瞭解 Microsoft Fabric 的倉儲中的 Delta Lake 記錄
適用於✅:Microsoft Fabric 的倉儲
Microsoft Fabric 中的倉儲以開放式檔格式建置。 用戶資料表會以 parquet 檔案格式儲存,並針對所有使用者資料表發佈 Delta Lake 記錄。
Delta Lake 記錄會針對任何可讀取 Delta Lake 資料表的引擎,開啟倉儲使用者資料表的直接存取權。 此存取限制為唯讀,以確保使用者資料維持 ACID 交易合規性。 對資料表中資料的所有插入、更新和刪除都必須透過倉儲執行。 提交交易之後,系統會起始系統幕後程序,以發佈受影響資料表的更新 Delta Lake 記錄。
如何取得 OneLake 路徑
下列步驟詳細說明如何從倉儲中的資料表取得 OneLake 路徑:
在 Microsoft Fabric 工作區中開啟 [倉儲]。
在 物件總管 中,您可以在 [數據表] 資料夾中的選取資料表上找到更多選項(...)。 選取 [屬性] 功能表。
![螢幕擷取畫面顯示在選取的資料表上查找 [屬性] 選項的位置。](media/query-delta-lake-logs/select-properties.png)
選取時,[屬性] 窗格會顯示下列資訊:
- 名稱
- 格式
- 類型
- URL
- 相對路徑
- ABFS 路徑
![[屬性] 窗格的螢幕擷取畫面。](media/query-delta-lake-logs/properties-details.png)
![[屬性] 窗格的螢幕擷取畫面。](media/query-delta-lake-logs/properties-details.png#lightbox)
如何取得 Delta Lake 記錄路徑
您可以透過下列方法來尋找 Delta Lake 記錄:
Delta Lake 記錄可透過在 Lakehouse 中建立的捷徑來查詢。 您可以在 Microsoft Fabric 入口網站中使用 Microsoft Fabric Spark Notebook 或 Fabric 資料工程師 中的 Lakehouse 總管來檢視檔案。
Delta Lake 記錄可透過 Azure 儲存體總管、透過 Power BI Direct Lake 模式等 Spark 連線,或使用任何其他可讀取差異資料表的服務來找到。
Delta Lake 記錄可透過 Windows 中的 OneLake 總管,在每個資料表的
_delta_log資料夾中找到,如下列螢幕擷取畫面所示。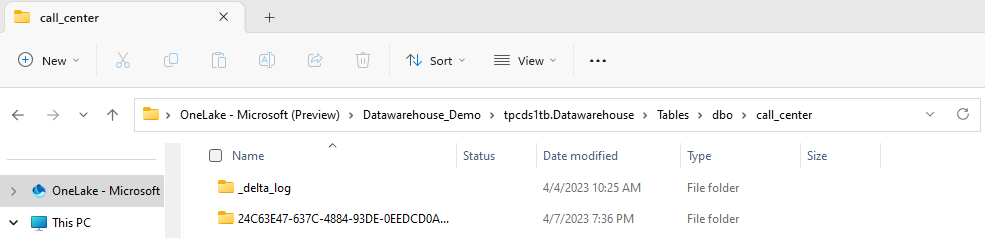

暫停 Delta Lake 記錄發佈
您可以視需要暫停和繼續發佈 Delta Lake 記錄。 發佈暫停後,讀取倉儲外部資料表的 Microsoft Fabric 引擎會看到暫停操作之前的資料。 它可確保報表保持穩定且一致,從而反映在對資料表進行任何變更之前所存在的所有資料表的資料。 資料更新完成後,您可以繼續發佈 Delta Lake 日誌,讓其他分析引擎能夠看到所有最近的資料變更。 暫停 Delta Lake 記錄發佈的另一個使用案例是,使用者不需要與 Microsoft Fabric 中其他計算引擎的互操作性,因為這有助於節省計算成本。
暫停和繼續 Delta Lake 記錄發佈的語法如下:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = PAUSED | AUTO
範例:暫停和繼續 Delta Lake 記錄發佈
若要暫停 Delta Lake 記錄發佈,請使用下列程式碼片段:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = PAUSED
從其他 Microsoft Fabric 引擎對目前倉儲中的倉儲資料表進行查詢(例如,來自 Lakehouse 的查詢),現在會顯示在暫停 Delta Lake 記錄發佈之前的資料版本。 倉儲查詢仍會顯示最新版本的資料。
若要繼續 Delta Lake 記錄發佈,請使用下列程式碼片段:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = AUTO
當狀態變更回 AUTO 時,Fabric 倉儲引擎會發佈對倉儲中資料表所做的所有最近變更的記錄,讓 Microsoft Fabric 中的其他分析引擎可以讀取最新版本的資料。
檢查 Delta Lake 記錄發佈的狀態
若要檢查目前工作區所有倉儲上 Delta Lake 記錄發佈的目前狀態,請使用下列程式碼片段:
SELECT [name], [DATA_LAKE_LOG_PUBLISHING_DESC] FROM sys.databases
限制
- 只有當資料表名稱只包含下列字元時,才能供 Spark 和其他系統使用:A-Z a-z 0-9 和底線。
- Spark 和其他系統使用的資料行名稱不能包含:
- 空格
- 索引標籤
- 歸位字元
- [
- ,
- ;
- {
- }
- (
- )
- =
- ]