如何處理尾延遲
我們已討論過數個在雲端上用以降低延遲的最佳化技巧。 我們研究過的一些量值,包括以水平或垂直方式調整資源,以及使用負載平衡器將要求路由至最接近的可用資源。 本頁會更深入探討,為何在大型資料中心或雲端應用程式中,一定要將所有要求的延遲降至最低,而不只是最佳化一般案例。 我們會研究幾個高延遲極端值如何大幅降低所觀察到的大型系統效能。 本頁也涵蓋各種技術,以建立會提供可預測低延遲回應的服務,即使個別元件無法保證這一點。 此問題對於希望互動延遲低於 100 毫秒的互動式應用程式特別重要。
什麼是尾延遲?
大部分的雲端應用程式都是大型分散式系統,通常依賴平行處理以減少延遲。 常見的技巧是將根節點 (例如前端網頁伺服器) 所收到要求傳送至多個分葉節點 (後端計算伺服器)。 效能改善因分散式運算的平行處理原則而見成效,當然為避免極度昂貴的資料移動成本也是推手之一。 我們只是將計算移到儲存資料的位置。 當然,每個分葉節點都會同時在數百個或甚至數千個平行要求中運作。
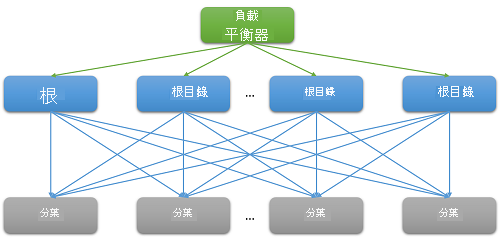
圖 7︰因向外延展而造成的延遲
請考慮在 Netflix 搜尋電影的範例。 當使用者開始在搜尋方塊中鍵入文字時,就會從根網頁伺服器產生數個平行事件。 這些事件至少包括下列要求:
- 就自動完成引擎要言,要根據過去趨勢和使用者的設定檔,真正預測即將要執行的搜尋。
- 就更正引擎而言,要根據持續調整的語言模型,在鍵入的查詢中尋找錯誤。
- 至於多字查詢其每個元件單字的個別搜尋結果,則必須根據電影的排名和相關性予以合併。
- 另外還要對結果加以後置處理和篩選,以符合使用者的「安全搜尋」喜好設定。
這類範例極為常見。 已知單一的 Facebook 要求需要連絡數千部 memcached 伺服器,而單一 Bing 搜尋通常要連絡一萬部以上的索引伺服器。
很明顯地,調整需求導致前端所服務的每個個別要求在後端大型傳送。 對於預期要「有所回應」以保留其使用者基礎的服務,啟發學習法顯示預期的回應時間為 100 毫秒內。 隨著解決查詢所需的伺服器數目增加,整體時間通常取決於分葉節點到根節點的最差執行回應。 假設所有的分葉節點都必須在結果傳回之前執行完畢,則整體延遲必須一律大於單一最慢元件的延遲。
就像大部分的推測程序一樣,單一分葉節點的回應時間可以分佈表示。 數十年的經驗顯示,在一般情況下,設定完善的雲端系統其大部分要求 (>99%) 都執行得非常快速。 但系統總是會有極少的極端值,其執行速度異常慢。
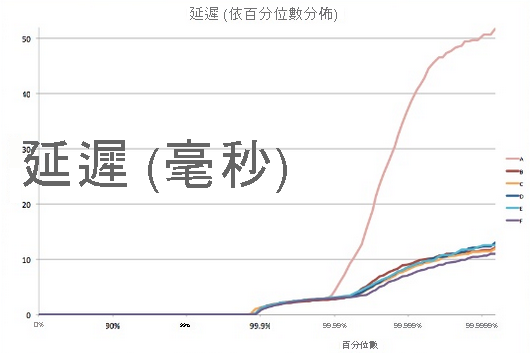
圖 8︰尾延遲範例5
假設有一個系統,其所有分葉節點的平均回應時間為 1 毫秒,但有 1% 的機率,回應時間會大於 1,000 毫秒 (一秒)。 如果每個查詢只由單一分葉節點處理,則查詢時間超過一秒的機率也是 1%。 不過,當節點數增加到 100 時,查詢在一秒內完成的機率會降至 36.6%,這表示有 63.4% 的機率,查詢持續時間會由延遲分佈的尾部 (最低 1%) 決定。
$(.99^{100})$
如果我們針對各種案例模擬這種情況,就會發現,隨著伺服器數目的增加,單一緩慢查詢的影響也更明顯 (請注意,下圖為單純增加)。 此外,當這些極端值的機率從 1% 降低到 0.01% 時,系統速度會大幅變慢。
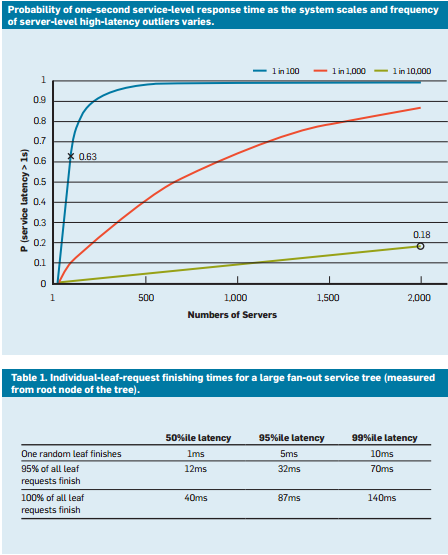
圖 9︰最新回應時間機率研究中顯示要求延遲的第 50 個、第 95 個和第 99 個百分位數4
就像我們將應用程式設計成容錯以處理資源可靠性的問題一樣,應用程式為什麼一定要能「容忍尾延遲」,現在應該也很清楚了。為處理此情況,我們必須了解這些長效能變化的來源,並在沒有因應措施的情況下盡可能降低風險。
雲端中的變化:來源與降低風險
為解決導致此尾延遲問題的回應時間變化,我們必須了解效能變化的來源。1
- 使用共用的資源:許多不同 VM (及這些 VM 中的應用程式) 都會爭用計算資源的共用集區。 在極其罕見的情況下,此爭用可能會導致某些要求的低延遲。 對於重要的工作而言,使用專用執行個體並在閒置時定期執行基準測試以確保其運作正常是合理的。
- 背景精靈和維護:我們已討論過背景程序需要建立檢查點、建立備份、更新記錄、回收記憶體以及處理資源清除。 但這些工作在執行時都會降低系統效能。 為減輕此問題,請務必同步處理因維護執行緒而造成的中斷,將對流量的影響降至最低。 這會導致簡短的熱門時段出現所有變化,而不是隨機出現在應用程式的存留期中。
- 佇列:另一個常見變化來源是流量抵達模式的突發性。1 如果 OS 不使用 FIFO 排程演算法,此變化會惡化。 Linux 系統通常不按順序排程執行緒,以最佳化整體輸送量,並充分利用伺服器。 研究發現,在 OS 中使用 FIFO 排程可減少尾延遲,但卻會降低系統的整體輸送量。
- 全部對全部 incast:上圖 8 所示的模式稱為全部對全部通訊。 因為大部分網路通訊都是透過 TCP,所以導致了前端網頁伺服器和所有後端處理節點之間同時有數千個要求和回應。 這是極端的叢發性通訊模式,通常會導致一種特殊的擁塞失敗,亦即 TCP incast 摺疊。1、2 上千部伺服器密集的突然回應會造成許多封包被丟棄及重新傳輸,最後導致網路流量因非常小的資料封包而崩潰。 大型資料中心和雲端應用程式通常需要使用自訂的網路驅動程式來動態調整 TCP 接收時段和重新傳輸計時器。 路由器也可設定為捨棄超過特定速率的流量並減少傳送的大小。
- 電源和溫度管理:最後,變化是其他成本降低技術的副產品,例如使用閒置狀態或 CPU 頻率相應減少。 處理器可能經常會耗用從閒置狀態相應增加的非一般時間量。 關閉這類成本最佳化會導致更高的能源使用量和成本,但變化則較低。 這在公用雲端沒什麼問題,因為定價模式很少會考慮客戶資源的內部使用量計量。
某些實驗發現,這類系統的變化在公用雲端上較差,3 一般是因為虛擬資源和共用處理器的效能隔離有缺陷。 如果有許多延遲敏感的作業和 CPU 密集作業在同一個實體節點上執行,情況就會惡化。
接受變化:工程解決方案
上述許多變化來源都沒有萬無一失的解決方案。 因此,雲端應用程式必須設計為能夠容忍尾延遲,而不是嘗試解決所有擴大尾延遲的來源。 當然,這就像為何設計應用程式能夠容錯,就是因為我們不可能修正所有可能的錯誤。 處理此變化的一些常見技巧包括:
- 「夠好」的結果:通常,當系統等候接收來自數千個節點的結果時,任何單一結果的重要性都視為非常低。 因此,許多應用程式可能只會選擇在特定短延遲時間內抵達的結果來回應使用者,並捨棄其餘的結果。
- 金絲雀:另一個常用於罕見程式碼路徑的替代方法,是在小部分的分葉節點上測試要求,以測試其是否會導致影響整個系統的損毀或故障。 只有當金絲雀不會造成故障時,才會產生完整的傳送查詢。 這就像將一隻金絲雀 (鳥) 送入煤礦,測試人類在此是否安全。
- 延遲引發的試用和健康狀態檢查:當然,系統有大量要求實在太普遍,所以不必使用金絲雀來進行測試。 如果分葉節點之一的效能不佳,這類要求更可能會有長尾。 為此,系統必須定期監視每個分葉節點的健康狀態和延遲,且不要將要求路由至 (因為維護或故障而) 效能表現低下的節點。
- QoS 差異:您可針對互動式要求建立不同的服務類別,允許其在任何佇列中都優先。 不區分延遲的應用程式可以容許作業有較長等候時間。
- 要求避險:這是簡單的解決方案,將相同的要求轉送到多個複本,並使用第一個抵達的回應,藉以減少變化的影響。 當然,這會讓所需的資源量成倍或三倍增加。 為減少避險要求的數目,只有在第一個回應擱置大於該要求預期延遲的第 95 個百分位數時,才會傳送第二個要求。 這只會造成大約 5% 的額外負載,卻能大幅降低尾延遲 (如圖 9 所示的一般情況,第 95 個百分位數其延遲遠低於第 99 個百分位數的延遲)。
- 推測執行和選擇性複寫:位在特別忙碌節點上的工作,可於其他使用量過低的分葉節點上以推測式方式啟動。 當特定節點的故障導致其超載時,這特別有效。
- UX 式解決方案:最後,您可透過設計良好的使用者介面,以智慧方式向使用者隱藏延遲,此介面可降低人類使用者的延遲感。 達到此目的的技術包括使用動畫、顯示早期結果,或傳送相關訊息佔用使用者的時間。
使用這些技術,有可能大幅改善雲端應用程式的終端使用者體驗,以解決長尾的特有問題。
參考資料
- Li, J., Sharma, N. K., Ports, D. R., & Gribble, S. D.(2014 年)。 Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency (尾的故事:尾延遲的硬體、OS 和應用層級來源) from the Proceedings of the ACM Symposium on Cloud Computing, ACM
- Wu, Haitao and Feng, Zhenqian and Guo, Chuanxiong and Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks (ICTCP:資料中心網路中的 TCP Incast 壅塞控制), IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing and Musgrave, Zachary and Noble, Brian and Bailey, Michael (2013). Bobtail: Avoiding Long Tails in the Cloud (短尾:雲端要避免長尾), 10th USENIX Conference on Networked Systems Design and Implementation, USENIX Association
- Dean, Jeffrey and Barroso, Luiz André (2013). The tail at scale (規模的尾部), Communications of the ACM, ACM
- Tene, Gil (2014). [Understanding Latency - Some Key Lessons and Tools (了解延遲 - 一些主要課題與工具)](https://www.infoq.com/presentations/latency-lessons-tools/, QCon London