資料統一最佳做法
設定規則以將資料統整在客戶設定檔中時,請考慮下列最佳做法:
平衡統整時間與完成比對時間。 嘗試擷取每個可能比對相符項目會導致許多規則和統整需要很長時間。
逐步新增規則並追蹤結果。 移除無法改善比對結果的規則。
對每個表刪除每個重複的資料表,讓每個客戶都是以單一資料列來表示。
在資料輸入方式上使用正規化來標準化變化,例如 Street 之於 St、St. 和 st.。
有策略地使用模糊比對來更正錯字或錯誤,例如 bob@contoso.com 和 bob@contoso.cm。相較於完全相符比對,模糊比對需要更長的執行時間。 務必測試一下,看看花費在模糊比對的額外時間是否值得額外增加的比對相符率。
使用完全相符縮小比對範圍。 確保每個使用模糊條件的規則都至少有一個完全相符比對條件。
不要比對包含大量重複資料的資料行。 確保模糊比對的資料行沒有頻繁重複的值,例如表單的預設值 “Firstname”。
統整效能
每個規則都需要時間來執行。 諸如將每個資料表與每個其他資料表進行比較,或嘗試擷取每個可能相符記錄之類的模式,都可能導致統整處理時間加長。 這還會傳回幾個 (如果有) 比一個將每個資料表與基底資料表進行比較之計劃更多的相符項目
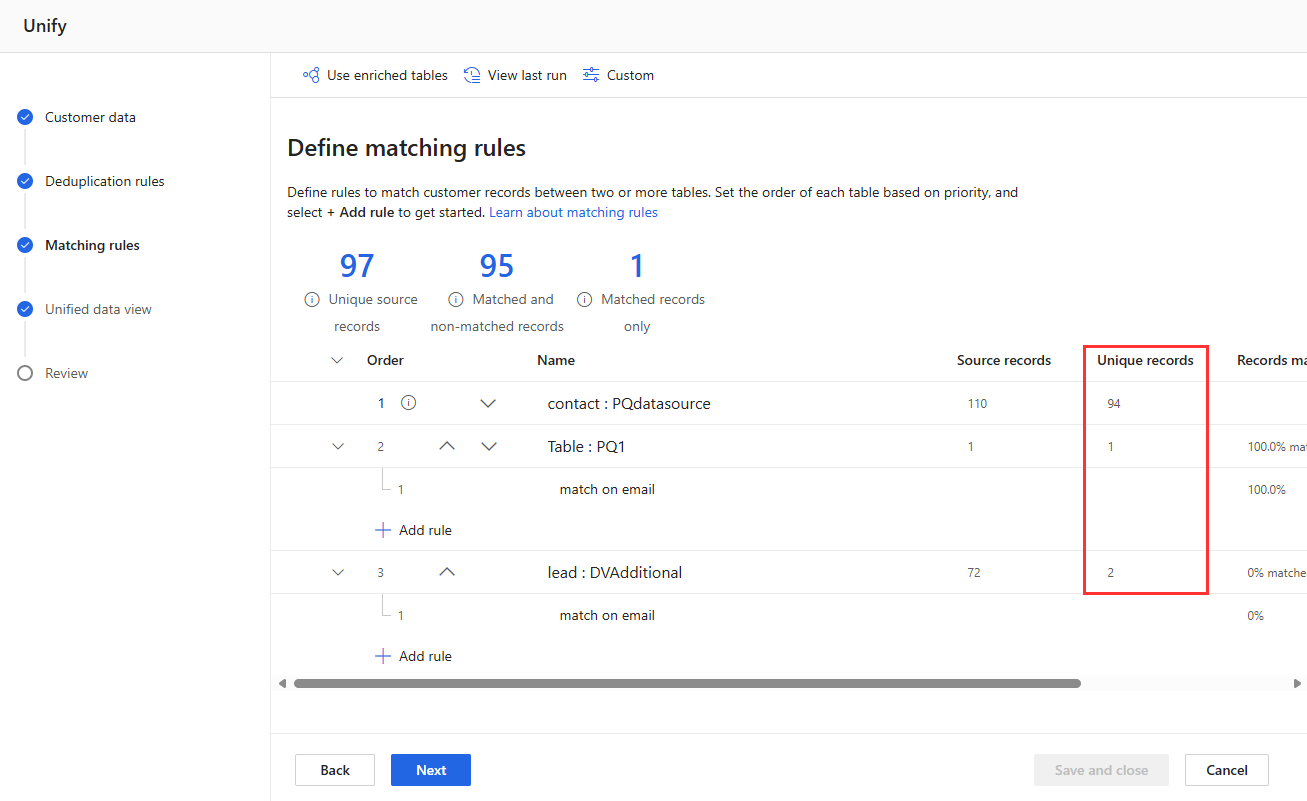
最好的方法是從一組您知道需要的基本規則開始,例如將每個資料表與主要資料表進行比較。 主要資料表必須是包含最完整且正確資料的資料表。 此資料表應排序在比對規則統整步驟的最上方。
逐步新增多個規則,並查看執行變更所需的時間以及結果是否有所改善。 移至設定>系統>狀態,然後選取比對,以查看每次統整執行需要多少時間進行重複資料刪除和比對。
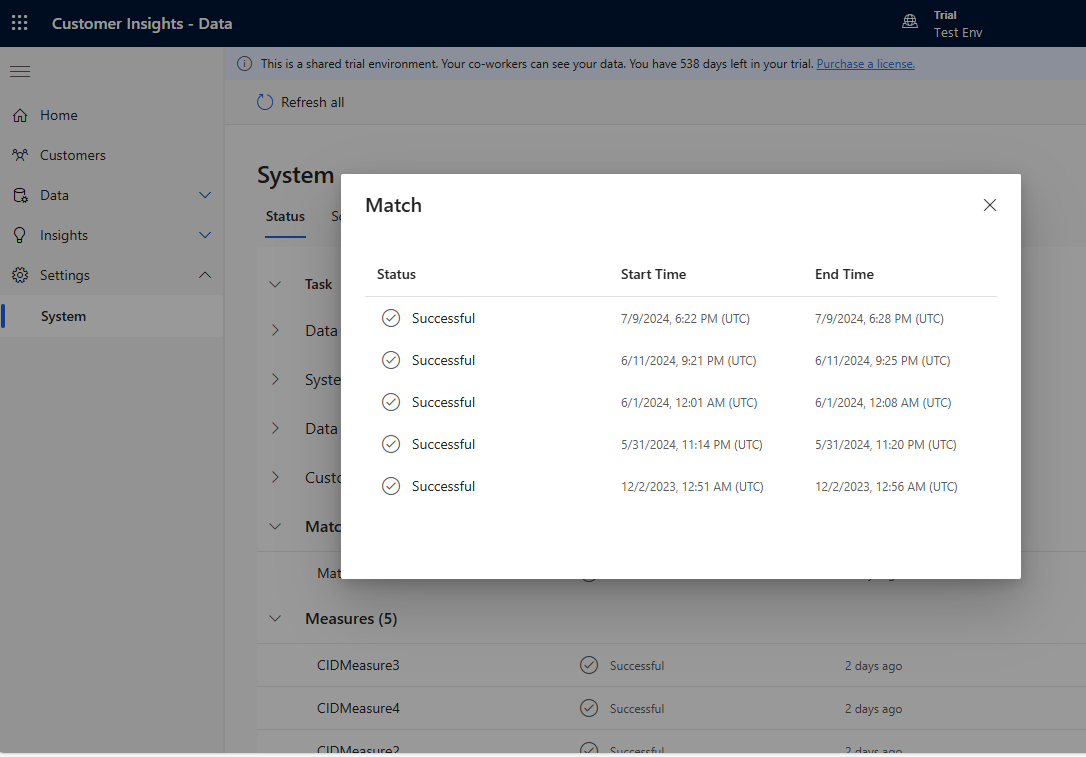
檢視重複資料刪除規則和比對規則頁面上的規則統計資料,以查看不重複記錄的數量是否變更。 如果新規則經比對找到一些相符記錄,但不重複記錄計數並未變更,則表示上一個規則找出了這些相符記錄。
重複資料刪除
使用重複資料刪除規則移除資料表中重複的客戶記錄,讓每個資料表中的單一資料列表示個別客戶。 良好的規則會找出唯一的客戶。
在此簡單範例中,記錄 1、2 和 3 共用電子郵件或電話號碼,並且代表同一個人。
| 識別碼 | 名稱 | 手機 | |
|---|---|---|---|
| 7 | 人員 1 | (425) 555-1111 | AAA@A.com |
| 2 | 人員 1 | (425) 555-1111 | BBB@B.com |
| 3 | 人員 1 | (425) 555-2222 | BBB@B.com |
| 4 | 人員 2 | (206) 555-9999 | Person2@contoso.com |
我們不希望只是根據名稱進行比對,因為這樣會比對出名稱相同的不同人員。
使用與記錄 1 和 2 比對相符的姓名和電話來建立規則 1。
使用與記錄 2 和 3 比對相符的姓名和電子郵件來建立規則 2。
規則 1 與規則 2 的組合建立了單一比對群組,因為這些規則都同樣找到記錄 2。
您可以決定唯一識別客戶之規則和條件的數量。 確切的規則取決於您可用於比對的資料、資料品質以及您希望重複資料刪除程序的詳盡程度。
正規化
使用正規化進行資料標準化以產生更好的比對結果。 正規化在大型資料集上表現良好。
正規化資料僅用於比較目的,以便更有效地比對客戶記錄。 不會變更最終統一客戶設定檔輸出中的資料。
完全相符
使用精確度判斷兩個字串應有多接近才能視為相符項目。 預設精確度設定要求完全相符。 任何其他值都會啟用該條件的模糊比對。
精確度可以設定為低 (30% 相符)、中 (60% 相符) 和高 (80% 相符)。 或者,也可以自訂和設定以 1% 為增量的精確度。
完全相符比對條件
首先執行完全相符比對條件,以取得較小的模糊比對值集。 為了產生預期結果,完全相符比對條件必須有合理程度的唯一性。 例如,如果您所有的客戶都居住在同一個國家/地區,那麼根據國家/地區的完全相符比對無助於縮小範圍。
全名、電子郵件、電話或地址欄位等資料行有良好的唯一性,是非常適合用於完全相符比對的欄位。
確定用於完全相符比對條件的資料行沒有任何頻繁重複的值,例如表單擷取的預設值 “Firstname”。 Customer Insights 可以分析資料行來提供對主要重複值的見解。 您可以在 Azure Data Lake (使用 Common Data Model 或 Delta 格式) 連接和 Synapse 上啟用資料分析。 下次重新整理資料來源時,將會執行資料設定檔。 如需詳細資訊,請移至資料分析。
模糊比對
使用模糊比對來比對因誤植或其他微小變化而接近但不完全相符的字串。 有策略地使用模糊比對,因為這會比完全相符比對還要慢。 確保任何有模糊條件的規則都至少有一個完全相符比對條件。
模糊比對不適用於擷取像 Suzzie 和 Suzanne 這樣的名稱變化。 使用正規化模式類型:名稱或自訂別名比對 (客戶可以輸入他們要視為比對相符的名稱變化清單) 擷取這些變化的效果更好。
您可以將條件新增至規則,例如比對名字和電話。 指定規則中的條件是「和」條件。 每項條件都必須符合,資料列才算相符項目。 單獨的規則是「或」條件。 如果規則 1 不符合資料列,則會將這些資料列與規則 2 進行比較。
注意
只有資料類型為字串的欄才可以使用模糊比對。 對於具有其他資料類型 (例如整數、雙精確度或日期時間) 的資料行,精確度欄位是唯讀欄位且設定為完全相符比對。
模糊比對計算
模糊比對是計算兩個字串之間的編輯距離分數來判定。 如果分數達到或超過精確度閾值,則將字串視為相符項目。
編輯距離是透過新增、刪除或變更字元將一個字串轉換為另一個字串所需的編輯次數。
例如,移除 q、u、e、i 和 e 字元並插入 y 字元時,字串 “Jacqueline” 與 “Jaclyne” 的編輯距離為 5。
若要計算編輯距離分數,請使用此公式:(基準字串長度 – 編輯距離)/基準字串長度。
| 基準字串 | 比較字串 | 分數 |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0.857 |
| franklin | frank | (8-3) / 8 = 0.625 |