Apache Spark 建議程式,以取得筆記本上的即時建議
Apache Spark 建議程式會分析 Apache Spark 所執行的命令和程式碼,並顯示筆記本執行的即時建議。 Apache Spark 建議程式具有內建模式,可協助使用者避免常見的錯誤。 它提供程式碼最佳化的建議、執行錯誤分析,並找出失敗的根本原因。
內建建議
Spark 建議程式是與Pulss整合的工具,提供內建模式來偵測和解決 Apache Spark 應用程式中的問題。 本文說明工具中包含的一些模式。
您可以根據您需要的建議類型開啟 最近執行窗格。
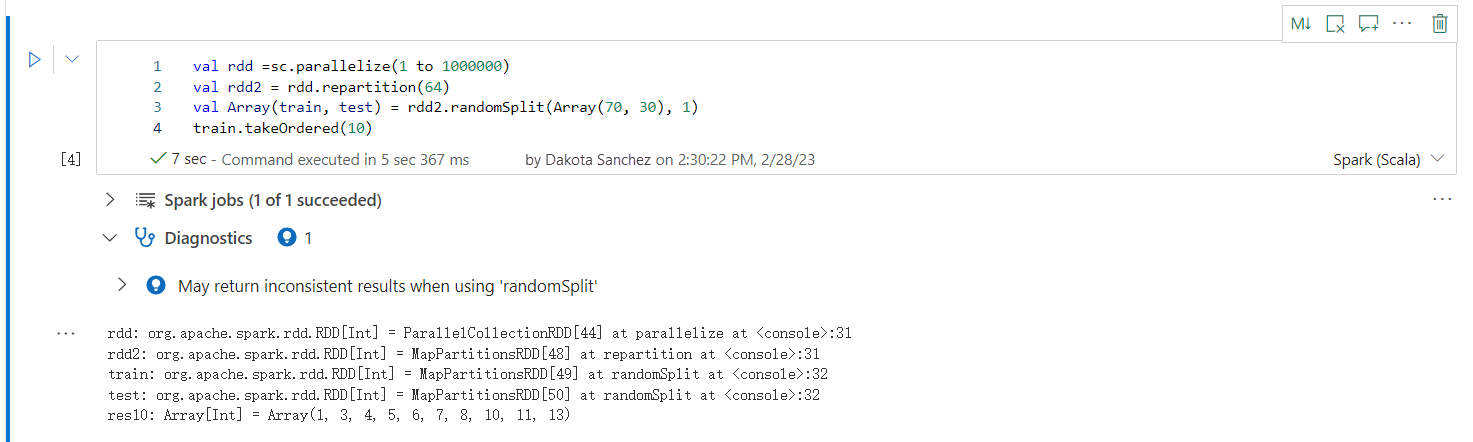
使用「randomSplit」時可能會傳回不一致的結果
使用 randomSplit 方法時,可能會傳回不一致或不正確的結果。 使用 randomSplit() 方法之前,請先使用 Apache Spark (RDD) 快取。
randomSplit() 方法相當於多次在資料框架上執行 sample()。 其中每個範例會重新擷取、分割區,以及排序資料分割中的資料框架。 跨分割區和排序順序的資料分佈對於 randomSplit() 和 sample() 都很重要。 如果資料重新參考時有任何變更,則分割之間可能會有重複值或遺漏值。 使用相同種子的相同樣本可能會產生不同的結果。
這些不一致可能不會在每次執行時發生,但為了完全消除它們、快取您的資料框架、在資料行上重新分割,或套用 groupBy 等聚合函數。
資料表/檢視名稱已在使用中
檢視已存在與已建立資料表相同的名稱,或已存在與所建立檢視相同名稱的資料表。 當此名稱用於查詢或應用程式中時,無論第一個建立哪一個檢視,都只會傳回檢視。 若要避免衝突,請重新命名資料表或檢視表。
無法辨識提示
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
找不到指定的關聯名稱
找不到提示中指定的關聯性。 確認關聯已正確拼字,且可在提示的範圍內存取。
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
查詢中的提示會阻止套用另一個提示
選取的查詢包含防止套用另一個提示的提示。
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
啟用 'spark.advise.divisionExprConvertRule.enable' 以減少捨入錯誤傳播
此查詢包含具有 Double 類型的表達式。 建議您啟用組態 'spark.advise.divisionExprConvertRule.enable',這有助於減少除法表達式,並減少四捨五入錯誤傳播。
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
啟用 'spark.advise.nonEqJoinConvertRule.enable' 以改善查詢效能
此查詢包含由於查詢內 「Or」 條件而耗費時間的聯結。 建議您啟用組態 'spark.advise.nonEqJoinConvertRule.enable',這有助於將 “Or” 條件觸發的聯結轉換為 SMJ 或 BHJ 來加速此查詢。
使用者體驗
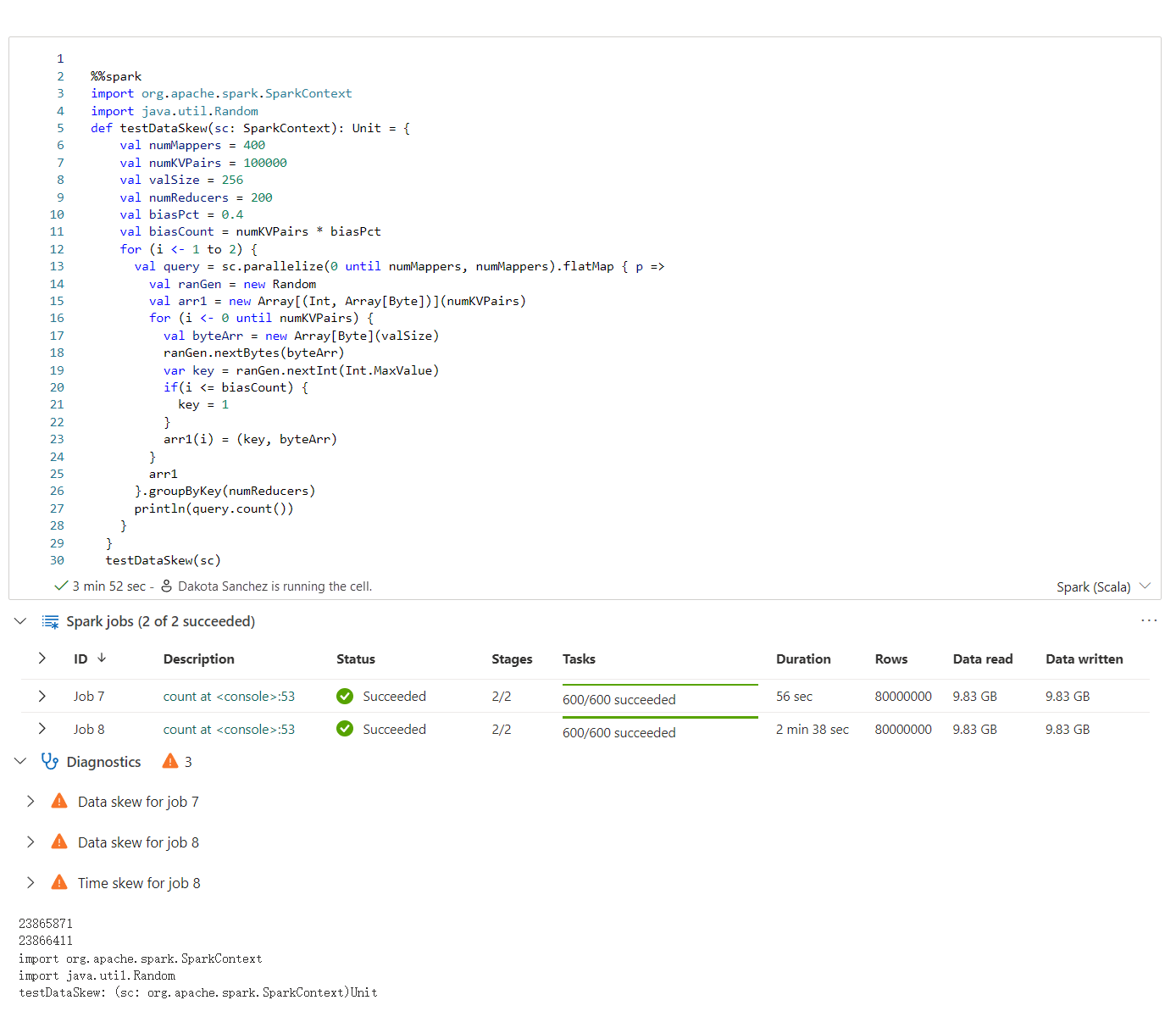
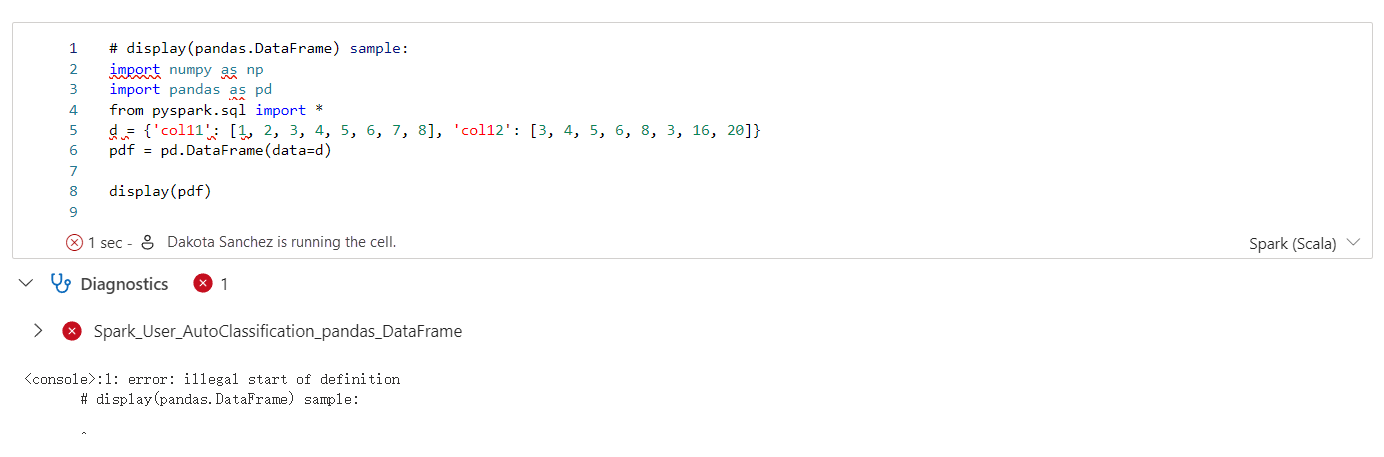
Apache Spark Advisor 會在 Notebook 儲存格輸出中即時顯示建議,包括資訊、警告和錯誤。
資訊
警告
錯誤
Spark Advisor 設定
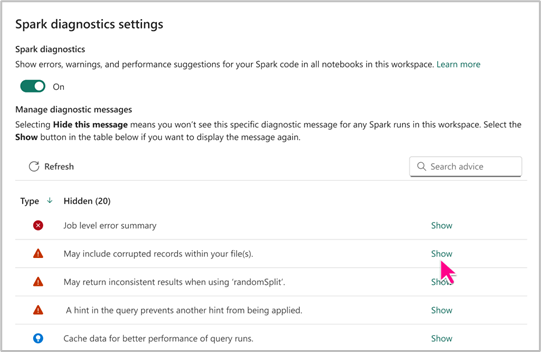
Spark 建議程式設定可讓您根據需求選擇顯示或隱藏特定類型的 Spark 建議。 此外,您可以根據喜好設定,彈性地為工作區內的 Notebook 啟用或停用 Spark Advisor。
您可以在 Fabric Notebook 層級存取 Spark Advisor 設定,以享受其優點,並確保有生產力的筆記本撰寫體驗。