開始使用數據行存放區索引以進行即時作業分析
適用於:![]() Microsoft Fabric 中的 SQL Server
Microsoft Fabric 中的 SQL Server![]() Azure SQL 資料庫
Azure SQL 資料庫![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體 ![]() SQL 資料庫
SQL 資料庫
SQL Server 2016 (13.x) 導入了即時作業分析,能夠同時在同一個資料庫資料表上執行分析和 OLTP 工作負載。 除了執行即時分析,您也可免除 ETL 和資料倉儲的需要。
說明的即時作業分析
傳統上,企業會有個別可用於作業 (也就是 OLTP) 和分析工作負載的系統。 在這類系統中,擷取、轉換和載入 (ETL) 工作會定期將資料從作業存放區移至分析存放區。 分析資料通常儲存於專門用來執行分析查詢的資料倉儲或資料超市中。 儘管此解決方案已是標準,但它仍有下列這三個主要挑戰︰
複雜度。 實作 ETL 需要相當多的編碼,特別是只載入修改的資料列。 要找出哪些資料列已修改是相當複雜的。
成本。 實作 ETL 需要購買額外硬體和軟體授權的成本。
資料延遲。 實作 ETL 會新增用以執行分析的時間延遲。 例如,如果 ETL 工作是在每個營業日結束時執行,分析查詢將針對至少是前一天的資料執行。 對許多企業來說,這個延遲是無法接受的,因為企業倚賴即時分析資料。 例如,詐騙偵測需要針對作業資料進行即時分析。
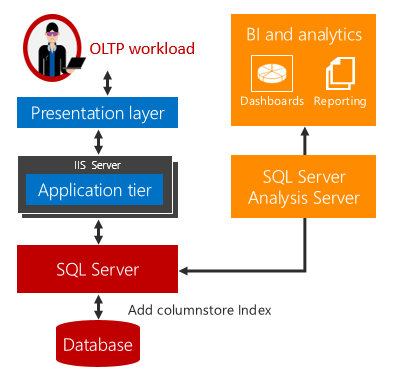
即時作業分析提供這些挑戰的解決方案。
當分析和 OLTP 工作負載在相同的基礎資料表上執行時,不會有任何時間延遲。 針對可使用即時分析的案例,可藉由免除 ETL 的需要以及購買和維護個別資料倉儲的需要,大幅降低成本和複雜度。
注意
即時作業分析的目標是單一資料來源的案例,例如企業資源規劃 (ERP) 應用程式,您可以在其上執行作業和分析工作負載。 當您需要在執行分析工作負載之前整合多個來源的資料時,或當您需要使用預先彙總的資料 (例如 Cube) 進行極端分析效能時,這不會取代個別資料倉儲的需要。
即時分析會在資料列存放區資料表上使用可更新的資料行存放區索引。 資料行存放區索引會維護資料複本,因此 OLTP 和分析工作負載會針對資料的個別複本執行。 這樣可將同時執行這兩個工作負載的效能影響降到最低。 SQL Server 會自動維護索引變更,讓 OLTP 變更一律保持最新狀態以供分析使用。 透過此設計,就能實際針對最新的資料執行即時分析。 這適用於以磁碟為基礎的資料表和記憶體最佳化的資料表。
開始使用範例
開始進行即時分析︰
識別作業結構描述中的資料表,其中包含分析所需的資料。
針對每個資料表,卸除所有 B 型樹狀結構索引,其主要是設計來在您的 OLTP 工作負載上加速現有的分析。 使用單一資料行存放區索引來取代它們。 這可提升 OLTP 工作負載的整體效能,因為要維護的索引較少。
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;記憶體內部資料表上的資料行存放區索引可整合記憶體內部 OLTP 和記憶體內部資料行存放區技術,以傳遞 OLTP 和分析工作負載的高效能,藉以允許作業分析。 記憶體內部資料表上的資料行存放區索引必須包含所有資料行。
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
您現在已準備好執行即時作業分析,而不需對應用程式進行任何變更。 分析查詢將針對資料行存放區索引執行,而 OLTP 作業將針對 OLTP B 型樹狀結構索引繼續執行。 OLTP 工作負載將繼續執行,但會產生一些額外的負荷來維護資料行存放區索引。 請參閱下一節中的效能最佳化。
注意
文件通常會使用「B 型樹狀結構」一詞來指稱索引。 在資料列存放區索引中,資料庫引擎會實作 B+ 樹狀結構。 這不適用於資料行存放區索引或經記憶體最佳化的資料表。 如需詳細資訊,請參閱《SQL Server 和 Azure SQL 索引架構和設計指南》。
部落格文章
若要深入了解即時作業分析,請參閱下列部落格文章。 如果您先看過部落格文章,可能更容易了解效能秘訣章節。
使用記憶體最佳化資料表的即時作業分析 \(英文\)
影片
數據公開的影片系列會詳細說明一些功能和考慮。
效能提示 #1:使用經篩選索引來改善查詢效能
執行即時作業分析會影響 OLTP 工作負載的效能。 這種影響應該很小。 範例 A 示範如何使用篩選的索引,將非叢集數據行存放區索引對交易式工作負載的影響降到最低,同時仍即時傳遞分析。
若要將維護作業工作負載上非叢集資料行存放區索引的額外負荷降到最低,您可以使用篩選的條件,僅在「暖」或緩時變的資料上建立非叢集資料行存放區索引。 例如,在訂單管理應用程式中,您可以在已經出貨的訂單上建立非叢集資料行存放區索引。 一旦訂單已出貨之後,就很少變更,因此可視為暖資料。 透過篩選的索引,非叢集資料行存放區索引中的資料所需的更新很少,因而可降低對交易式工作負載的影響。
分析查詢可視需要明確地存取暖和熱資料,來提供即時分析。 如果作業工作負載的某個重要部分會接觸到「熱」資料,則這些作業就不需要對資料行存放區索引進行額外的維護。 最佳做法是,在篩選的索引定義中使用的資料行上具備資料列存放區叢集索引。 SQL Server 會使用叢集索引,快速掃描不符合篩選條件的資料列。 如果沒有這個叢集索引,就必須對資料列存放區資料表進行完整的資料表掃描,以尋找會對分析查詢效能造成顯著負面影響的資料列。 如果沒有叢集索引,您可以建立互補且篩選的非叢集 B 型樹狀結構索引來識別這類資料列,但不建議使用,因為透過非叢集的 B 型樹狀結構索引存取大範圍資料列的成本很高。
注意
只有以磁碟為基礎的資料表上才支援篩選的非叢集資料行存放區索引。 記憶體最佳化的資料表上並不支援。
範例 A︰從 B 型樹狀結構索引存取熱資料,從資料行存放區索引存取暖資料
此範例會使用篩選條件 (accountkey > 0) 來建立數據行存放區索引中的數據列。 目標是設計篩選的條件和後續查詢,以便從 B 型樹狀結構索引存取經常變更的「熱」資料,以及從資料行存放區索引存取更穩定的「暖」資料。

注意
查詢最佳化工具會考慮,但不一定會選擇對查詢計劃使用資料行存放區索引。 當查詢最佳化工具選擇篩選的資料行存放區索引時,其會明確地結合來自資料行存放區索引的資料列以及不符合篩選條件的資料列,以允許即時分析。 這不同於一般非叢集的篩選索引,這類索引只能用於將它們自己限制為出現在索引中之資料列的查詢。
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
分析查詢將使用下列查詢計劃來執行。 您可以查看透過叢集的 B 型樹狀結構索引,存取不符合篩選條件的資料列。

如需詳細資訊,請參閱 部落格:已篩選的非叢集數據行存放區索引。
效能提示 #2:將分析卸載至 Always On 可讀取次要
雖然可使用篩選的資料行存放區索引來將資料行存放區索引維護最小化,但分析查詢仍然需要大量運算資源 (CPU、I/O、記憶體),其會影響作業工作負載效能。 針對大部分任務關鍵性工作負載,建議您使用 AlwaysOn 組態。 在此組態中,您可以免除將分析卸載至可讀取次要以執行分析的影響。
效能提示 #3:讓熱資料保留在差異資料列群組中來減少索引片段
如果工作負載更新/刪除已壓縮的數據列,具有數據行存放區索引的數據表可能會明顯分散(也就是已刪除的數據列)。 片段的資料行存放區索引會導致記憶體/儲存體使用率的效率不佳。 除了資源使用效率不彰,也會因為額外的 I/O 以及從結果集中篩選出已刪除資料列的需要,而使分析查詢效能受到負面影響。
在使用 REORGANIZE 命令執行索引重組,或在整個資料表或受影響的分割區上重建資料行存放區索引之前,不會實際移除刪除的資料列。 索引 REORGANIZE 和 REBUILD 都是成本很高的作業,其會佔用本該用於工作負載的資源。 此外,如果數據列太早壓縮,可能會因為更新導致壓縮額外負荷浪費而需要重新壓縮多次。
您可使用 COMPRESSION_DELAY 選項將索引片段最小化。
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
如需詳細資訊,請參閱 部落格:壓縮延遲。
以下是建議的最佳做法:
插入/查詢工作負載: 如果工作負載主要是插入資料並加以查詢,則建議選項是預設為 0 的 COMPRESSION_DELAY。 將 1 百萬個資料列插入單一差異資料列群組之後,即會壓縮最新插入的資料列。
當您需要在 Web 應用程式中分析選取模式時,這類工作負載的一些範例為 (a) 傳統 DW 工作負載 (b) 選取數據流分析。OLTP 工作負載: 如果工作負載是 DML 繁重的(也就是更新、刪除和插入的繁重混合),您可以檢查 DMV
sys. dm_db_column_store_row_group_physical_stats來查看數據行存放區索引片段。 如果您看到最近壓縮的資料列群組中有 > 10% 的資料列標示為已刪除,您可以使用 COMPRESSION_DELAY 選項,在資料列變成能夠壓縮時,新增時間延遲。 例如,針對您的工作負載,如果最新插入的資料列假設在 60 分鐘內會保持「熱」(也就是進行多次更新),您應該選擇讓 COMPRESSION_DELAY 為 60。
我們預期大多數客戶不需要執行任何動作。 選項的 COMPRESSION_DELAY 預設值應該適用於它們。
針對進階使用者,建議您執行下列查詢,並收集過去七天內已刪除的數據列百分比。
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
如果壓縮數據列群組 > 中已刪除的數據列數目為 20%,則會在較舊的數據列群組 < 中使 5% 變化(稱為冷數據列群組)set COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time)。 這種方法最適合使用穩定且相對同質的工作負載。