擷取擴增世代 (RAG) 提供 LLM 知識
本文描述擷取擴增世代如何讓 LLM 將您的資料源視為知識,而不必定型。
LLM 透過定型具有廣泛的知識庫。 針對大部分案例,您可以選取專為需求設計的 LLM,但這些 LLM 仍然需要額外的定型,才能了解您的特定資料。 擷取擴增世代讓您可將資料供 LLM 使用,而不需先對其進行定型。
RAG 的運作方式
若要執行擷取擴增世代,您可以為資料建立內嵌,以及有關其的常見問題。 您可以即時執行此動作,或可以使用向量資料庫解決方案來建立和儲存內嵌。
當使用者提出問題時,LLM 會使用您的內嵌來比較使用者的問題與您的資料,並尋找最相關的內容。 此內容和使用者的問題接著會在提示中移至 LLM,然後 LLM 會根據您的資料提供回應。
基本 RAG 流程
若要執行 RAG,您必須處理要用於擷取的每個資料來源。 基本程序如下:
- 將大型資料分割成可管理的片段。
- 將區塊轉換成可搜尋的格式。
- 將轉換後的資料儲存在允許有效存取的位置。 此外,當 LLM 提供回應時,請務必儲存引文或參考的相關中繼資料。
- 在提示中將轉換後的資料饋送至 LLM。
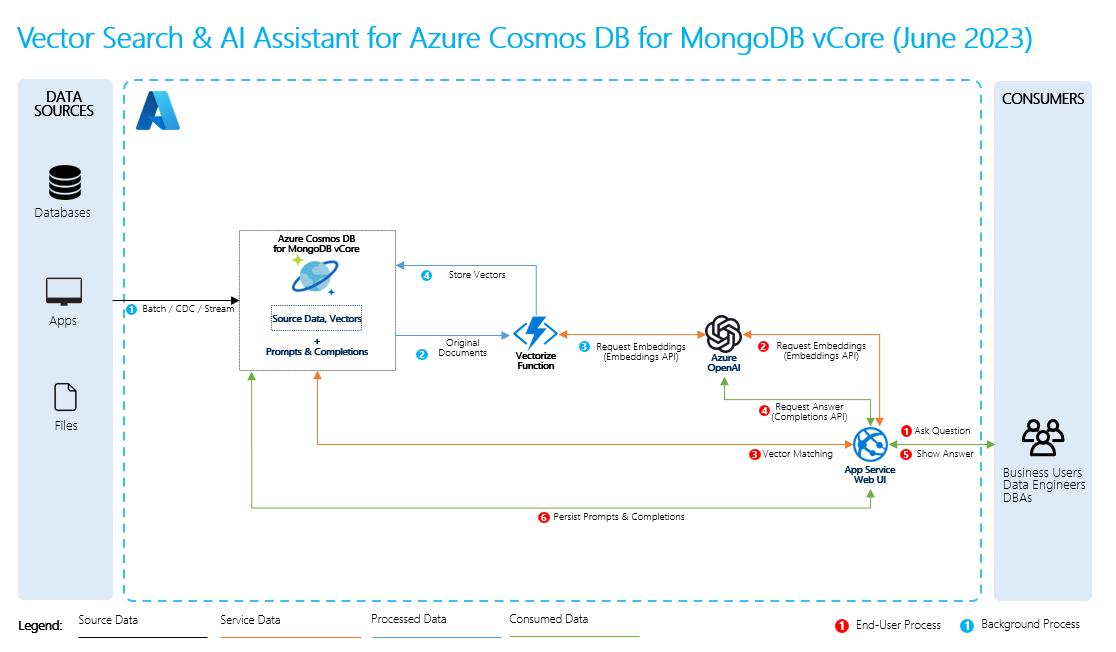
- 來源資料:這是您資料存在的位置。 其可以是您電腦上的檔案/資料夾、雲端儲存空間中的檔案、Azure Machine Learning 資料資產、Git 存放庫或 SQL 資料庫。
- 資料區塊化:來源中的資料必須轉換成純文本。 例如,文字文件或 PDF 必須破解開啟並轉換成文字。 然後,文字會區分成較小的片段。
- 將文字轉換成向量:這些是內嵌。 向量是將數值表示法轉換為數列的概念,以便電腦了解這些概念間的關係。
- 來源資料與內嵌之間的連結:此資訊會儲存為您所建立區塊上的中繼資料,然後用來協助 LLM 在產生回應時產生引文。