特性雜湊
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
使用 Vowpal Wabbit 程式庫將文字資料轉換為整數編碼的功能
類別:文字分析
模組概觀
本文說明如何使用 機器學習 Studio 中的功能雜湊模組 (傳統) ,將英文文字串流轉換成一組以整數表示的功能。 然後,您可以將此雜湊功能集傳遞至機器學習演算法,以定型文字分析模型。
本課程模組中提供的功能雜湊功能是以 Vowpal Wabbit 架構為基礎。 如需詳細資訊,請參閱 定型 Vowpal Wabbit 7-4 模型 或定型 Vowpal Wabbit 7-10 模型。
深入瞭解功能雜湊
特徵雜湊的運作方式是將唯一的權杖轉換為整數。 它會以您提供做為輸入的確切字串作業,且不會執行任何語言分析或預先處理。
例如,以一組這樣的簡單句子為例,後面接著情感分數。 假設您想要使用此文字來建置模型。
| USERTEXT | SENTIMENT |
|---|---|
| I loved this book | 3 |
| I hated this book | 1 |
| This book was great | 3 |
| I love books | 2 |
在內部, 功能雜湊 模組會建立 n-gram 的字典。 例如,此資料集的雙字母組清單看起來如下:
| TERM (bigrams) | 頻率 |
|---|---|
| This book | 3 |
| I loved | 1 |
| I hated | 1 |
| I love | 1 |
您可以使用 N 字母組屬性來控制 N 字母組的大小。 如果您選擇雙字母組,則也會計算單字母組。 因此,字典也會包含單一詞彙,如下所示:
| 詞彙 (單字母組) | 頻率 |
|---|---|
| 預訂 | 3 |
| I | 3 |
| 書籍 | 1 |
| was | 1 |
建置字典之後, 功能雜湊 模組會將字典詞彙轉換成雜湊值,並計算每個案例中是否使用功能。 針對每個文字資料列,模組會輸出一組資料行,每個雜湊功能各有一個資料行。
例如,在雜湊之後,特徵資料行看起來可能像這樣:
| 分級 | 雜湊特徵 1 | 雜湊特徵 2 | 雜湊特徵 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- 如果資料行中的值為 0,資料列未包含雜湊功能。
- 如果值為 1,資料列就確實包含該特徵。
使用特徵雜湊的優點是,您可以將可變長度的文字檔表示為相等長度的數值特徵向量,並達到維度縮減。 相反地,如果您嘗試依原樣使用文字資料行進行定型,則會將其視為類別特徵資料行,且有許多不同的值。
輸出為數值也可以使用許多不同的機器學習方法來處理資料,包括分類、叢集化或資訊擷取。 因為查閱作業可以使用整數雜湊,而不是字串比較,所以取得特徵加權的速度也會快得多。
如何設定功能雜湊
在 Studio 中將 功能雜湊 模組新增至您的實驗, (傳統) 。
連接包含您所要分析文字的資料集。
針對 [目標資料行],選取您要轉換成雜湊功能的文字資料行。
資料行必須是字串資料類型,而且必須標示為 Feature 資料行。
如果您選擇多個文字資料行做為輸入,它可能會對特徵維度產生很大的影響。 例如,如果單一文字資料行使用 10 位雜湊,輸出就會包含 1024 個數據行。 如果兩個文字資料行使用 10 位雜湊,則輸出會包含 2048 個數據行。
注意
根據預設,Studio (傳統) 將大部分的文字資料行標示為功能,因此如果您選取所有文字資料行,可能會得到太多資料行,包括許多不是實際可用文字的資料行。 使用[編輯中繼資料] 中的[清除] 功能選項,以防止其他文字資料行雜湊。
使用 雜湊位大小 來指定建立雜湊表時要使用的位數。
預設的位元大小為 10。 對於許多問題,這個值是否足夠,但資料是否足夠,取決於定型文字中 n 元詞彙的大小。 使用大型詞彙時,可能需要更多空間以避免發生衝突。
我們建議您嘗試針對此參數使用不同的位數,並評估機器學習解決方案的效能。
針對 N-gram,輸入數位,以定義要新增至定型字典的 n-gram 長度上限。 N 字母組是一系列的 n 單字,被視為唯一的單元。
N-gram = 1:Unigram 或單字。
N-gram = 2:Bigrams 或雙字序列,加上 unigram。
N-gram = 3:Trigrams 或三字序列,加上 bigrams 和 unigram。
執行實驗。
結果
處理完成後,模組會輸出轉換的資料集,其中原始文字資料行已轉換成多個資料行,每個資料行都代表文字中的功能。 根據字典的大小而定,產生的資料集可能非常大:
| 資料行名稱 1 | 資料行類型 2 |
|---|---|
| USERTEXT | 原始資料行 |
| SENTIMENT | 原始資料行 |
| USERTEXT - 雜湊特徵 1 | 雜湊的特徵資料行 |
| USERTEXT - 雜湊特徵 2 | 雜湊的特徵資料行 |
| USERTEXT - 雜湊特徵 n | 雜湊的特徵資料行 |
| USERTEXT - 雜湊特徵 1024 | 雜湊的特徵資料行 |
建立已轉換的資料集之後,您可以使用它做為 定型模型 模組的輸入,以及良好的分類模型,例如 雙類別支援向量機器。
最佳作法
下圖示范在模型化文字資料時可以使用的一些最佳做法
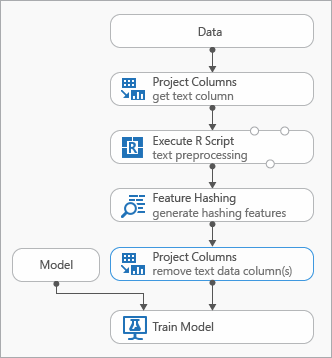
在使用「特徵雜湊」之前,您可能需要先加入「執行 R 指令碼」模型,以進行輸入文字的前置處理。 透過 R 腳本,您也可以彈性地使用自訂詞彙或自訂轉換。
您應該在功能雜湊模組之後新增選取資料集中的資料行模組,以從輸出資料集中移除文字資料行。 產生雜湊功能之後,您不需要文字資料行。
或者,您可以使用 [編輯中繼資料 ] 模組,從文字資料行清除功能屬性。
也請考慮使用這些文字前置處理選項來簡化結果並改善精確度:
- 斷詞
- 停用字詞移除
- 大小寫正規化
- 移除標點符號和特殊字元
- 堵塞。
在任何個別解決方案中套用的最佳前置處理方法集合取決於領域、詞彙和商務需求。 建議您試驗您的資料,以查看哪些自訂文字處理方法最有效。
範例
如需如何使用功能雜湊進行文字分析的範例,請參閱 Azure AI 資源庫:
技術說明
本節包含實作詳細資料、提示和常見問題集的解答。
提示
除了使用功能雜湊之外,您可能還想要使用其他方法來從文字擷取特徵。 例如:
- 使用 預處理器文字 模組來移除拼字錯誤之類的成品,或簡化文字準備進行雜湊處理。
- 使用 擷取關鍵字組 來使用自然語言處理來擷取片語。
- 使用 具名實體辨識 來識別重要的實體。
機器學習 Studio (傳統) 提供文字分類範本,引導您使用功能雜湊模組進行功能擷取。
實作詳細資料
功能雜湊模組會使用名為 Vowpal Wabbit 的快速機器學習架構,以將特徵字雜湊至記憶體內部索引,並使用名為murmurhash3的熱門開放原始碼雜湊函式。 此雜湊函數是一種非加密雜湊演算法,可將文字輸入對應至整數,由於在金鑰隨機分配中表現良好,深受歡迎。 不同于密碼編譯雜湊函式,攻擊者可以輕鬆地反轉它,使其不適合密碼編譯用途。
雜湊的目的是將可變長度的文字文件轉換成等長的數值特徵向量,以支援維度縮減並加速查閱特徵權數。
每個雜湊功能代表一或多個 n-gram 文字功能, (unigram 或個別單字、bi-gram、tri-gram 等) ,視以 k) 表示的 (位數和指定為參數的 n-gram 數目而定。 它會使用 (32 位 (32 位) 的演算法,將功能名稱投影到電腦架構未簽署字組,然後以 2^k) -1 (2^k) -1 進行 AND 處理。 也就是說,雜湊值會向下投影到前 k 個較低順序位,而其餘位則會零出。如果指定的位數目是 14,雜湊表可以保存 214-1 (或 16,383) 專案。
對於許多問題,預設雜湊表 (bitsize = 10) 還足夠;不過,根據定型文字中 n-gram 詞彙的大小,可能需要更多空間以避免衝突。 建議您嘗試針對 雜湊位大小 參數使用不同的位數,並評估機器學習解決方案的效能。
預期的輸入
| 名稱 | 類型 | 描述 |
|---|---|---|
| 資料集 | 資料表 | 輸入資料集 |
模組參數
| 名稱 | 範圍 | 類型 | 預設 | 描述 |
|---|---|---|---|---|
| 目標資料行 | 任意 | ColumnSelection | StringFeature | 選擇要套用雜湊的資料行。 |
| 雜湊位元大小 | [1;31] | 整數 | 10 | 輸入對選取的資料行進行雜湊處理時要使用的位元數 |
| N 字母組 | [0;10] | 整數 | 2 | 指定雜湊期間產生的 N-gram 數目。 預設會同時擷取單字母組和雙字母組 |
輸出
| 名稱 | 類型 | 描述 |
|---|---|---|
| 已轉換的資料集 | 資料表 | 含雜湊資料行的輸出資料集 |
例外狀況
| 例外狀況 | 描述 |
|---|---|
| 錯誤 0001 | 如果找不到資料集的一或多個指定的資料行,就會發生例外狀況。 |
| 錯誤 0003 | 如果一或多個輸入為 Null 或空白,就會發生例外狀況。 |
| 錯誤 0004 | 如果參數小於或等於特定值,就會發生例外狀況。 |
| 錯誤 0017 | 如果一或多個指定的資料行具有目前模組不支援的類型,就會發生例外狀況。 |
如需 Studio (傳統) 模組特有的錯誤清單,請參閱錯誤碼機器學習。
如需 API 例外狀況的清單,請參閱機器學習 REST API 錯誤碼。