絕對或相對路徑:
- 格式為
\<prefix>://\<storage_account_path>/\<storage_path>的絕對路徑可讓使用者直接讀取檔案。 - 格式為
<storage_path>的相對路徑必須與DATA_SOURCE參數搭配使用,並在EXTERNAL DATA SOURCE中定義的 <storage_account_path> 位置內描述檔案模式。
您可以在下面找到將連結至特定外部資料來源的相關<儲存體帳戶路徑>。
| 外部資料來源 | Prefix | 儲存體帳戶路徑 |
|---|---|---|
| Azure Blob 儲存體 | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob 儲存體 | wasb[s] | <container>@<storage_account>.blob.core.windows.net/path/file |
| Azure Data Lake Store Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
'<storage_path>'
指定儲存體內的路徑,其指向您想要讀取的資料夾或檔案。 如果路徑指向容器或資料夾,則會從該特定容器或資料夾讀取所有檔案。 子資料夾中的檔案不會包含在內。
您可以使用萬用字元將目標設為多個檔案或資料夾。 允許使用多個不連續的萬用字元。
以下範例表示會從所有開頭為 /csv/population 的資料夾中,讀取所有開頭為 population的 csv 檔案:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
如果您將 unstructured_data_path 指定為資料夾,無伺服器 SQL 集區查詢將會從該資料夾擷取檔案。
您可以在路徑結尾指定/*,指示無伺服器 SQL 集區瀏覽資料夾,如範例所示:https://sqlondemandstorage.blob.core.windows.net/csv/population/**
注意
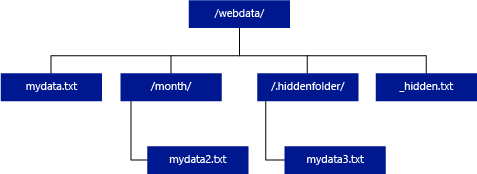
與 Hadoop 和 PolyBase 不同的是,無伺服器 SQL 集區不會傳回子資料夾,除非您在路徑結尾指定 /**。 如同 Hadoop 和 PolyBase,其不會傳回檔案名稱開頭為底線 (_) 或英文句號 (.) 的檔案。
在下列範例中,若 unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/,無伺服器 SQL 集區查詢將會傳回 mydata.txt 中的資料列。 而不會傳回 mydata2 .txt 和 mydata3.txt,因為位於子資料夾中。
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
WITH 子句可讓您指定要從檔案讀取的資料行。
針對 CSV 資料檔案,應提供資料行名稱及其資料類型,才能讀取所有資料行。 如果您想要讀取一小組資料行,請使用序數從原始資料檔案中依序挑選資料行。 資料行將會以加上順序的指派來繫結。 如果使用 HEADER_ROW = TRUE,則會以資料行名稱來執行資料行繫結,而不是序數位置。
提示
您也可以針對 CSV 檔案省略 WITH 子句。 系統會從檔案內容自動推斷資料類型。 您可以使用 HEADER_ROW 引數指定標頭資料列的存在;在此情況下,系統會從標頭資料列讀取資料行名稱 。 如需詳細資料,請參閱自動結構描述探索。
針對 Parquet 或 Delta Lake 檔案,請提供與原始資料檔案中資料行名稱相符的資料行名稱。 資料行會依名稱繫結,並且區分大小寫。 如果省略 WITH 子句,則會傳回 Parquet 檔案中的所有資料行。
重要
Parquet 和 Delta Lake 檔案中的資料行名稱會區分大小寫。 若您指定的資料行名稱大小寫與檔案中資料行名稱的大小寫不同,則會針對該資料行傳回
NULL值。
column_name = 輸出資料行的名稱。 如果有提供,此名稱會覆寫來源檔案中的資料行名稱,以及 JSON 路徑中提供的資料行名稱 (如果有的話)。 如果未提供 json_path,則會自動新增為 '$.column_name'。 檢查行為的 json_path 引數。
column_type = 輸出資料行的資料類型。 隱含的資料類型轉換將會在此進行。
column_ordinal = 來源檔案中資料行的序數。 Parquet 檔案會忽略這個引數,因為繫結是根據名稱來進行。 下列範例只會從 CSV 檔案傳回第二個資料行:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = 資料行或巢狀屬性的 JSON 路徑運算式。 預設路徑模式為 lax 模式。
注意
在 strict 模式中,如果提供的路徑不存在,則查詢會失敗。 在 lax 模式中,查詢將會成功,而且 JSON 路徑運算式會評估為 Null。
<bulk_options>
FIELDTERMINATOR ='field_terminator'
指定要使用的欄位結束字元。 預設的欄位結束字元為逗號 (",")。
ROWTERMINATOR ='row_terminator'`
指定要使用的資料列結束字元。 如果未指定資料列結束字元,則會使用其中一個預設的結束字元。 PARSER_VERSION = '1.0' 的預設結束字元是 \r\n、\n 和 \r。 PARSER_VERSION = '2.0' 的預設結束字元是 \r\n 和 \n。
注意
使用 PARSER_VERSION='1.0' 並指定 \n (新行) 作為資料列結束字元時,其會自動以 \r (歸位字元) 字元當作前置詞,而產生資料列結束字元 \r\n。
ESCAPE_CHAR = 'char'
指定檔案中用來將本身和所有分隔符號值逸出的字元。 如果逸出字元後面接著本身或任何分隔符號值以外的值,讀取值時就會捨棄逸出字元。
無論 FIELDQUOTE 已啟用或未啟用,都會套用 ESCAPECHAR 參數。 其不會用來逸出引號字元。 引號字元必須以另一個引號字元來逸出。 只有在以引號字元封住值時,引號字元才能在資料行值中出現。
FIRSTROW = 'first_row'
指定要載入之第一個資料列的號碼。 預設值是 1,表示所指定資料檔案中的第一個資料列。 資料列號碼是由計算資料列結束字元所決定。 FIRSTROW 是以 1 為基底。
FIELDQUOTE = 'field_quote'
指定將用來當作 CSV 檔案中引號字元的字元。 如果未指定,則會使用引號字元 (")。
DATA_COMPRESSION = 'data_compression_method'
指定壓縮方法。 僅在 PARSER_VERSION='1.0' 中支援。 以下是支援的壓縮方法:
- GZIP
PARSER_VERSION = 'parser_version'
指定讀取檔案時要使用的剖析器版本。 目前支援的 CSV 剖析器版本為 1.0 和 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
CSV 剖析器 1.0 版為預設值,功能豐富。 2.0 版是為提高效能而建立的,並不支援所有選項和編碼。
CSV 剖析器 1.0 版的詳細資訊:
- 不支援下列選項:HEADER_ROW。
- 預設結束字元為 \r\n、\n 和 \r。
- 若您指定 \n (新行) 做為資料列結束字元,其會自動以 \r (歸位字元) 字元當作前置詞,而產生資料列結束字元 \r\n。
CSV 剖析器 2.0 版的詳細資訊:
- 未支援所有資料類型。
- 字元資料行長度上限為 8000。
- 資料列大小的上限為 8 MB。
- 不支援下列選項:DATA_COMPRESSION。
- 以引號括住的空字串 ("") 會被視為空字串。
- 不接受 DATEFORMAT SET 選項。
- DATE 資料類型支援的格式:YYYY-MM-DD
- TIME 資料類型支援的格式:HH:MM:SS[.fractional seconds]
- DATETIME2 資料類型支援的格式:YYYY-MM-DD HH:MM:SS[.fractional seconds]
- 預設結束字元為 \r\n 和 \n。
HEADER_ROW = { TRUE | FALSE }
指定 CSV 檔案是否包含標頭資料列。 預設為FALSE.在 PARSER_VERSION='2.0' 中支援。 若為 TRUE,則會根據 FIRSTROW 引數,從第一個資料列讀取資料行名稱。 若為 TRUE,且結構描述是使用 WITH 指定的,則會以資料行名稱來執行資料行名稱的繫結,而不是序數位置。
DATAFILETYPE = { 'char' | 'widechar' }
指定編碼:char 用於 UTF8,widechar 用於 UTF16 檔案。
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
指定資料檔案中之資料的字碼頁。 預設值為 65001 (UTF-8 編碼)。 如需此選項的詳細資訊,請參閱此處。
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
此選項會在查詢執行期間停用檔案修改檢查,並在執行查詢時讀取更新的檔案。 當您需要讀取在執行查詢時附加的僅附加檔案時,這是很有用的選項。 在可附加的檔案中,現有的內容不會更新,而只會新增資料列。 因此,相較於可更新的檔案,這會將錯誤結果的機率降到最低。 此選項可讓您讀取經常附加的檔案,而無須處理錯誤。 如需詳細資訊,請參閱查詢可附加的 CSV 檔案一節。
拒絕選項
注意
拒絕資料列功能處於公開預覽狀態。 請注意,拒絕資料列功能適用於分隔文字檔和 PARSER_VERSION 1.0。
擷取外部資料來源時,您可以指定拒絕參數,決定服務如何處理已變更記錄。 若實際資料類型與外部資料表的資料行定義不相符,系統就會將資料記錄視為「已變更」。
不指定或變更拒絕選項時,服務會使用預設值。 服務將使用拒絕選項來判斷在實際查詢失敗前,可以拒絕的資料列數目。 查詢將會傳回 (部分) 結果,直到超過拒絕閾值為止。 接著它便會失敗並顯示適當的錯誤訊息。
MAXERRORS = reject_value
請指定在查詢失敗前可拒絕的資料列數目。 MAXERRORS 必須是介於 0 與 2,147,483,647 之間的整數。
ERRORFILE_DATA_SOURCE = data source
指定應寫入已拒絕資料列和對應錯誤檔案的資料來源。
ERRORFILE_LOCATION = Directory Location
指定 DATA_SOURCE (或 ERROR_FILE_DATASOURCE,若指定) 中,已拒絕資料列和對應錯誤檔案應寫入的目錄。 若指定的路徑不存在,服務會代為建立目錄。 會建立名稱為 "rejectedrows" 的子目錄。" " 字元可確保該目錄從其他資料處理逸出,除非已明確在位置參數中指名。 在此目錄中,建立的資料夾會根據載入提交時間,使用 YearMonthDay_HourMinuteSecond_StatementID 格式 (例如,20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891)。 您可使用陳述式識別碼,讓資料夾與產生識別碼的查詢相互關聯。 在此資料夾中會寫入兩個檔案:error.json 檔案和資料檔案。
error.json 檔案包含 json 陣列,及拒絕資料列發生的錯誤。 代表錯誤的元素都包含下列屬性:
| 屬性 | 描述 |
|---|---|
| 錯誤 | 資料列被拒絕的原因。 |
| 資料列 | 檔案中的拒絕資料列序數。 |
| 資料行 | 拒絕資料行序數。 |
| 值 | 拒絕資料行值。 如果值大於 100 個字元,則僅顯示前 100 個字元。 |
| 檔案 | 資料列所屬的檔案路徑。 |
快速分隔符號文字剖析
有兩個分隔文字剖析器版本可供您使用。 CSV 剖析器 1.0 版是預設項目且功能豐富,而剖析器 2.0 版為提高效能而建立。 進階的剖析技術和多執行緒處理造就了剖析器 2.0 版的效能改善。 隨著檔案大小的增加,速度的差異會變大。
自動結構描述探索
您可以輕鬆地查詢 CSV 和 Parquet 檔案,無需了解或藉由省略 WITH 子句來指定結構描述。 系統會從檔案推斷資料行名稱和資料類型。
Parquet 檔案包含會讀取的資料行中繼資料,在 Parquet 的 類型對應 中可以找到類型對應。 參閱讀取 Parquet 檔,但不指定範例的架構。
可以從標頭資料列中讀取 CSV 檔案的資料行名稱。 您可以使用 HEADER_ROW 引數來指定標頭資料列是否存在。 如果 HEADER_ROW = FALSE,則會使用一般資料行名稱:C1, C2, ...Cn,其中 n 是檔案中的資料行數目。 系統會從前 100 個資料列推斷資料類型。 參閱讀取 CSV 檔,但不指定範例的架構。
請記住,如果您正在一次讀取多個檔案,則將從儲存體中取得的第一個檔案服務推斷出結構描述。 這可能表示會省略某些預期的資料行,全部是因為服務用來定義架構的檔案不包含這些資料行。 在此情況下,請使用 OPENROWSET WITH 子句。
重要
在某些情況下,由於缺少資訊而無法推斷適當的資料類型,因此將改用較大的資料類型。 這會帶來效能上的額外負荷,對於推斷為 varchar(8000) 的字元資料行而言,影響甚鉅。 為了達到最佳效能,請檢查推斷資料類型並使用適當的資料類型。
Parquet 的類型對應
Parquet 和 Delta Lake 檔案包含每個資料行的類型描述。 下表說明 Parquet 類型如何對應至 SQL 原生類型。
| Parquet 類型 | Parquet 邏輯類型 (註釋) | SQL 資料類型 |
|---|---|---|
| BOOLEAN | bit | |
| BINARY / BYTE_ARRAY | varbinary | |
| DOUBLE | float | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | [UTF8] | varchar (UTF8 collation) |
| BINARY | 字串 | varchar (UTF8 collation) |
| BINARY | ENUM | varchar (UTF8 collation) |
| FIXED_LEN_BYTE_ARRAY | UUID | UNIQUEIDENTIFIER |
| BINARY | DECIMAL | decimal |
| BINARY | JSON | varchar(8000) *(UTF8 定序) |
| BINARY | BSON | 不支援 |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimal |
| BYTE_ARRAY | INTERVAL | 不支援 |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | 日期 | date |
| INT32 | DECIMAL | decimal |
| INT32 | TIME (MILLIS) | time |
| INT64 | INT(64, true) | BIGINT |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | decimal |
| INT64 | TIME (MICROS) | time |
| INT64 | TIME (NANOS) | 不支援 |
| INT64 | TIMESTAMP (標準化為 utc) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (未標準化為 utc) (MILLIS / MICROS) | bigint - 請務必先使用時區位移來明確調整 bigint 值,再將它轉換成日期時間值。 |
| Int64 | TIMESTAMP (NANOS) | 不支援 |
| 複雜類型 | 清單 | varchar(8000),序列化為 JSON |
| 複雜類型 | MAP | varchar(8000),序列化為 JSON |
範例
讀取 CSV 檔案但不指定結構描述
下列範例會讀取包含標頭資料列的 CSV 檔案,而不指定資料行名稱和資料類型:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
下列範例會讀取不包含標頭資料列的 CSV 檔案,而不指定資料行名稱和資料類型:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
讀取 Parquet檔案但不指定結構描述
下列範例會在不指定資料行名稱和資料類型的情況下,從 Parquet 格式的人口普查資料集中,傳回第一個資料列的所有資料行:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
在不指定結構描述的情況下讀取 Delta Lake 檔案
下列範例會在不指定資料行名稱和資料類型的情況下,從 Delta Lake 格式的人口普查資料集中,傳回第一個資料列的所有資料行:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
從 CSV 檔案讀取特定資料行
下列範例只會從 population*.csv 檔案 中傳回序號為 1 和 4 的兩個資料行。 由於檔案中沒有標頭資料列,因此會從第一行開始讀取:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
從 Parquet 檔案讀取特定資料行
下列範例只會從 Parquet 格式的人口普查資料集中,傳回第一個資料列的兩個資料行:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
使用 JSON 路徑指定資料行
下列範例示範如何在 WITH 子句中使用 JSON 路徑運算式,並示範 strict 和 lax 路徑模式之間的差異:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
指定 BULK 路徑中的多個檔案/資料夾
下列範例顯示如何在 BULK 參數中使用多個檔案/資料夾路徑:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
下一步
如需更多範例,請參閱查詢資料儲存體快速入門,以瞭解如何使用 OPENROWSET 來讀取 CSV、PARQUET、DELTA LAKE 和 JSON 檔案格式。 參閱最佳做法以達到最佳效能。 您也可以了解如何使用 CETAS,將查詢結果儲存到 Azure 儲存體。