在 Visual Studio Code 中於 SQL Server 巨量資料叢集上提交 Spark 作業
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
了解如何使用適用於 Visual Studio Code 的 Spark 與 Hive 工具來建立及提交適用於 Apache Spark 的 PySpark 指令碼。首先我們將會描述如何在 Visual Studio Code 中安裝 Spark 與 Hive 工具,然後便會逐步解說向 Spark 提交作業的方法。
您可以在 Visual Studio Code 所支援的平台上安裝 Spark 與 Hive 工具,這包括 Windows、Linux 及 macOS。 您可以在下面找到不同平台的先決條件。
必要條件
若要完成此文章中的步驟,將會需要下列項目:
- SQL Server 巨量資料叢集。 請參閱 SQL Server 巨量資料叢集。
- Visual Studio Code \(英文\)。
- Python 和 Visual Studio Code 上的 Python 延伸模組。
- Mono \(英文\)。 只有 Linux 和 macOS 才需要 Mono。
- 針對 Visual Studio Code 設定 PySpark 互動式環境 \(部分機器翻譯\)。
- 名為 SQLBDCexample 的本機目錄。 本文使用 C:\SQLBDC\SQLBDCexample。
安裝 Spark 與 Hive 工具
在您具備先決條件之後,便可以安裝適用於 Visual Studio Code 的 Spark 與 Hive 工具。 完成下列步驟來安裝 Spark 與 Hive 工具:
開啟 Visual Studio Code。
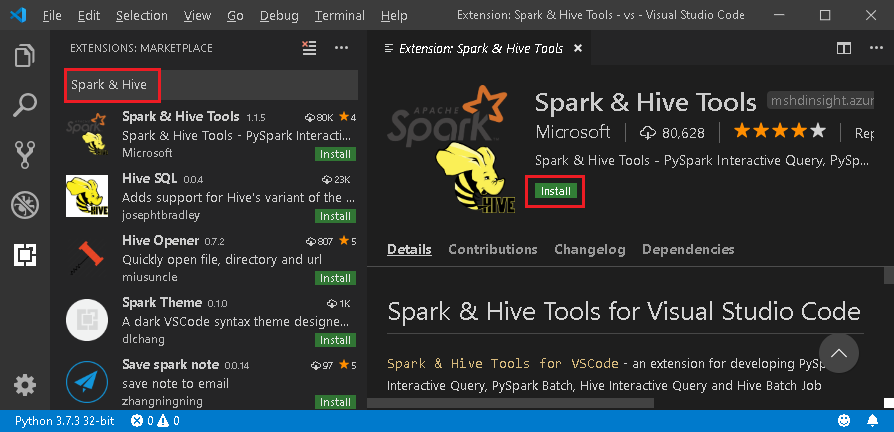
從功能表列,瀏覽至 [檢視]>[擴充功能]。
在搜尋方塊中,輸入 [Spark 與 Hive]。
從搜尋結果中選取 Microsoft 發佈的 [Spark 與 Hive 工具],然後選取 [安裝]。
視需要重新載入。
開啟工作資料夾
完成下列步驟來在 Visual Studio Code 中開啟工作資料夾並建立檔案:
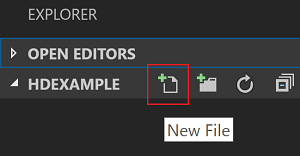
從功能表列,瀏覽至 [檔案]>[開啟資料夾]>C:\SQLBDC\SQLBDCexample,然後選取 [選取資料夾] 按鈕。 該資料夾會出現在左側的 [檔案總管] 檢視中。
從 [檔案總管] 檢視,依序選取 [SQLBDCexample] 資料夾,以及位於工作資料夾旁邊的新增檔案圖示。
以
.py(Spark 指令碼) 副檔名來為新檔案命名。 此範例會使用 HelloWorld.py。將下列程式碼複製並貼到該指令檔:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
連結 SQL Server 巨量資料叢集
在您可以從 Visual Studio Code 將指令碼提交至叢集之前,您必須連結 SQL Server 巨量資料叢集。
從功能表列,巡覽至 [檢視] > [命令選擇區...],然後輸入 Spark / Hive: Link a Cluster。

針對已連結的叢集類型選取 [SQL Server 巨量資料]。
輸入 SQL Server 巨量資料端點。
輸入 SQL Server 巨量資料叢集使用者名稱。
輸入使用者管理員的密碼。
設定巨量資料叢集的顯示名稱 (選用)。
列出叢集,檢閱 [輸出] 檢視以確認。
列出叢集
從功能表列,巡覽至 [檢視] > [命令選擇區...],然後輸入 Spark / Hive: List Cluster。
檢閱 [輸出] 檢視。 該檢視將會顯示已連結的叢集。

設定預設叢集
如果您已經將先前所建立的 SQLBDCexampl 資料夾關閉,請重新開啟該資料夾。
選取先前所建立的 HelloWorld.py 檔案,它將會在指令碼編輯器中開啟。
如果您尚未連結叢集,請先這麼做。
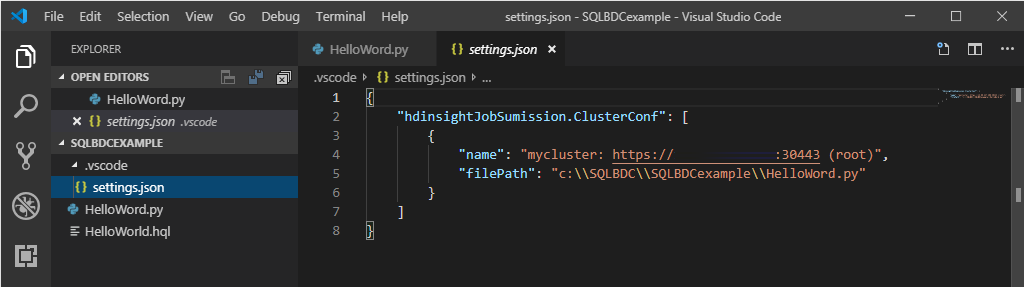
以滑鼠右鍵按一下指令碼編輯器,然後選取 [Spark / Hive: Set Default Cluster]。
選取某個叢集作為目前指令檔的預設叢集。 工具會自動更新設定檔 .VSCode\settings.json。
提交互動式 PySpark 查詢
您可以遵循下列步驟來提交互動式 PySpark 查詢:
如果您已經將先前所建立的 SQLBDCexampl 資料夾關閉,請重新開啟該資料夾。
選取先前所建立的 HelloWorld.py 檔案,它將會在指令碼編輯器中開啟。
如果您尚未連結叢集,請先這麼做。
選擇所有程式碼,然後以滑鼠右鍵按一下指令碼編輯器,選取 [Spark: PySpark Interactive] (或是使用捷徑 Ctrl + Alt + I) 來提交查詢。
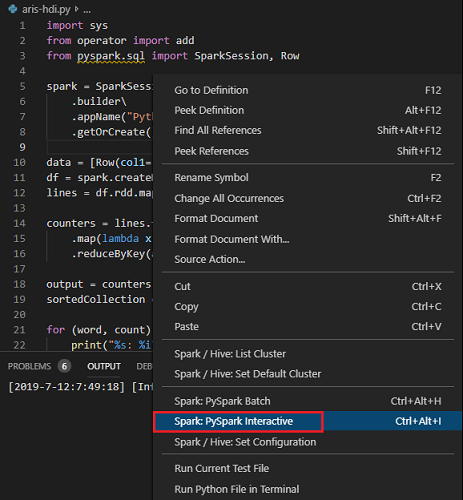
如果您尚未指定預設叢集,請選取叢集。 不久之後,Python Interactive 結果就會顯示在新索引標籤中。您還可以工具使用捷徑功能表提交一塊程式碼,而非整個指令檔。
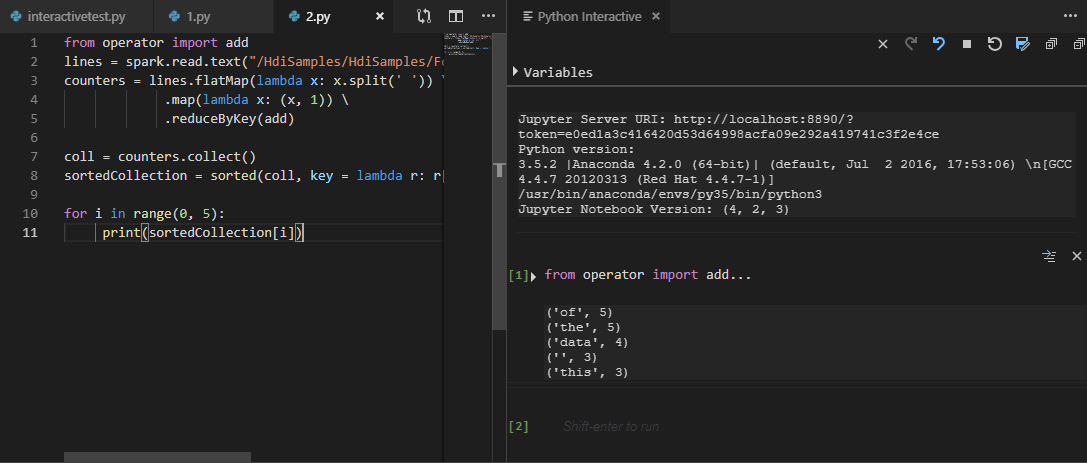
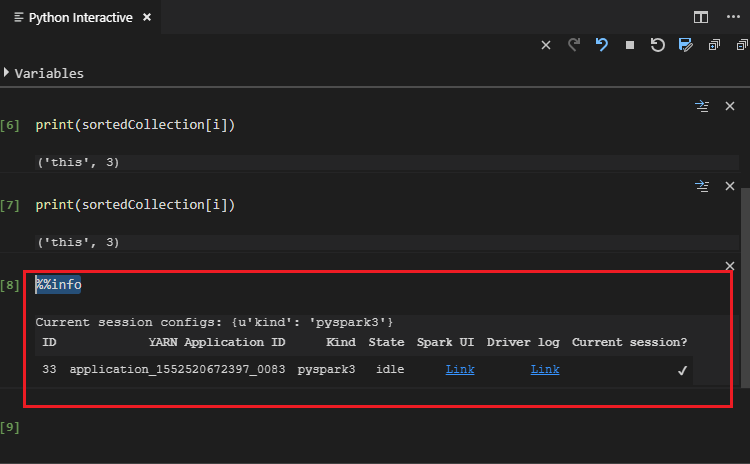
輸入 "%%info",然後按 Shift + Enter 以檢視作業資訊。 (選用)
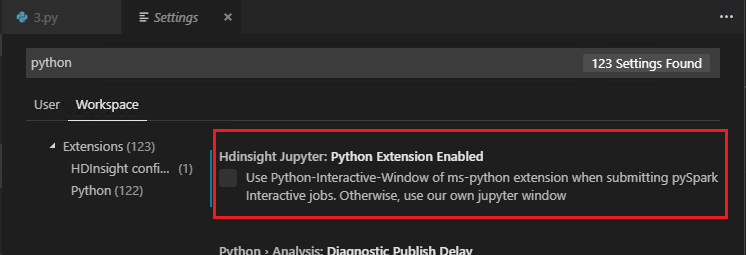
注意
在設定中取消選取 [已啟用 Python 擴充功能] (預設為選取) 時,已提交的 [PySpark 互動式] 結果將會使用舊的視窗。
提交 PySpark 批次工作
如果您已經將先前所建立的 SQLBDCexampl 資料夾關閉,請重新開啟該資料夾。
選取先前所建立的 HelloWorld.py 檔案,它將會在指令碼編輯器中開啟。
如果您尚未連結叢集,請先這麼做。
以滑鼠右鍵按一下指令碼編輯器,然後選取 [Spark: PySpark Batch],或是使用捷徑 Ctrl + Alt + H。
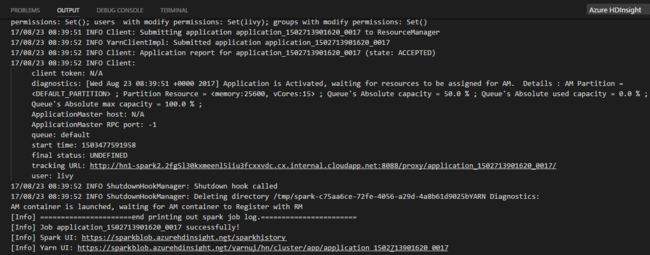
如果您尚未指定預設叢集,請選取叢集。 在您提交 Python 作業之後,提交記錄便會出現在 Visual Studio Code 的 [輸出] 視窗中。 同時也會顯示 Spark UI URL 和 Yarn UI URL。 您可以在網頁瀏覽器中開啟該 URL 來追蹤作業狀態。
Apache Livy 設定
支援 Apache Livy \(英文\) 設定,且可以在工作區資料夾中的 .VSCode\settings.json 設定它。 目前 Livy 設定僅支援 Python 指令碼。 如需詳細資料,請參閱 Livy 讀我檔案。
如何觸發 Livy 設定
方法 1
- 從功能表列,瀏覽至 [檔案]>[喜好設定]>[設定]。
- 在 [搜尋設定] 文字輸入框中,輸入 HDInsight Job Submission: Livy Conf。
- 選取 [在 settings.json 中編輯] 以取得相關的搜尋結果。
方法 2
提交檔案。請注意,系統會自動將 .vscode 資料夾加入工作資料夾。 您可以選取 .vscode 下的 settings.json 來找到 Livy 設定。
專案設定:
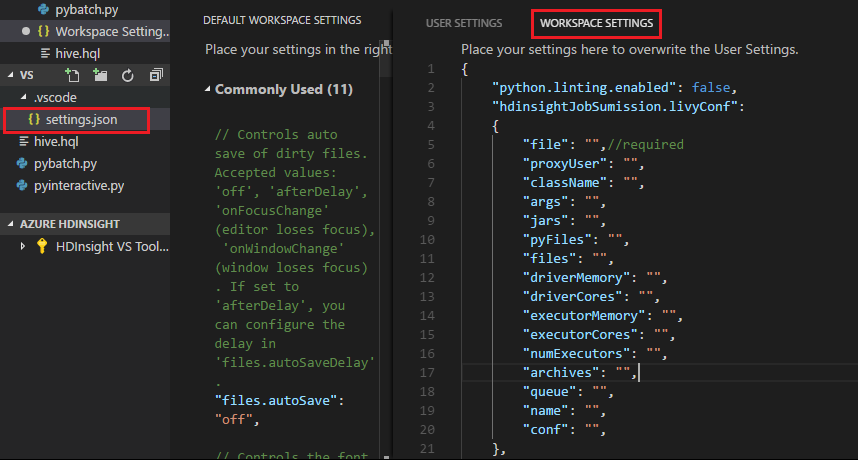
注意
針對 driverMemory 和 executorMemory 設定,請搭配單位設定值,例如 1g 或 1024m。
支援的 Livy 設定
POST /batches
要求本文
| 名稱 | description | 類型 |
|---|---|---|
| file | 包含要執行之應用程式的檔案 | 路徑 (必要) |
| proxyUser | 執行作業時要模擬的使用者 | 字串 |
| className | 應用程式 Java/Spark 主要類別 | 字串 |
| args | 適用於應用程式的命令列引數 | 字串清單 |
| jars | 要用於此工作階段的 jars | 字串清單 |
| pyFiles | 要用於此工作階段的 Python 檔案 | 字串清單 |
| files | 要用於此工作階段的檔案 | 字串清單 |
| driverMemory | 要用於驅動程式程序的記憶體數量 | 字串 |
| driverCores | 要用於驅動程式程序的核心數目 | int |
| executorMemory | 要用於每個執行程式程序的記憶體數量 | 字串 |
| executorCores | 要用於每個執行程式的核心數目 | int |
| numExecutors | 要針對此工作階段啟動的執行程式數目 | int |
| archives | 要用於此工作階段的封存 | 字串清單 |
| queue | 提交至的 YARN 佇列名稱 | 字串 |
| NAME | 此工作階段的名稱 | 字串 |
| conf | Spark 設定屬性 | key=val 的對應 |
| :- | :- | :- |
回應本文
建立的批次物件。
| 名稱 | description | 類型 |
|---|---|---|
| id | 工作階段識別碼 | int |
| appId | 此工作階段的應用程式識別碼 | String |
| appInfo | 詳細的應用程式資訊 | key=val 的對應 |
| log | 記錄行 | 字串清單 |
| state | 批次狀態 | 字串 |
| :- | :- | :- |
注意
提交指令碼時,已指派的 Livy 設定將會顯示在 [輸出] 窗格中。
其他功能
適用於 Visual Studio Code 的 Spark 與 Hive 支援下列功能:
IntelliSense 自動完成。 針對關鍵字、方法、變數等內容快顯建議。 不同的圖示代表不同類型的物件。
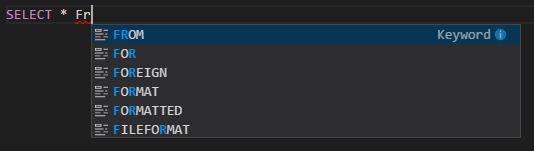
IntelliSense 錯誤標記。 語言服務會為 Hive 指令碼的編輯錯誤加上底線。
語法醒目提示。 語言服務會使用不同的色彩來區分變數、關鍵字、資料類型、函數等項目。
將叢集取消連結
從功能表列,巡覽至 [檢視] > [命令選擇區],然後輸入 Spark / Hive: Unlink a Cluster。
選取要取消連結的叢集。
檢閱 [輸出] 檢視以確認。
下一步
如需 SQL Server 巨量資料叢集和相關案例的詳細資訊,請參閱 SQL Server 巨量資料叢集。