在 Spark 歷程記錄伺服器中的 SQL Server 巨量資料叢集上,對 Spark 應用程式進行偵錯和診斷
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本文提供指引,說明如何使用延伸的 Spark 歷程記錄伺服器來偵測並診斷 SQL Server 巨量資料叢集中的 Spark 應用程式。 這些偵錯和診斷功能內建於 Spark 歷程記錄伺服器中,並由 Microsoft 提供技術支援。 延伸模組包含 [資料] 索引標籤、[圖表] 索引標籤和 [診斷] 索引標籤。在 [資料] 索引標籤中,使用者可以檢查 Spark 作業的輸入和輸出資料。 在 [圖表] 索引標籤中,使用者可以檢查資料流程,並重新執行作業圖表。 在 [診斷] 索引標籤中,使用者可以參考資料扭曲、時間扭曲和執行程式使用狀況分析。
取得 Spark 歷程記錄伺服器的存取權
來自開放原始碼的 Spark 歷程記錄伺服器使用者體驗已透過資訊加以增強,其中包括作業特定資料以及作業圖表的互動式視覺效果,以及適用於巨量資料叢集的資料流程。
依 URL 開啟 Spark 歷程記錄伺服器 Web UI
藉由瀏覽至下列 URL 來開啟 Spark 歷程記錄伺服器,並將 <Ipaddress> 和 <Port> 取代為巨量資料叢集特定資訊。 在 SQL Server 2019 CU 5 之前所部署的叢集上,具有基本驗證 (使用者名稱/密碼) 巨量資料叢集安裝程式,當提示登入閘道 (Knox) 端點時,您必須提供使用者根。 請參閱部署 SQL Server 巨量資料叢集。 從 SQL Server 2019 (15.x) CU 5 開始,當您使用基本驗證部署新的叢集時,所有端點 (包括閘道) 都會使用 AZDATA_USERNAME 和 AZDATA_PASSWORD。 升級至 CU 5 的叢集上的端點會繼續使用 root 作為使用者名稱,以連線至閘道端點。 這項變更不適用於使用 Active Directory 驗證的部署。 請參閱版本資訊中的透過閘道端點存取服務的認證。
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
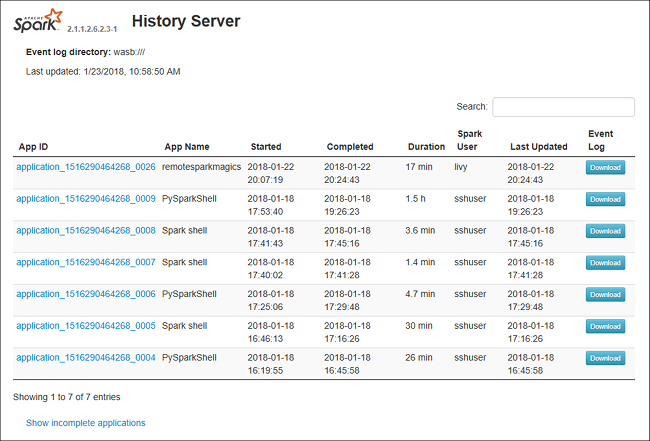
Spark 歷程記錄伺服器 Web UI 如下所示:
Spark 歷程記錄伺服器中的 [資料] 索引標籤
選取 [作業識別碼],然後按一下工具功能表上的 [資料] 以取得資料檢視。
個別選取索引標籤,以檢查 [輸入]、[輸出] 和 [資料表作業]。
![Spark 歷程記錄伺服器 [資料] 索引標籤](media/apache-azure-spark-history-server/sparkui-data-tabs.png?view=sql-server-linux-ver15)
按一下 [複製] 按鈕來複製所有資料列。
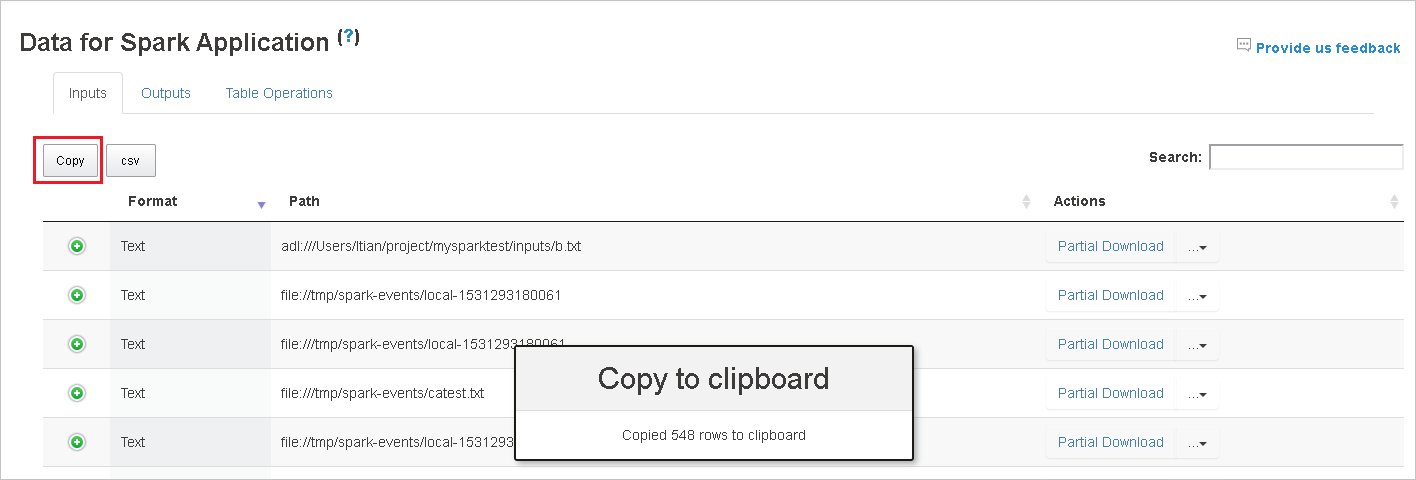
按一下 [csv] 按鈕,將所有資料儲存為 CSV 檔案。
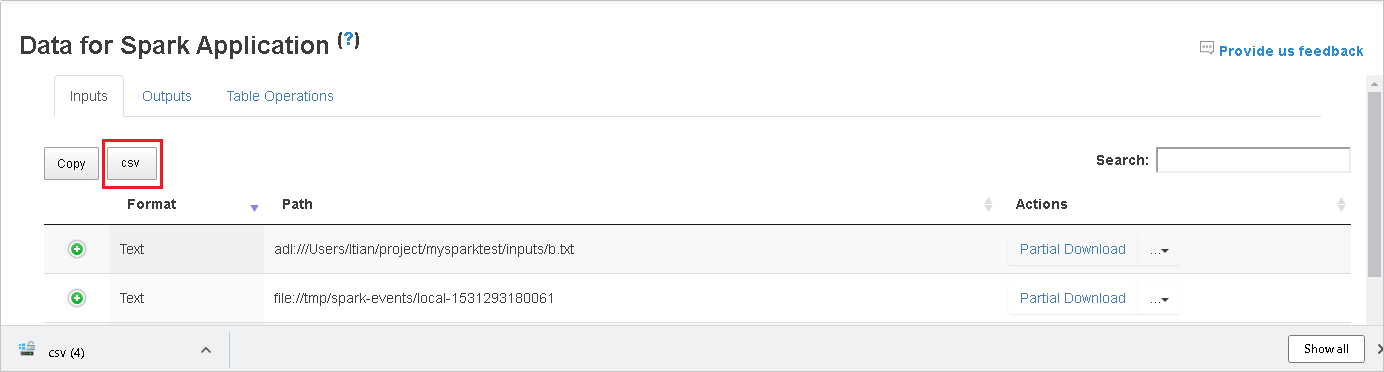
在 [搜尋] 欄位中輸入關鍵字來進行搜尋,搜尋結果會立即顯示。
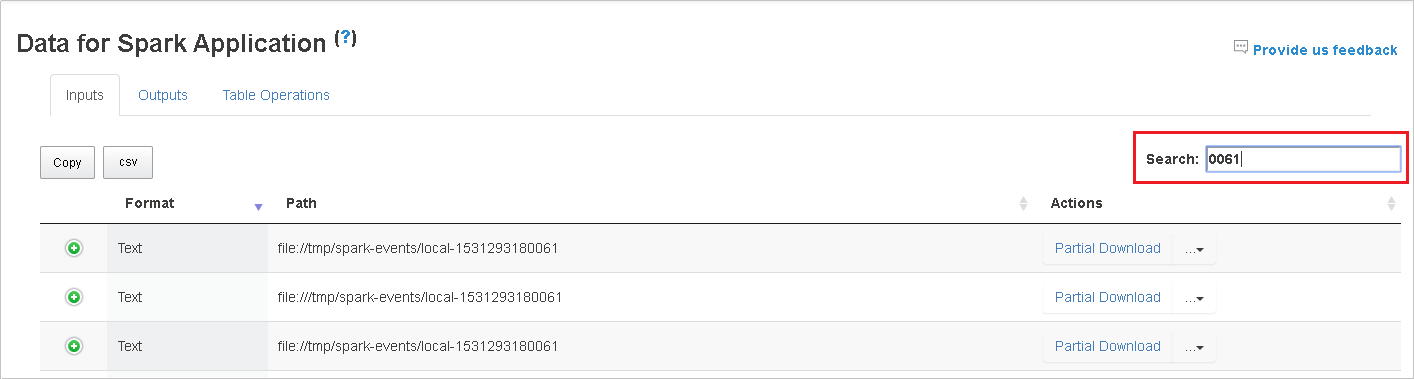
按一下資料行標頭來排序資料表,按一下加號展開資料列以顯示更多詳細資料,或按一下減號來摺疊列。
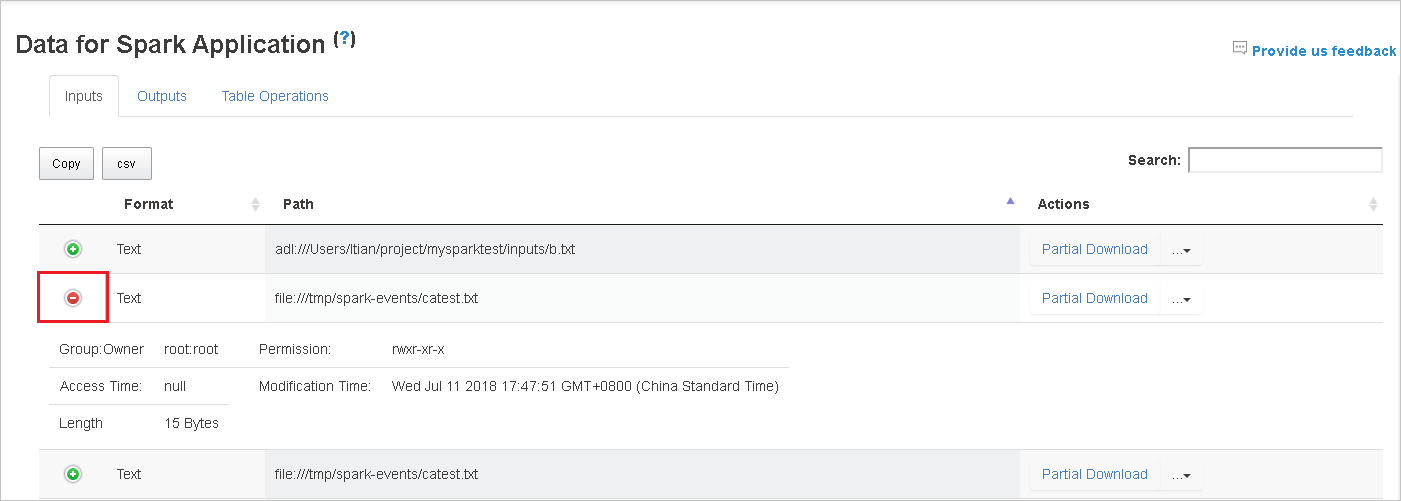
若要下載單一檔案,請按一下右邊的 [部分下載] 按鈕,然後將選取的檔案下載到本機位置。 如果檔案不存在,則會開啟新的索引標籤來顯示錯誤訊息。
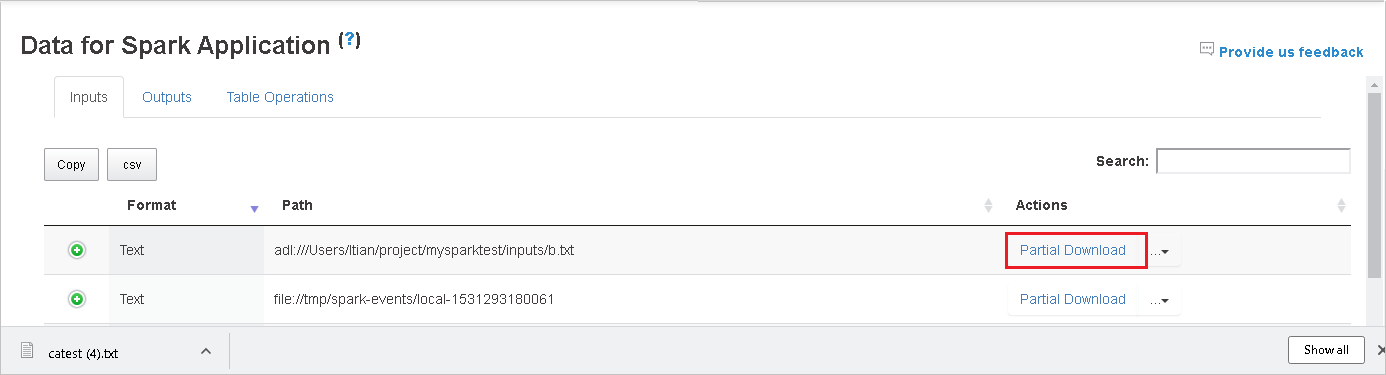
複製完整路徑或相對路徑,方法是選取從下載功能表展開的 [複製完整路徑]、[複製相對路徑]。 針對 Azure 資料湖儲存體檔案,[在 Azure 儲存體總管中開啟] 將會啟動 Azure 儲存體總管。 並在登入時找出正確的資料夾。
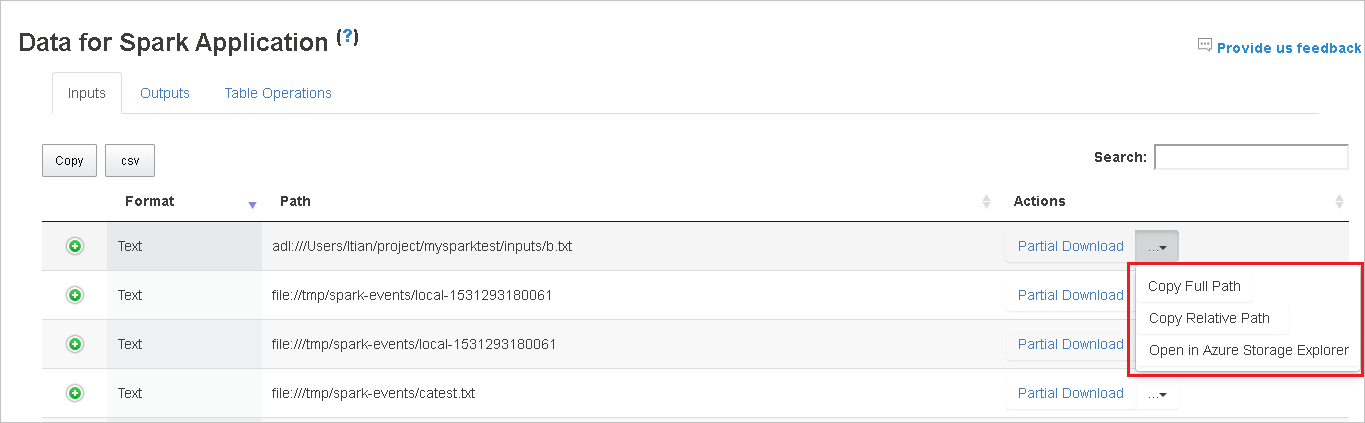
當在一個頁面中顯示太多資料列時,請按一下資料表下方的數字以瀏覽頁面。

將滑鼠停留在 [資料] 旁的問號以顯示工具提示,或按一下問號以取得詳細資訊。
按一下 [提供意見反應] 以傳送有關問題的意見反應。
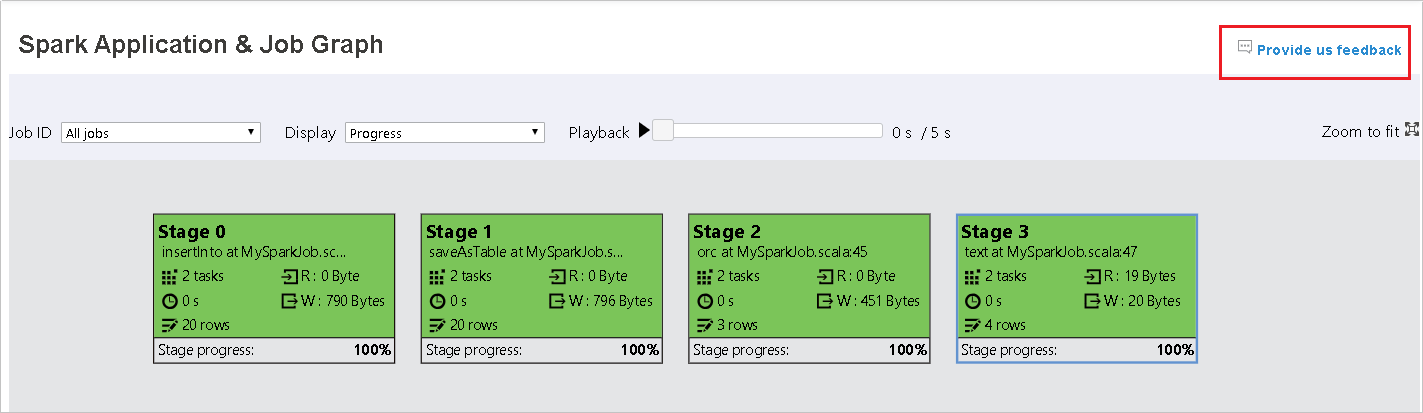
Spark 歷程記錄伺服器中的 [圖表] 索引標籤
選取作業識別碼,然後按一下工具功能表上的 [圖表] 以取得作業圖表檢視。
透過產生的作業圖表檢查作業概觀。
根據預設,它會顯示所有作業,而且可以依 [作業識別碼] 進行篩選。
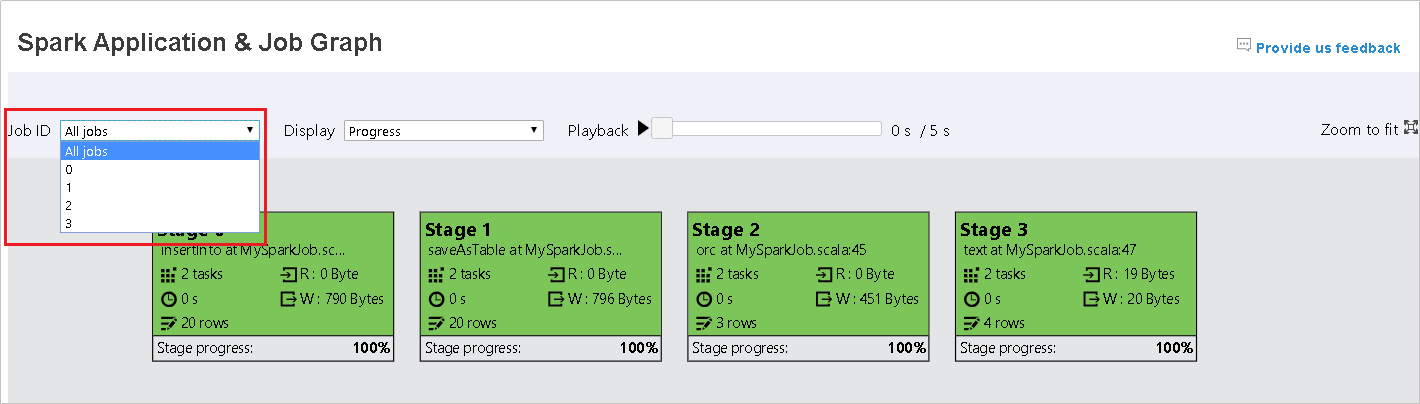
我們將 [進度] 保留為預設值。 使用者可以在 [顯示] 的下拉式清單中選取 [讀取] 或 [寫入] 來檢查資料流程。
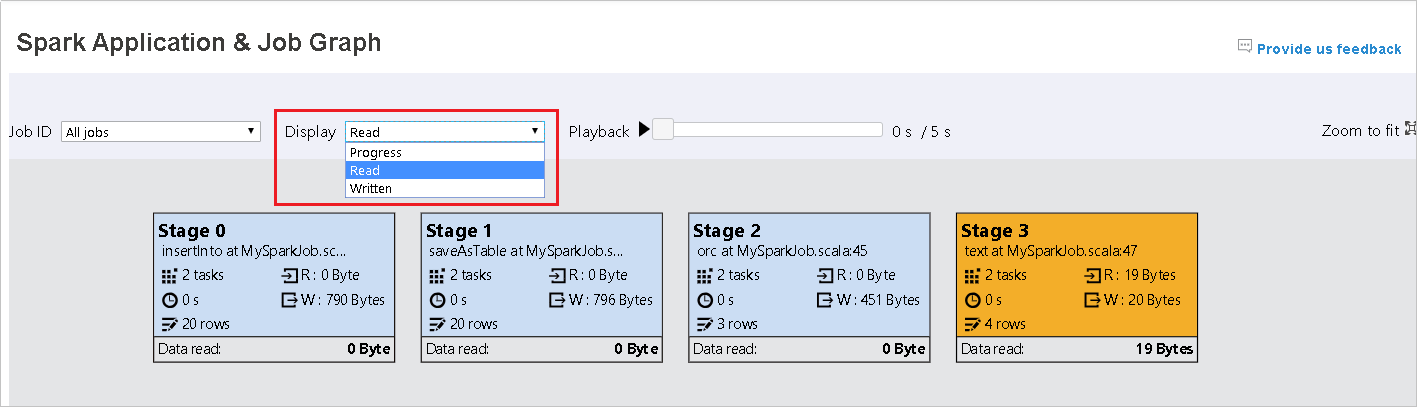
圖表節點會以顯示熱度圖的色彩顯示。

按一下 [播放] 按鈕來播放作業,並按一下 [停止] 按鈕隨時停止。 播放時,工作會以色彩顯示以顯示不同的狀態:
- 綠色表示成功:作業已成功完成。
- 橘色表示重試:失敗但不會影響作業最終結果的工作執行個體。 這些工作具有稍後可能會成功的重複或重試執行個體。
- 藍色表示執行中:工作正在執行。
- 白色表示正在等候或略過:工作正在等候執行,或已略過該階段。
- 紅色表示失敗:工作失敗。

略過的階段會以白色顯示。


注意
允許播放每個工作。 針對不完整的作業,不支援播放。
滑鼠會滾動以放大/縮小作業圖表,或按一下 [縮放至適當比例],使其符合螢幕大小。
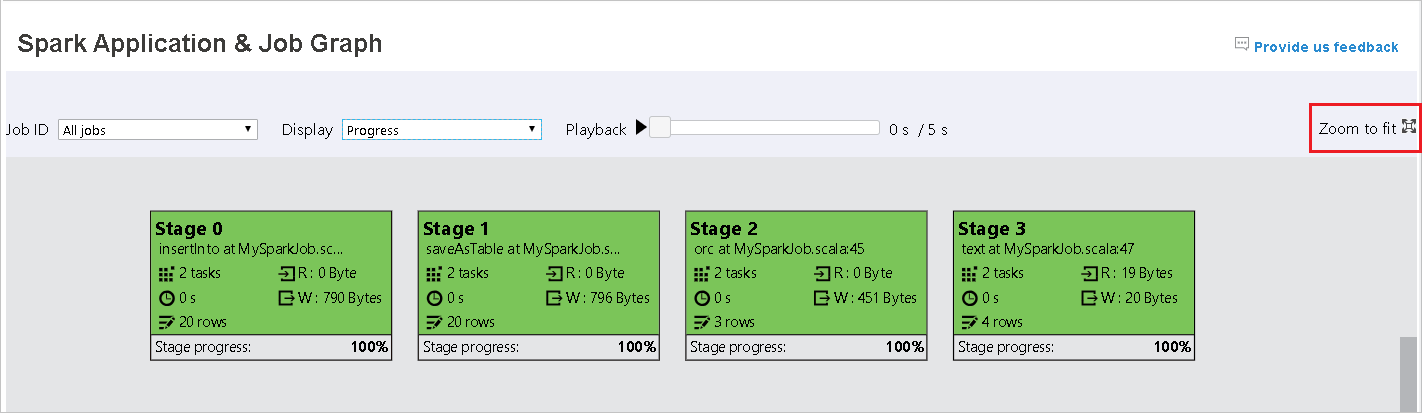
當工作失敗時,將滑鼠停留在圖表節點上以查看工具提示,然後按一下 [階段] 以開啟 [階段] 頁面。
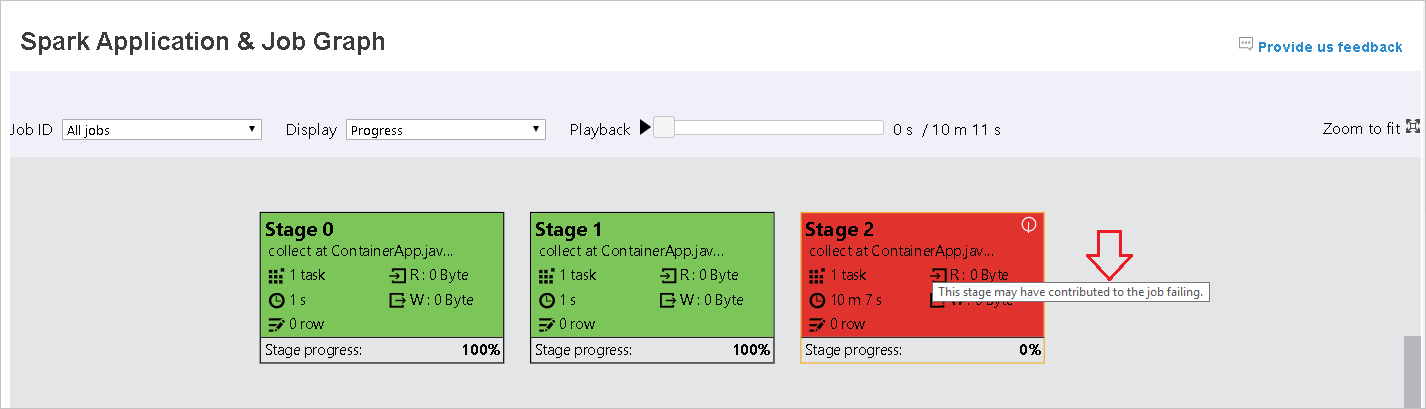
在 [作業圖表] 索引標籤中,如果階段的工作符合下列條件,則會顯示工具提示和小型圖示:
- 資料扭曲:資料讀取大小 > 此階段中所有工作的平均資料讀取大小 * 2 且資料讀取大小 > 10 MB
- 時間扭曲:此階段中所有工作的執行時間 > 平均執行時間 * 2,且執行時間 > 2 分鐘
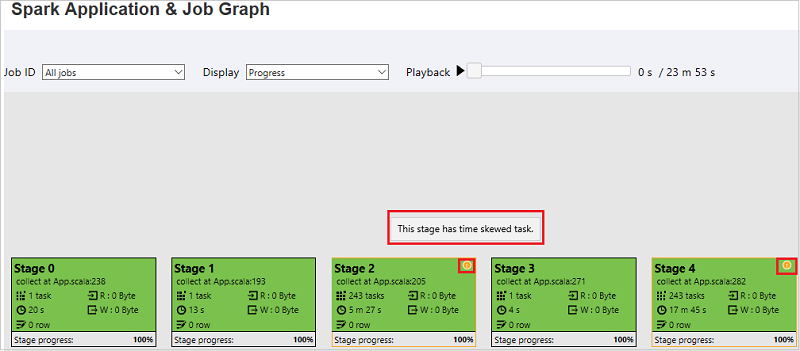
[作業圖表] 節點會顯示每個階段的下列資訊:
- 識別碼。
- 名稱或描述。
- 總工作數。
- 讀取的資料:輸入大小和隨機讀取大小的總和。
- 資料寫入:輸出大小和隨機寫入大小的總和。
- 執行時間:第一次嘗試的開始時間與最後一次嘗試的完成時間之間的時間。
- 資料列計數:輸入記錄、輸出記錄、隨機讀取記錄和隨機寫入記錄的總和。
- 進度。
注意
根據預設,[作業圖表] 節點會顯示每個階段的最後一次嘗試的資訊 (階段執行時間除外),但在播放圖表節點期間,會顯示每次嘗試的資訊。
注意
對於讀取和寫入的資料大小,我們使用 1MB = 1000 KB = 1000 * 1000 個位元組。
按一下 [提供意見反應] 以傳送有關問題的意見反應。
Spark 歷程記錄伺服器中的 [診斷] 索引標籤
選取作業識別碼,然後按一下工具功能表上的 [診斷] 以取得作業診斷檢視。 [診斷] 索引標籤包括 [資料扭曲]、[時間扭曲] 和 [執行程式使用狀況分析]。
透過個別選取索引標籤,檢查 [資料扭曲]、[時間扭曲] 和 [執行程式使用狀況分析]。
![[診斷] 索引標籤](media/apache-azure-spark-history-server/sparkui-diagnosis-tabs.png?view=sql-server-linux-ver15)
資料扭曲
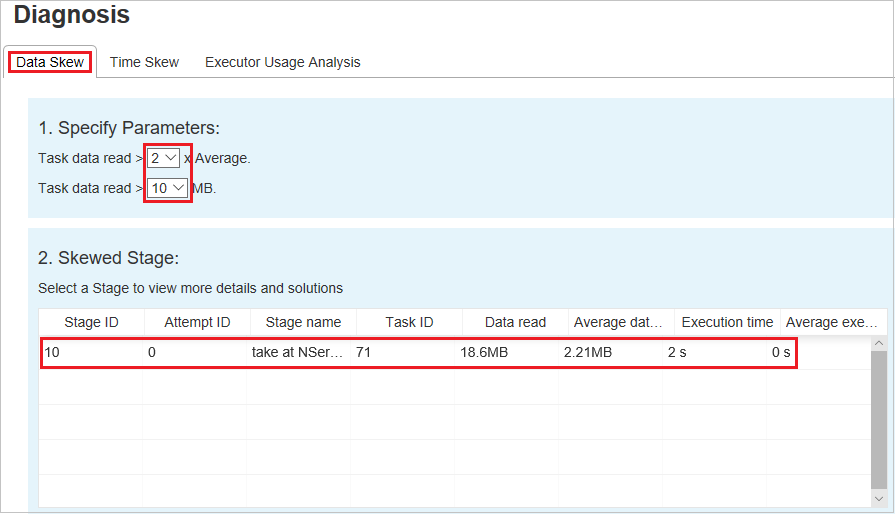
按一下[資料扭曲] 索引標籤,就會根據指定的參數顯示對應的扭曲工作。
指定參數 -第一個區段會顯示用來偵測資料扭曲的參數。 內建規則是:工作資料讀取大於平均工作資料讀取的 3 倍,而工作資料讀取超過 10 MB。 如果您想要為扭曲的工作定義自己的規則,您可以選擇您的參數 ([扭曲階段]),[扭曲字元] 區段將會據此重新整理。
扭曲階段 -第二個區段會顯示階段,其中有扭曲的工作符合上面指定的準則。 如果某個階段中有一個以上的扭曲工作,扭曲階段資料表只會顯示最扭曲的工作 (例如,資料扭曲的最大資料)。
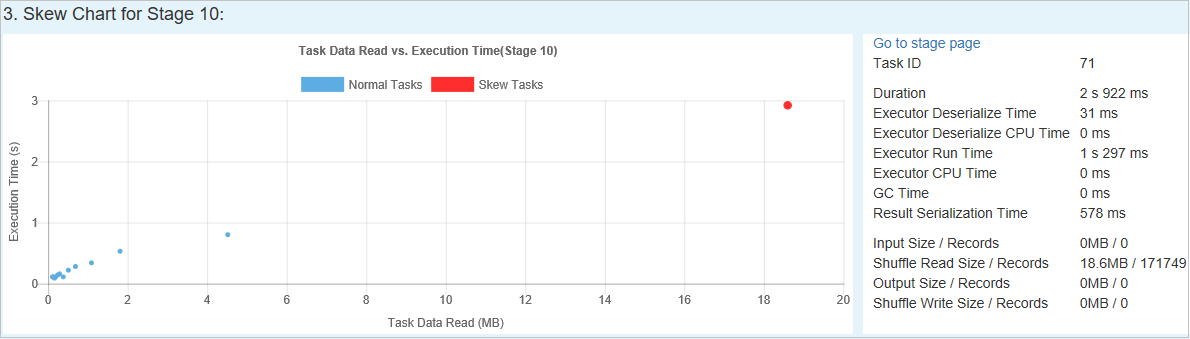
扭曲圖表 - 選取扭曲階段資料表中的資料列時,扭曲圖表會根據讀取和執行時間的資料,顯示更多工作分佈詳細資料。 扭曲的工作會以紅色標示,而一般工作則會以藍色標示。 基於效能考量,圖表最多只會顯示 100 個樣本工作。 工作詳細資料會顯示在右下方面板中。
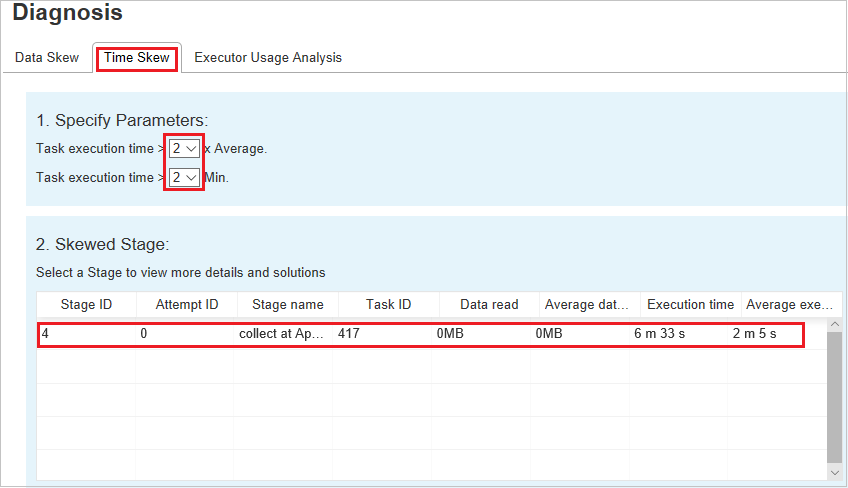
時間扭曲
[時間扭曲] 索引標籤會根據工作執行時間顯示扭曲的工作。
指定參數 - 第一個區段會顯示用來偵測時間扭曲的參數。 偵測時間扭曲的預設準則是:工作執行時間大於平均執行時間的三倍,而工作執行時間大於 30 秒。 您可以根據您的需求變更參數。 [扭曲階段] 和 [扭曲圖表] 會顯示對應的階段和工作資訊,就像上面的 [資料扭曲] 索引標籤一樣。
按一下 [時間扭曲],然後根據 [指定參數] 區段中所設定的參數,在 [扭曲階段] 區段中顯示篩選的結果。 按一下 [扭曲階段] 區段中的一個專案,然後對應的圖表會在 section3 中繪製,而且工作詳細資料會顯示在右下方面板中。
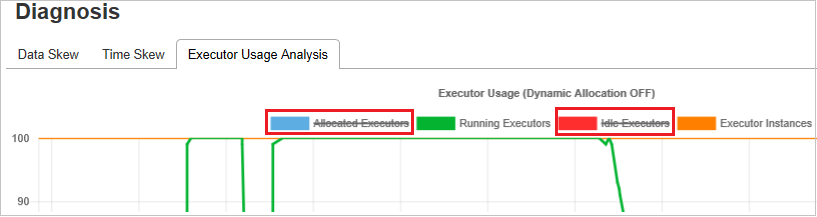
執行程式使用狀況分析
執行程式使用狀況圖表會將 Spark 作業的實際執行程式配置和執行狀態視覺化。
按一下 [執行程式使用狀況分析],然後繪製與執行程式使用方式相關的四種曲線類型。 其中包括 [已配置的執行程式]、[執行中的執行程式]、[閒置的執行程式] 以及 [最大執行程式執行個體]。 關於已配置的執行程式,每個「已新增執行程式」或「已移除執行程式」事件都會增加或減少配置的執行程式。 您可以檢查 [作業] 索引標籤中的 [事件時間軸] 以進行比較。
![[執行程式] 索引標籤](media/apache-azure-spark-history-server/sparkui-diagnosis-executors.png?view=sql-server-linux-ver15)
按一下色彩圖示,以選取或取消選取所有草稿中的對應內容。
Spark/Yarn 記錄
除了 Spark 記錄伺服器之外,您還可以分別在這裡找到 Spark 與 Yarn 的記錄:
- Spark 事件記錄檔:hdfs:///system/spark-events
- Yarn 記錄:hdfs:///tmp/logs/root/logs-tfile
注意:這兩個記錄都有 7 天的預設保留期限。 若想要變更保留期限,請參閱設定 Apache Spark 與 Apache Hadoop 頁面。 無法變更位置。
已知問題
Spark 歷程記錄伺服器具有下列已知問題:
目前,其僅適用於 Spark 3.1 叢集 (CU13+) 和 Spark 2.4 (CU12-)。
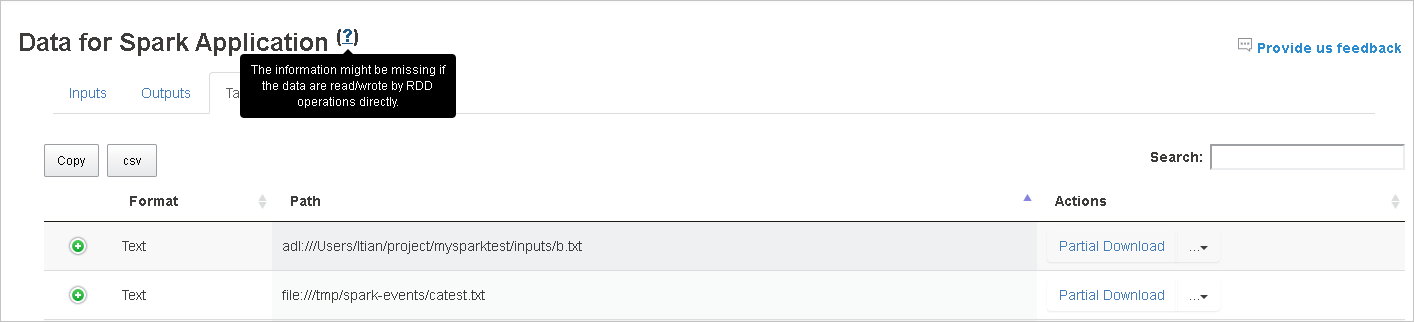
使用 RDD 的輸入/輸出資料不會顯示在 [資料] 索引標籤中。
後續步驟
- 開始使用 SQL Server 巨量資料叢集
- 設定 Spark 設定
- 設定 Spark 設定