負載平衡
運算中的負載平衡需求源自兩個基本需求:首先,高可用性可透過複寫來改善。 其次,效能可透過平行處理來改善。 高可用性是一項服務屬性,表示當任何用戶端嘗試存取服務時,服務幾乎 100% 的時間可供使用。 特定服務的服務品質 (QoS) 通常需要考量幾個因素,例如輸送量和延遲需求。
什麼是負載平衡?
最廣為人知的負載平衡形式是「迴圈配置資源 DNS」,許多大型 Web 服務會採用此形式,在多部伺服器之間負載平衡要求。 具體而言,多部前端網頁伺服器 (各有一個唯一的 IP 位址) 會共用一個 DNS 名稱。 為了平衡每部網頁伺服器上的要求數目,Google 等大型公司會維護並策展與單一 DNS 項目建立關聯的 IP 位址集區。 當用戶端提出要求 (例如對網域 www.google.com) 時,Google 的 DNS 就會從集區中選取一個可用的位址,並將其傳送給用戶端。 用來分派 IP 位址的最簡單策略就是使用簡單迴圈配置資源佇列,其會在每個 DNS 回應之後,排列位址清單。
在雲端問世之前,DNS 負載平衡是一種可解決長距離連線延遲的簡單方式。 DNS 伺服器上的發送器是以程式設計的方式,以地理位置上最接近用戶端的伺服器 IP 位址來回應。 若要這麼做,最簡單方法就是嘗試以集區中的 IP 位址來回應,此 IP 位址是數字上最接近用戶端 IP 位址的位址。 由於 IP 位址未散發於全球階層,因此,這個方法當然並不可靠。 當前的技術更加精密,並會依賴 IP 位址到位置的軟體對應 (以網際網路服務提供者 (ISP) 的實體地圖為依據)。 由於這會實作為昂貴的軟體查閱,因此這個方法會產生更精確的結果,但計算成本昂貴。 不過,因為只有當用戶端第一次連線到伺服器時才會執行 DNS 查閱,所以會分攤緩慢查詢的成本。 所有後續通訊都會在用戶端與擁有已分派 IP 位址的伺服器之間直接發生。 下圖顯示一個 DNS 負載平衡配置範例。
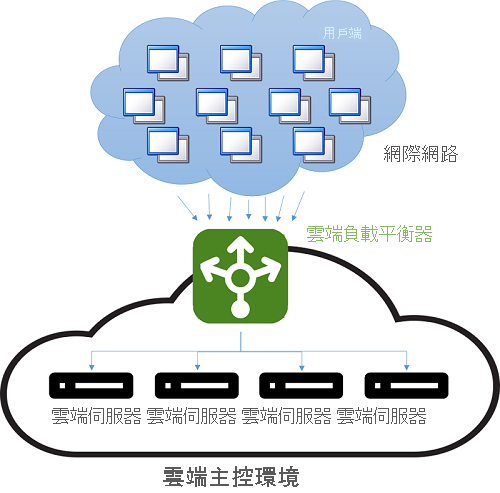
圖 4:雲端主控環境中的負載平衡
此方法的缺點是在伺服器失敗時,切換至不同 IP 位址取決於 DNS 快取的存留時間 (TTL) 設定。 DNS 項目已知為長期存留,且已知更新需要一週以上的時間才能透過網際網路傳播。 因此,很難快速地對用戶端「隱藏」伺服器失敗。 縮短快取中 IP 位址的有效期限 (TTL) 可改善這一點,但代價是效能降低及查閱次數增加。
新式負載平衡通常是指使用專用的執行個體 (或成對的執行個體),將連入流量導向至後端伺服器。 針對指定連接埠上的每個連入要求,負載平衡器會根據散發策略,將流量重新導向其中一部後端伺服器。 這樣做,負載平衡器就會維護要求中繼資料,包括應用程式協定標頭 (例如 HTTP 標頭) 之類的資訊。 在此情況下,由於每個要求都會通過負載平衡器,因此不會有過時資訊的問題。
儘管所有類型的網路負載平衡器都會直接將使用者資訊連同所有內容轉送到後端伺服器,但在將回應提供回用戶端時,可能會採用兩個基本策略的其中一個:1
- 通過 Proxy 處理:在此方法中,負載平衡器會接收來自後端的回應,並將其轉送回用戶端。 負載平衡器的作用和標準 Web Proxy 相同,且同時包含網路交易的兩個部分,也就是將要求轉送到用戶端和將回應傳送回來。
- TCP 遞交:在此方法中,會將與用戶端的 TCP 連線遞交給後端伺服器。 因此,伺服器會直接將回應傳送給用戶端,而不會經過負載平衡器。
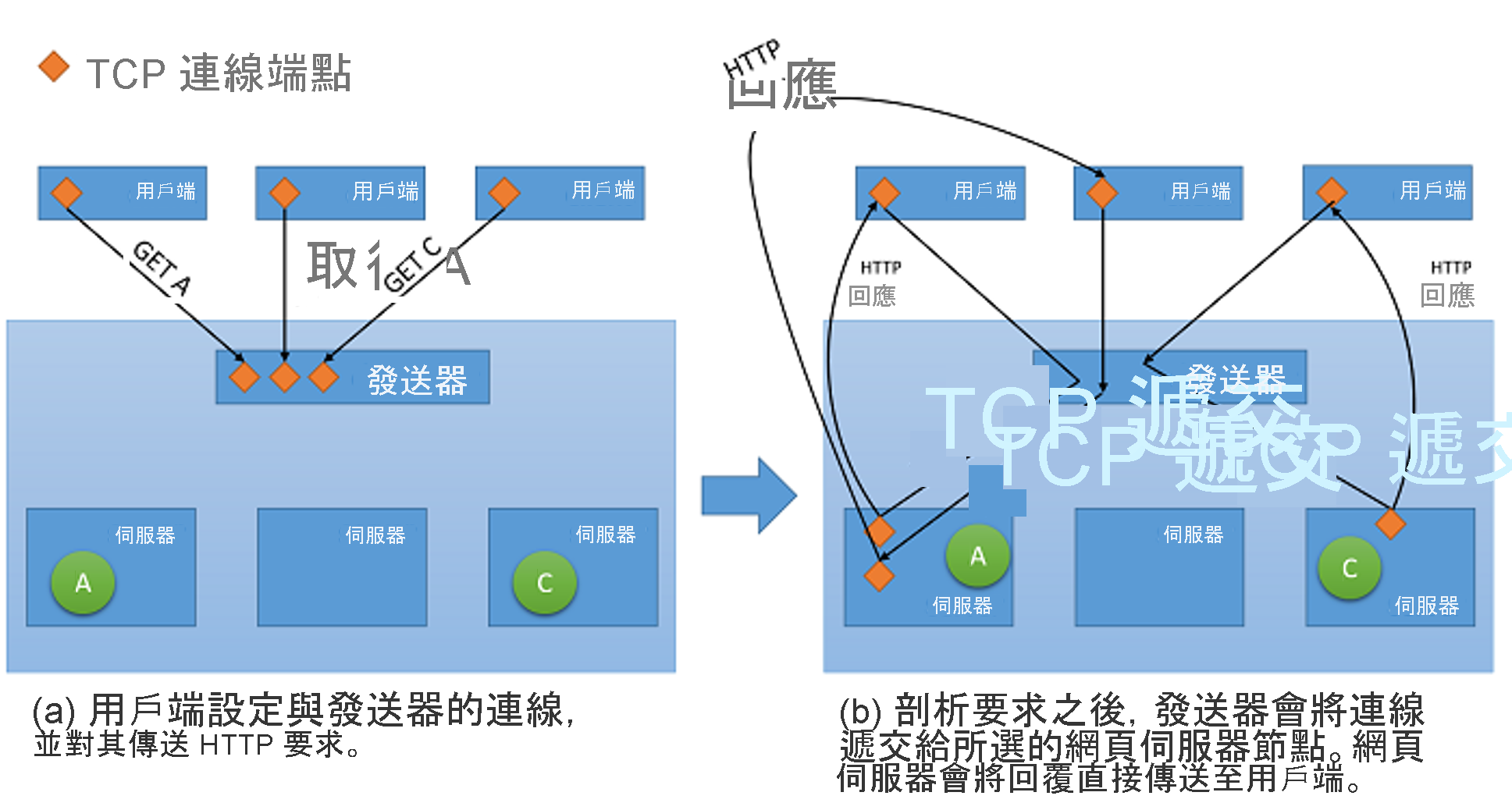
圖 5︰從發送器到後端伺服器的 TCP 遞交機制
對可用性和效能的影響
負載平衡是一項重要的策略,可為系統中的失敗設定遮罩。 只要將系統其用戶端公開給正在數個資源之間進行負載平衡的單一端點,就可透過直接服務不同資源的要求,以從用戶端遮罩個別資源的失敗。 不過,請務必注意,負載平衡器現在是服務的單一失敗點。 如果因為任何原因而失敗,即使所有後端伺服器仍正常運作,也不會服務任何用戶端要求。 因此,為了達到高可用性,負載平衡器通常會成對實作。
負載平衡可供服務將工作負載散發到雲端中的數個計算資源。 在雲端中擁有單一計算執行個體有數個限制。 我們稍早已討論過效能的實體限制,其中需要更多資源,才能增加工作負載。 藉由使用負載平衡,可將較大量工作負載散發到多個資源,讓每個資源都可獨立且平行地滿足其要求,藉此提高應用程式的輸送量。 這也會改善平均服務時間,因為有更多的伺服器可服務工作負載。
檢查和監視服務是實現成功負載平衡策略的關鍵。 負載平衡器必須確定每個資源節點都可供使用,以確保滿足每個要求。 如果不是,則不會將流量導向至該特定節點。 Ping Echo 監視是用來檢查特定資源節點健康狀態的最受歡迎策略之一。 除了節點的健康狀態以外,某些負載平衡策略還需要輸送量、延遲和 CPU 使用率等其他資訊,以評估最適合導向流量的資源。
負載平衡器通常必須保證高可用性。 若要這麼做,最簡單的方法就是建立多個負載平衡執行個體 (各有一個唯一的 IP 位址),並將每個執行個體連結到單一 DNS 位址。 每當負載平衡器執行個體因為任何原因而失敗時,就會以新的負載平衡器來取代,並以對效能影響很小的方式,將所有流量傳遞到容錯移轉執行個體。 同時,可設定新負載平衡器執行個體來取代失敗的執行個體,且應該立即更新 DNS 記錄。
負載平衡策略
雲端中有數種負載平衡策略。
公平分派
這是負載平衡的靜態方法,其中使用簡單迴圈配置資源演算法來平均劃分所有節點之間的流量,且不會考慮系統中任何個別資源節點的使用率,或任何要求的執行時間。 此方法會嘗試讓系統中的每個節點保持忙碌,且是最簡單的實作方法之一。 此方法有一個重要的缺點,那就是大量用戶端要求可能會彙總並叫用相同的資料中心,導致其中一些節點變得無法負荷,而其他節點的使用量仍然過低。 不過,這需要非常特定的負載模式,且在連線散發和容量相當一致的大量用戶端和伺服器上執行時可能很少發生。 然而,此策略會讓您難以在資料中心實作快取策略,將空間位置納入考量 (其中您會預先擷取和快取目前已擷取資料附近的資料),因為由相同用戶端所提出下一個要求最後可能會在不同的伺服器上。
AWS 會在其 ELB (Elastic Load Balancer) 供應項目中使用此方法。 AWS ELB 會佈建負載平衡器,以在連結的 EC2 執行個體之間平衡流量。 負載平衡器基本上就是 EC2 執行個體本身,並具備專門路由傳送流量的服務。 當負載平衡器後方的資源擴增時,新資源的 IP 位址就會在負載平衡器的 DNS 記錄上更新。 此程序要花費數分鐘才能完成,因為它需要監視和佈建時間。 這段調整期間 (一直到負載平衡器可處理較高負載的這段時間) 即所謂的「準備」負載平衡器。
AWS 中 ELB 負載平衡器也會監視所連結每項資源的工作負載散發,以維護健康狀態檢查。 Ping-Echo 機制可用來確保所有資源均為狀況良好。 ELB 使用者可以透過指定延遲和重試次數,來設定健康情況檢查的參數。
雜湊型分散
此方法會嘗試確保在任何時間點,用戶端透過相同連線所提出要求最後一定會在相同的伺服器上。 此外,為了平衡要求的流量散發,這會以隨機順序完成。 此方法比迴圈配置資源方法具有更多優點,因為其有助於工作階段感知應用程式,其中狀態持續性和快取策略可能會變得更簡單。 此方法也比較不容易因流量模式而導致單一伺服器上發生壅塞情形,因為散發是隨機的,但風險仍然存在。 不過,由於必須評估每個要求的連線中繼資料,才能將其路由傳送至相關的伺服器,因此會對每個要求產生少量的延遲。
Azure Load Balancer 使用這類雜湊型散發機制來散發負載。 此機制會根據來源 IP、來源連接埠、目的地 IP、目的地連接埠及通訊協定類型,為每個要求建立雜湊,以確保來自相同連線的每個封包最後一定會在相同伺服器上。 已選擇雜湊函式,因此與伺服器的連線散發會相當隨機。
Azure 透過三種探查類型提供健康情況檢查:客體代理程式探查 (在 PaaS VM 上)、HTTP 自訂探查和 TCP 自訂探查。 這三種探查都會透過 Ping Echo 機制來提供資源節點的健康狀態檢查。
其他熱門策略
還有其他策略可用來在多個資源之間平衡負載。 其中每個策略使用不同計量來測量特定要求的最適當資源節點:
- 根據要求執行時間的策略:這些策略使用優先順序排程演算法,其中會使用要求執行時間來判斷最適當的負載散發順序。 使用此方法的主要挑戰,在於能夠精確地預測特定要求的執行時間。
- 根據資源使用率的策略:這些策略使用每個資源節點上 CPU 使用率來平衡每個節點之間的使用率。 負載平衡器會根據其使用率來維護已排序的資源清單,然後將要求導向到負載最小的節點。
其他優點
具備集中式負載平衡器有助於數項可提升服務效能的策略。 不過,請務必注意,只有在負載平衡器未超過負荷的情況下,這些策略才有效。 否則,負載平衡器本身會成為瓶頸。 以下列出其中一些策略:
- SSL 卸載:透過 SSL 的網路交易由於必須處理加密和驗證,因此會有額外的相關成本。 您可透過 SSL 建立與負載平衡器的用戶端連線,同時透過 HTTP 將要求重新導向至每部個別伺服器,而不是透過 SSL 來服務所有要求。 這會大幅降低伺服器上的負載。 此外,只要重新導向要求不是透過開放式網路所提出,就能維護安全性。
- TCP 緩衝:此策略可用來卸載與負載平衡器連線速度緩慢的用戶端,以便減輕為這些用戶端提供回應的伺服器負擔。
- 快取:在某些情節中,負載平衡器可針對最熱門的要求 (或不需要傳送至伺服器就能處理的要求,例如靜態內容) 維護快取,以降低伺服器上的負載。
- 流量成形:針對某些應用程式,負載平衡器可用來將封包的流入延遲/重新排列優先順序,以便塑造出符合伺服器設定的流量。 這會影響某些要求的 QoS,但可確保滿足傳入的負載。
參考資料
- Aron, Mohit and Sanders, Darren and Druschel, Peter and Zwaenepoel, Willy (2000). Scalable content-aware request distribution in cluster-based network servers (叢集型網路伺服器中的可調整內容感知要求散發) 2000 年度 USENIX 技術會議發表文章