在雲端上進行自動調整
雲端管理員可以手動執行擴大或擴增,以處理日益增加的需求;並在需求減少時執行縮減或縮小,以降低成本。 例如,監看的管理員可以偵測到需求正在增加,並使用雲端服務提供者所提供的工具來讓其他 VM 上線 (相應放大),或以較大型 VM (具有更多 CPU 和更多記憶體的 VM) 來取代現有的 VM (相應增加)。 關鍵在於「細心」。如果需求達到尖峰卻沒有人察覺,那麼對終端使用者來說,整個系統都可能會變慢,甚至是無回應。 反之,如果您擴大或擴增來處理更沉重的負載,而無法在負載減少時調整回來,則您最終要為不必要的資源支付費用。
這就是熱門雲端平台提供「自動調整」機制的原因,這樣一來就可以因應變動需求來調整資源,而不需人為介入。 自動調整有兩種主要方法:
以時間為基礎:根據預先決定的排程調整資源。 例如,如果貴組織的網站在工作時間內所遇到的負載最高,則設定自動調整,讓資源能夠在每天上午 8:00 時擴大,並於下午 5:00 時縮小。 以時間為基礎的調整有時會稱為「排程調整」。
以計量為基礎:如果負載的可預測性較低,則根據預先定義的計量 (例如,CPU 使用率、記憶體壓力或平均要求等候時間) 來調整資源。 例如,如果平均 CPU 使用率達到 70%,即會自動讓額外的 VM 上線,當使用率回到 30% 時,就會取消佈建額外的 VM。
無論您選擇根據時間/計量或兩者並用進行調整,自動調整都需要依賴由雲端管理員設定的調整規則或調整原則。 新型雲端平台支援的調整規則範圍很廣,從簡單 (例如:每天上午 8:00 從兩個執行個體擴充為四個,並於下午 5:00 還原為兩個執行個體) 到複雜 (例如:若 CPU 使用率上限超過 70%,或者平均要求等候時間達到 5 秒,則會將 VM 計數加一),無所不包。 要找到合適的規則組合,通常都需要雲端管理員進行一些實驗。
所有主要雲端服務提供者 (包括 Amazon、Microsoft 和 Google) 都支援自動調整。 AWS 自動調整可以套用至 EC2 執行個體、DynamoDB 資料表,以及選取的其他 AWS 雲端服務。 Azure 會針對 App Service 和虛擬機器在內的主要服務提供自動調整選項。 Google 則會針對 Google Compute Engine 和 Google App Engine 提供相同選項。
一般來說,自動調整服務會縮減和擴增,而不是擴大和縮小,部分原因是擴大和縮小需要用一個執行個體來取代另一個,而在建立新執行個體並使其上線時,難免會造成一段時間的停機狀態。
以時間為基礎的自動調整
如果負載的變動是可以預測,便適合使用以時間為基礎的自動調整。 例如,許多組織的 IT 系統都會在工作時間內遇到最高的負載,而在凌晨時分則可能幾乎沒有任何負載。 達美樂比薩的網站可能一整天都有負載,因為它在將近 100 個國家/地區開設了超過 16,000 家分店。 但可預測的是,它會在全年的特定時間遇到比平常還要高的負載。
以上兩種情境都適合使用以時間為基礎的自動調整。 圖 7 顯示如何在 Azure 中制定排程的自動調整。 在此範例中,雲端管理員會設定 Azure App Service 為組織網站提供主機服務,預設執行兩個執行個體,但會在上午 6:00 和下午 6:00 之間擴大為四個執行個體,一週六天,星期日除外。 只要選取 [指定開始/結束日期] 選項,該管理員就可以輕鬆地將 App Service 設定為在超級盃的星期日擴增為 10 個執行個體。 而且她也可以定義多個調整條件,以便在其他日期相應放大。
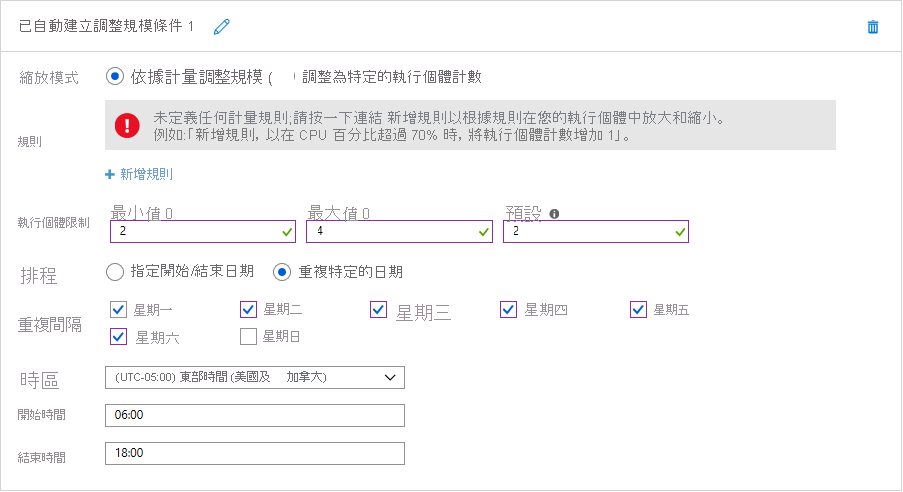
圖 7︰Azure 中的排程自動調整。
以計量為基礎的自動調整
如果負載較難預測,則適合使用根據計量 (例如:CPU 使用率和平均要求等候時間) 進行調整。 監視能夠讓自動調整程式知道何時要調整,因此是根據效能計量有效自動調整資源的關鍵元素。 監視能夠分析流量模式或資源使用率,從而憑經驗評估調整資源的時機和規模,以達到提供最佳服務品質同時將成本降到最低的目的。
有數個層面的資源會受到監視,以便觸發資源調整。 最常見的計量是資源使用率。 例如,監視服務可以追蹤每個資源節點的 CPU 使用率,並在使用量過高或太低時調整資源。 舉例來說,如果每個資源的使用量超過 90%,由於系統負載過重,新增更多資源可能會是個好主意。 服務提供者通常會藉由分析資源節點的中斷點、開始失敗的時間點,以及制定他們在不同負載層級中的行為,來決定這些觸發點。 儘管出於成本因素,務必要充分利用每個資源,但還是建議您保留一些空間讓作業系統能夠執行管銷活動。 同樣,如果使用率低於 30%,則可能不是所有資源節點都是必要的,有些可以取消佈建。
實際上,服務提供者通常會監視數個不同資源節點計量的組合,以評估調整資源的時機。 這其中包括 CPU 使用率、記憶體耗用量、輸送量和延遲。 AWS 會使用 CloudWatch 來監視 EC2 資源,並提供調整計量 (圖 8)。 CloudWatch 會追蹤調整群組中所有 EC2 執行個體的計量,並在指定的計量超出閾值時引發警示,例如當 CPU 使用率超過 70% 時。 然後,AWS 會根據管理員所設定的調整原則來增加或減少 EC2 執行個體計數。
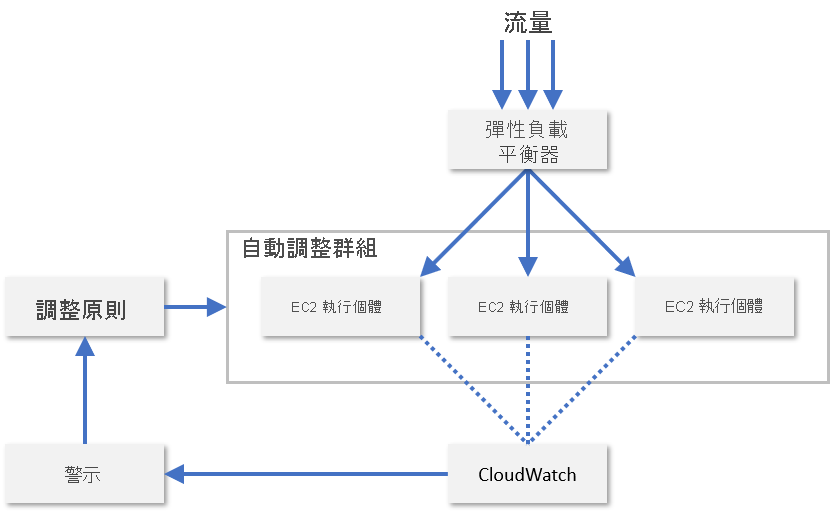
圖 8:自動調整 AWS 中的 EC2 執行個體。
AWS 也支援預測性調整,這項功能使用機器學習來預測流量模式,並據此管理執行個體計數。 目標是在不需要雲端管理員設定自動調整規則的情況下,以智慧方式調整雲端資源。 主要雲端服務提供者會持續尋找使用機器學習來改善其平台的新方式。 例如,Microsoft 現在使用機器學習,透過主動預測和減緩 VM 失敗來改善 Azure 虛擬機器的復原能力1。
參考資料
- Microsoft (2018)。 使用預測性 ML 和即時移轉來改善 Azure 虛擬機器復原能力。 https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.