在複製活動中設定 Azure Synapse Analytics
本文概述如何在資料管線中使用複製活動,從 Azure Synapse Analytics 複製資料以及將資料複製到其中。
支援的設定
對於複製活動下每個索引標籤的組態,請分別參閱下列各節。
一般
請參閱<[一般] 設定>指導,來設定 [一般] 設定索引標籤。
來源
對於 Azure Synapse Analytics,複製活動的 [來源] 索引標籤中支援下列屬性。
![螢幕擷取畫面,其中顯示 [來源] 索引標籤和屬性清單。](media/connector-azure-synapse-analytics/source.png#lightbox)
以下是必要的屬性:
資料存放區類型:選取 [外部]。
連線:從連線清單中選取 Azure Synapse Analytics 連線。 如果不存在連線,請選取 [新增],來建立新的 Azure Synapse Analytics 連線。
連線類型:選取 [Azure Synapse Analytics]。
使用查詢:可以選擇 [資料表]、[查詢] 或 [預存程序] 來讀取來源資料。 下列清單描述每個設定的組態:
資料表:如果選取此按鈕,則從 [資料表] 中指定的資料表讀取資料。 從下拉式清單中選取資料表,或選取 [編輯] 以手動輸入結構描述和資料表名稱。

查詢:指定自訂 SQL 查詢來讀取資料。 例如
select * from MyTable。 或選取鉛筆圖示以在程式碼編輯器中編輯。
預存程序:使用從來源資料表讀取資料的預存程序名稱。 最後一個 SQL 陳述式必須是預存程序中的 SELECT 陳述式。
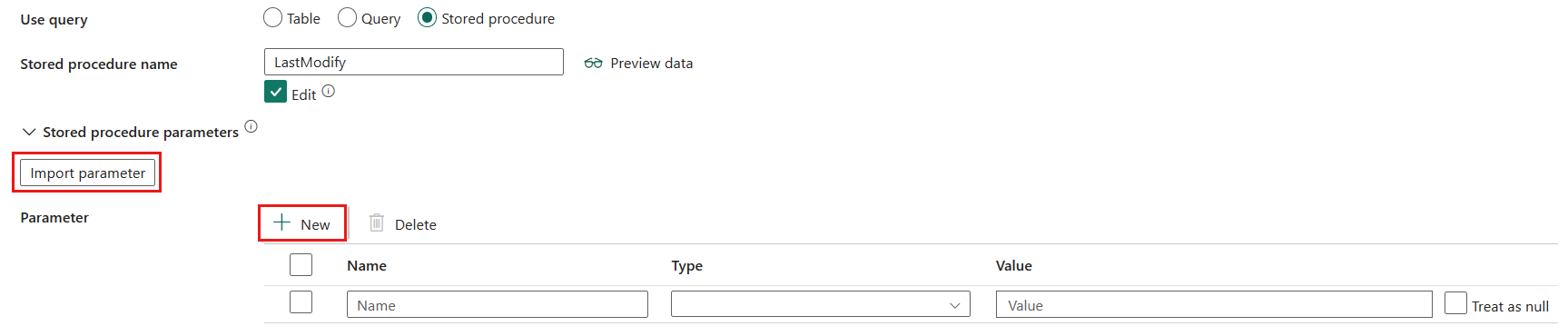
- 預存程序名稱:選取預存程序,或在選取 [編輯] 時手動指定預存程序名稱。
- 預存程序參數:選取 [匯入參數] 以匯入指定預存程序中的參數,或選取 [+ 新增] 為預存程序新增參數。 允許的值為名稱或值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。

在 [進階] 下,可以指定下列欄位:
查詢逾時 (分鐘):指定查詢命令執行的逾時,預設值為 120 分鐘。 如果為此屬性設定參數,允許的值為時間範圍,例如 "02:00:00" (120 分鐘)。
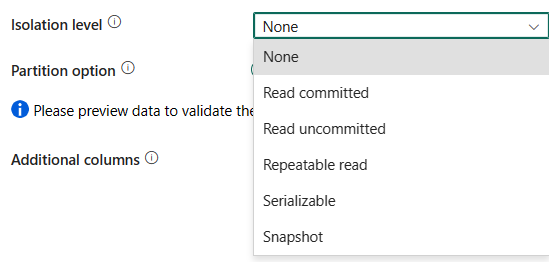
隔離等級:指定 SQL 來源的異動鎖定行為。 允許的值為:[無]、[讀取認可]、[讀取未認可]、[可重複讀取]、[可序列化] 或 [快照]。 如果未指定,則會使用 [無] 隔離等級。 如需詳細資料,請參閱<IsolationLevel 列舉>。
分割選項:指定用來從 Azure Synapse Analytics 載入資料的資料分割選項。 允許的值為:[無] (預設值)、[資料表的實體分割] 及 [動態範圍]。 啟用分割選項後 (即不是 [無]),從 Azure Synapse Analytics 並行載入資料的平行程度,將由複製活動的 [平行複製] 設定所控制。
無:選擇此設定不要使用分割。
資料表實體分割:如果想要使用實體分割區,請選擇此設定。 分割資料行和機制將根據實體資料表定義自動決定。
動態範圍:如果想要使用動態範圍分割,請選擇此設定。 使用已啟用平行的查詢時,需要定界分割參數 (
?DfDynamicRangePartitionCondition)。 範例查詢:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。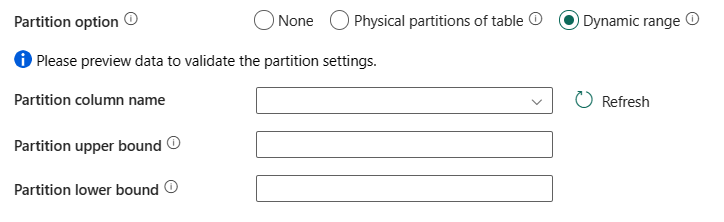
- 分割資料行名稱:以整數類型或日期/日期時間類型 (
int、smallint、bigint、date、smalldatetime、datetime、datetime2或datetimeoffset) 指定來源資料行的名稱,供平行複製的定界分割使用。 如果未指定,則會自動偵測資料表的索引或主索引鍵作為分割資料行。 - 分割上限:分割區範圍分割的分割資料行最大值。 這個值用於決定分割區的跨距,而不是用於篩選資料表中的資料列。 資料表或查詢結果中的所有資料列都會進行分割和複製。
- 分割下限:分割區範圍分割的分割資料行最小值。 這個值用於決定分割區的跨距,而不是用於篩選資料表中的資料列。 資料表或查詢結果中的所有資料列都會進行分割和複製。
- 分割資料行名稱:以整數類型或日期/日期時間類型 (
其他資料行:新增其他資料行來儲存來源檔案的相對路徑或靜態值。 後者支援運算式。 如需詳細資訊,請參閱<在複製期間新增其他資料行>。
Destination
對於 Azure Synapse Analytics,複製活動的 [目的地] 索引標籤中支援下列屬性。
![螢幕擷取畫面,其中顯示 [目的地] 索引標籤。](media/connector-azure-synapse-analytics/destination.png)
以下是必要的屬性:
- 資料存放區類型:選取 [外部]。
- 連線:從連線清單中選取 Azure Synapse Analytics 連線。 如果不存在連線,請選取 [新增],來建立新的 Azure Synapse Analytics 連線。
- 連線類型:選取 [Azure Synapse Analytics]。
- 資料表選項:可以選擇 [使用現有的]、[自動建立資料表]。 下列清單描述每個設定的組態:
- 使用現有的:從下拉式清單中選取資料庫中的資料表。 或勾選 [編輯] 以手動輸入結構描述和資料表名稱。
- 自動建立資料表:自動在來源結構描述中建立資料表 (如果不存在)。
在 [進階] 下,可以指定下列欄位:
複製方法:選擇想要用來複製資料的方法。 可以選擇 [複製命令]、[PolyBase]、[大量插入] 或 [Upsert]。 下列清單描述每個設定的組態:
複製命令:使用 COPY 陳述式將資料從 Azure 儲存體載入 Azure Synapse Analytics 或 SQL 集區。
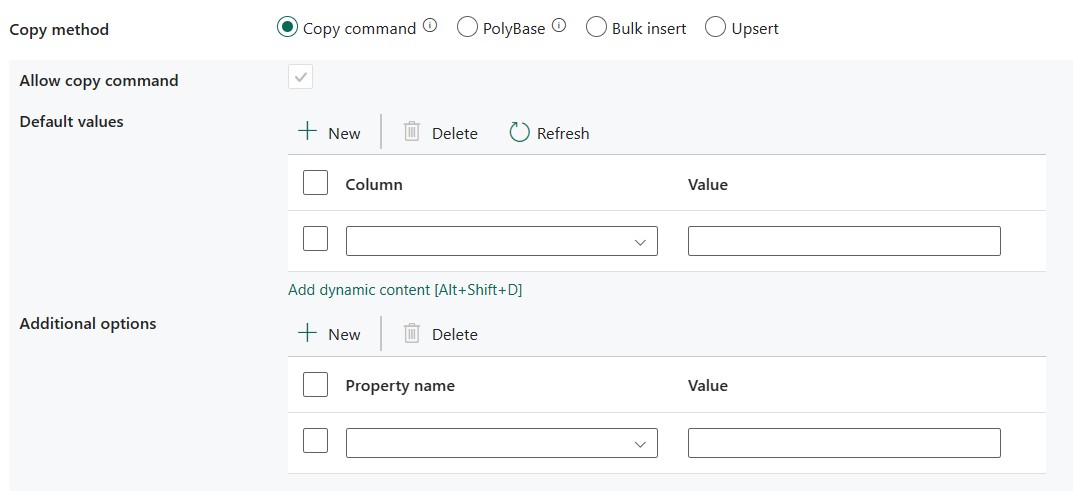
- 允許複製命令:選擇 [複製命令] 時,必須選取此選項。
- 預設值:指定 Azure Synapse Analytics 中每個目標資料行的預設值。 屬性中的預設值會覆寫資料倉儲中設定的預設條件約束,而且識別欄位不可有預設值。
- 其他選項:其他選項,將在 COPY 陳述式的 "With" 子句中直接傳遞至 Azure Synapse Analytics COPY 陳述式。 視需要將值加上引號,以配合 COPY 陳述式需求。
PolyBase:PolyBase 是高輸送量機制。 使用它將大量資料載入 Azure Synapse Analytics 或 SQL 集區。
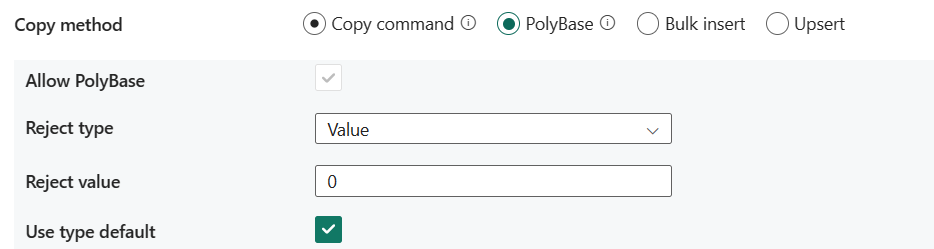
- 允許 PolyBase:選擇 [PolyBase] 時,必須選取此選項。
- 拒絕類型:指定 rejectValue 選項為常值還是百分比。 允許的值為值 (預設值) 和百分比。
- 拒絕值:指定在查詢失敗前可以拒絕的資料列數目或百分比。 在 CREATE EXTERNAL TABLE (Transact-SQL)的<引數>一節中,深入瞭解 PolyBase 的拒絕選項。 允許的值為 0 (預設值)、1、2 等其他值。
- 拒絕範例值:決定在 PolyBase 重新計算已拒絕的資料列百分比之前,所要擷取的資料列數目。 允許的值為 1、2 等。如果選擇 [百分比] 作為拒絕類型,則此屬性為必需。
- 使用類型預設:指定當 PolyBase 從文字檔擷取資料時,如何處理分隔符號文字檔中遺漏的值。 從 CREATE EXTERNAL FILE FORMAT (Transact-SQL) 的<引數>一節深入了解這個屬性。 允許的值為選取 (預設值) 或不選取。
大量插入:使用 [大量插入] 將資料大量插入目的地。

- 大量插入資料表鎖定:在資料表上進行大量插入作業期間,使用此選項可改善資料表上的複製效能,且沒有來自多個用戶端的索引。 若要深入了解,請參閱<BULK INSERT (Transact-SQL)>(機器翻譯)。
Upsert:想要將資料向上插入目的地時,指定寫入行為的設定群組。
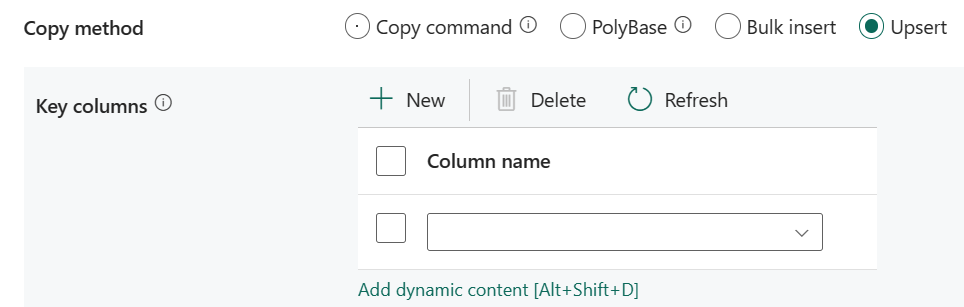
索引鍵資料行:選擇將使用哪一個資料行來決定來源的資料列是否符合目的地的資料列。
大量插入資料表鎖定:在資料表上進行大量插入作業期間,使用此選項可改善資料表上的複製效能,且沒有來自多個用戶端的索引。 若要深入了解,請參閱<BULK INSERT (Transact-SQL)>(機器翻譯)。
複製前指令碼:指定一個複製活動的指令碼,會在每次執行中將資料寫入到目的地資料表前執行此指令碼。 您可以使用此屬性來清除預先載入的資料。
寫入批次逾時:在逾時前等待批次插入作業完成的時間。允許的值為時間範圍。 預設值為 "00:30:00" (30 分鐘)。
寫入批次大小:指定每個批次要插入 SQL 資料表的資料列數目。 允許的值為整數 (資料列數目)。 根據預設,服務會依據資料列大小動態決定適當的批次大小。
並行連線數上限:指定在活動執行期間,與資料存放區建立的並行連線數上限。 僅在想要限制並行連線時,才需要指定值。
停用效能計量分析:此設定可用於收集如 DTU、DWU、RU 等計量,以進行複製效能最佳化並提出建議。 如果擔心此行為,請選取此複選框。 預設情況下,不會選取此選項。
使用 COPY 命令直接複製
Azure Synapse Analytics COPY 命令直接支援 Azure Blob 儲存體和 Azure Data Lake Storage Gen2 作為來源資料存放區。 如果來源資料符合本節所述準則,即可使用 COPY 命令從來源資料存放區直接複製到 Azure Synapse Analytics。
來源資料和格式包含下列類型和驗證方法:
支援的來源資料存放區類型 支援的格式 支援的來源驗證類型 Azure Blob 儲存體 分隔符號文字
Parquet匿名驗證
帳戶金鑰驗證
共用存取簽章驗證Azure Data Lake Storage Gen2 \(部分機器翻譯\) 分隔符號文字
Parquet帳戶金鑰驗證
共用存取簽章驗證可以設定下列 [格式] 設定:
- 對於 Parquet:[壓縮類型] 可以是 [無]、[Snappy] 或 [gzip]。
- 對於 DelimitedText:
- 資料列分隔符號:透過 COPY 命令直接將分隔文字複製到 Azure Synapse Analytics 時,明確指定資料列分隔符號 (\r; \n; 或 \r\n)。 只有當來源檔案的資料列分隔符號是 \r\n 時,預設值 (\r; \n; 或 \r\n) 才有效。 否則,請為案例啟用暫存。
- [Null 值] 會保留為預設值,或設定為空字串 ("")。
- [編碼] 會保留為預設值,或設定為 [UTF-8] 或 [UTF-16]。
- [略過行數] 會保留為預設值,或設定為 0。
- [壓縮類型] 可以是 [無] 或 [gzip]。
如果來源是資料夾,則必須選取 [遞迴] 核取方塊。
未指定 [依上次修改時間篩選]、[前置詞]、[啟用分割探索] 和 [其他資料行] 中的 [開始時間 (UTC)] 和 [結束時間 (UTC)]。
若要了解如何使用 COPY 命令將資料內嵌至 Azure Synapse Analytics,請參閱此文章。
如果來源資料存放區與格式原本就不受 COPY 命令支援,則可以透過 COPY 命令功能,使用分段複製。 這會自動將資料轉換成 COPY 命令相容的格式,然後呼叫 COPY 命令,將資料載入 Azure Synapse Analytics。
對應
對於 [對應] 索引標籤組態,如果未套用 Azure Synapse Analytics,並將自動建立資料表作為目的地,請參閱<對應>。
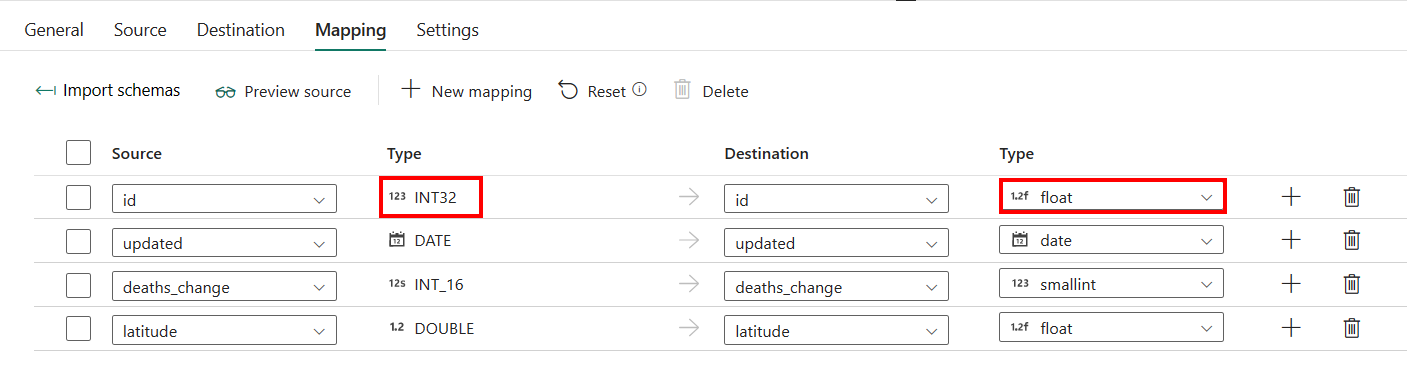
如果套用 Azure Synapse Analytics,並將自動建立資料表作為目的地,但 [對應] 中的組態除外,則可以編輯目的地資料行的類型。 選取 [匯入結構描述] 之後,可以在目的地中指定資料行類型。
例如,來源中 [識別碼] 資料行的類型為 int,而對應至目的地資料行時,可以將其變更為 float 類型。
設定
對於 [設定] 索引標籤組態,請參閱<在 [設定] 索引標籤下進行其他設定>。
從 Azure Synapse Analytics 平行複製
複製活動中 Azure Synapse Analytics 連接器提供內建的資料分割,以平行複製資料。 您可以在複製活動的 [來源] 索引標籤上找到資料分割選項。
當您啟用分割複本時,複製活動會平行查詢 Azure Synapse Analytics 來源,以依分割區來載入資料。 平行程度由 [複製活動設定] 索引標籤中的 [複製平行處理原則的程度] 設定所控制。例如,如果將 [複製平行處理原則的程度] 設定為四,服務會根據指定的分割選項和設定同時產生和執行四個查詢,而每個查詢都會從 Azure Synapse Analytics 擷取部分資料。
建議您啟用平行複製與資料分割,特別是從 Azure Synapse Analytics 資料庫載入大量資料時。 以下針對各種情節的建議設定。 將資料複製到以檔案為基礎的資料存放區時,建議分成多個檔案來寫入資料夾 (僅指定資料夾名稱),這樣效能會比寫入單一檔案更好。
| 案例 | 建議的設定 |
|---|---|
| 使用實體分割區從大型資料表完整載入。 | 分割選項:資料表的實體分割區。 在執行期間,服務會自動偵測實體分割區,並依分割區複製資料。 若要檢查您的資料表是否有實體分割區,您可以參考此查詢。 |
| 從大型資料表完整載入,不含實體分割區,同時在資料分割時包含整數或日期時間資料行。 | 分割選項:動態範圍分割。 分割資料行 (選用):指定用來分割資料的資料行。 如果未指定,則會使用索引或主索引鍵資料行。 分割區上限和分割區下限 (選用):指定是否要決定分割區跨距。 這不適用於篩選資料表中的資料列,資料表中的所有資料列都會分割並複製。 如果未指定,複製活動會自動偵測值。 例如,如果您的分割區資料行「識別碼」具有範圍 1 到 100 之間的值,而您將下限設定為 20、上限設定為 80,且平行複製為 4,則服務會分別依 4 個分割區擷取資料 - 範圍中的識別碼分別為 <=20、[21, 50]、[51, 80] 和 >=81。 |
| 使用自訂查詢載入大量資料,不使用實體分割區,同時包含整數或日期/日期時間資料行用於資料分割。 | 分割選項:動態範圍分割。 查詢: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分割資料行:指定用來分割資料的資料行。 分割區上限和分割區下限 (選用):指定是否要決定分割區跨距。 這不適用於篩選資料表中的資料列,查詢結果中的所有資料列都會分割並複製。 如果未指定,複製活動會自動偵測該值。 例如,如果您的分割區資料行「識別碼」具有範圍 1 到 100 之間的值,而您將下限設定為 20、上限設定為 80,且平行複製為 4,則服務會分別依 4 個分割區擷取資料 - 範圍中的識別碼分別為 <=20、[21, 50]、[51, 80] 和 >=81。 以下是不同案例的更多範例查詢: • 查詢整個資料表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 在具有資料行選取範圍和其他 WHERE 子句篩選條件的資料表中查詢: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 使用子查詢進行查詢: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 在子查詢中使用分割區進行查詢: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分割區選項載入資料的最佳做法:
- 選擇獨特的資料行作為分割資料行 (例如主索引鍵或唯一索引鍵) 以避免資料扭曲。
- 如果資料表有內建分割區,請使用分割選項 [資料表的實體分割],以獲得更佳的效能。
- Azure Synapse Analytics 一次最多可以執行 32 個查詢,將 [複製平行處理原則的程度] 設定過大可能會導致 Synapse 節流問題。
用來檢查實體分割區的範例查詢
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果資料表具有實體分割區,您會看到 "HasPartition" 為 "yes"。
資料表摘要
下列資料表包含有關 Azure Synapse Analytics 中複製活動的詳細資訊。
來源
| 名稱 | 描述: | 值 | 必要 | JSON 指令碼屬性 |
|---|---|---|---|---|
| 資料存放區類型 | 資料存放區類型。 | 外部 | 必要 | / |
| [連接] | 與來源資料存放區的連線。 | <您的連線> | 必要 | connection |
| 連線類型 | 您的來源連線類型。 | Azure Synapse Analytics | 必要 | / |
| 使用查詢 | 讀取資料的方式。 | • 資料表 • 查詢 • 預存程序 |
必要 | • typeProperties (在 typeProperties ->source 下)- 結構描述 - 資料表 • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters - 名稱 - 值 |
| 查詢逾時 | 查詢命令執行的逾時,預設值為 120 分鐘。 | 時間範圍 | 不必要 | queryTimeout |
| 隔離等級 | SQL 來源的異動鎖定行為。 | • 無 • 讀取認可 • 讀取未認可 • 可重複讀取 • 可序列化 • 快照 |
不必要 | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • 可序列化 • 快照 |
| 分割選項 | 用來從 Azure SQL 資料庫載入資料的資料分割選項。 | • 無 • 資料表實體分割 • 動態範圍 - 分割資料行名稱 - 分割上限 - 分割下限 |
不必要 | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partitionSettings: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| 其他資料行 | 新增其他資料行來儲存來源檔案的相對路徑或靜態值。 後者支援運算式。 | • 名稱 • 值 |
不必要 | additionalColumns: • 名稱 • 值 |
Destination
| 名稱 | 描述: | 值 | 必要 | JSON 指令碼屬性 |
|---|---|---|---|---|
| 資料存放區類型 | 資料存放區類型。 | 外部 | 必要 | / |
| [連接] | 與目的地資料存放區的連線。 | <您的連線> | 必要 | connection |
| 連線類型 | 您的目的地連線類型。 | Azure Synapse Analytics | 必要 | / |
| 資料表選項 | 您的目的地資料表選項。 | • 使用現有的 • 自動建立資料表 |
必要 | • typeProperties (在 typeProperties ->sink 下)- 結構描述 - 資料表 • tableOption: - autoCreate typeProperties (在 typeProperties ->sink 下)- 結構描述 - 資料表 |
| 複製方法 | 用來複製資料的方法。 | • 複製命令 • PolyBase • 大量插入 • Upsert |
不必要 | / |
| 選取 [複製] 命令時 | 使用 COPY 陳述式將資料從 Azure 儲存體載入 Azure Synapse Analytics 或 SQL 集區。 | / | 否。 使用 COPY 時適用。 |
allowCopyCommand:true copyCommandSettings |
| 預設值 | 指定 Azure Synapse Analytics 中每個目標資料行的預設值。 屬性中的預設值會覆寫資料倉儲中設定的預設條件約束,而且識別欄位不可有預設值。 | <預設值> | 不必要 | defaultValues: - columnName - defaultValue |
| 其他選項 | 在 COPY 陳述式的 "With" 子句中將直接傳遞至 Azure Synapse Analytics COPY 陳述式的其他選項。 視需要將值加上引號,以配合 COPY 陳述式需求。 | <其他選項> | 不必要 | additionalOptions: - <屬性名稱>:<值> |
| 選取 [PolyBase] 時 | PolyBase 是高輸送量機制。 使用它將大量資料載入 Azure Synapse Analytics 或 SQL 集區。 | / | 否。 使用 PolyBase 時套用。 |
allowPolyBase:true polyBaseSettings |
| 拒絕類型 | 拒絕值的類型。 | • 值 • 百分比 |
不必要 | rejectType: - 值 - 百分比 |
| 拒絕值 | 指定在查詢失敗前可以拒絕的資料列數目或百分比。 | 0 (預設值)、1、2 等。 | 不必要 | rejectValue |
| 拒絕範例值 | 決定在 PolyBase 重新計算已拒絕的資料列百分比之前,所要擷取的資料列數目。 | 1、2 等 | 將 [百分比] 指定為拒絕類型時,則是 | rejectSampleValue |
| 使用類型預設 | 指定當 PolyBase 從文字檔擷取資料時,如何處理分隔符號文字檔中遺漏的值。 若要了解有關此屬性的詳細資料,請參閱 CREATE EXTERNAL FILE FORMAT (Transact-SQL) 的<引數>一節。 | 已選取 (預設值) 或未選取。 | 不必要 | useTypeDefault: true (預設值) 或 false |
| 選取 [大量插入] 時 | 將資料大量插入目的地。 | / | 不必要 | writeBehavior:插入 |
| 大量插入資料表鎖定 | 在資料表上進行大量插入作業期間,使用此選項可改善資料表上的複製效能,且沒有來自多個用戶端的索引。 若要深入了解,請參閱<BULK INSERT (Transact-SQL)>(機器翻譯)。 | 已選取或未選取 (預設值) | 不必要 | sqlWriterUseTableLock: true 或 false (預設值) |
| 選取 [Upsert] 時 | 想要將資料向上插入目的地時,指定寫入行為的設定群組。 | / | 不必要 | writeBehavior:Upsert |
| 索引鍵資料行 | 選擇將使用哪一個資料行來決定來源的資料列是否符合目的地的資料列。 | <資料行名稱> | 不必要 | upsertSettings: - 索引鍵:<資料行名稱> - interimSchemaName |
| 大量插入資料表鎖定 | 在資料表上進行大量插入作業期間,使用此選項可改善資料表上的複製效能,且沒有來自多個用戶端的索引。 若要深入了解,請參閱<BULK INSERT (Transact-SQL)>(機器翻譯)。 | 已選取或未選取 (預設值) | 不必要 | sqlWriterUseTableLock: true 或 false (預設值) |
| 複製前指令碼 | 一個複製活動的指令碼,會在每次執行中將資料寫入到目的地資料表前執行此指令碼。 您可以使用此屬性來清除預先載入的資料。 | <複製前指令碼> (字串) |
不必要 | preCopyScript |
| 寫入批次逾時 | 在逾時前等待批次插入作業完成的時間。允許的值為時間範圍。 預設值為 "00:30:00" (30 分鐘)。 | 時間範圍 | 不必要 | writeBatchTimeout |
| 寫入批次大小 | 每個批次要插入 SQL 資料表中的資料列數。 根據預設,服務會依據資料列大小動態決定適當的批次大小。 | <資料列數目> (整數) |
不必要 | writeBatchSize |
| 並行連線數上限 | 在活動執行期間建立至資料存放區的同時連線上限。 僅在想要限制並行連線時,才需要指定值。 | <並行連線數上限> (整數) |
不必要 | maxConcurrentConnections |
| 停用效能計量分析 | 此設定可用於收集如 DTU、DWU、RU 等計量,以進行複製效能最佳化並提出建議。 如果擔心此行為,請選取此複選框。 | 選取或不選取 (預設值) | 不必要 | disableMetricsCollection: true 或 false (預設值) |