描述智慧型查詢處理
在 SQL Server 2017 和 2019,以及 Azure SQL 中,Microsoft 已在相容性層級 140 和 150 中引進了許多新功能。 其中許多功能更正了先前所謂的反模式,例如利用使用者定義的純量值函式和使用資料表變數。
這些功能分成數個系列的功能:
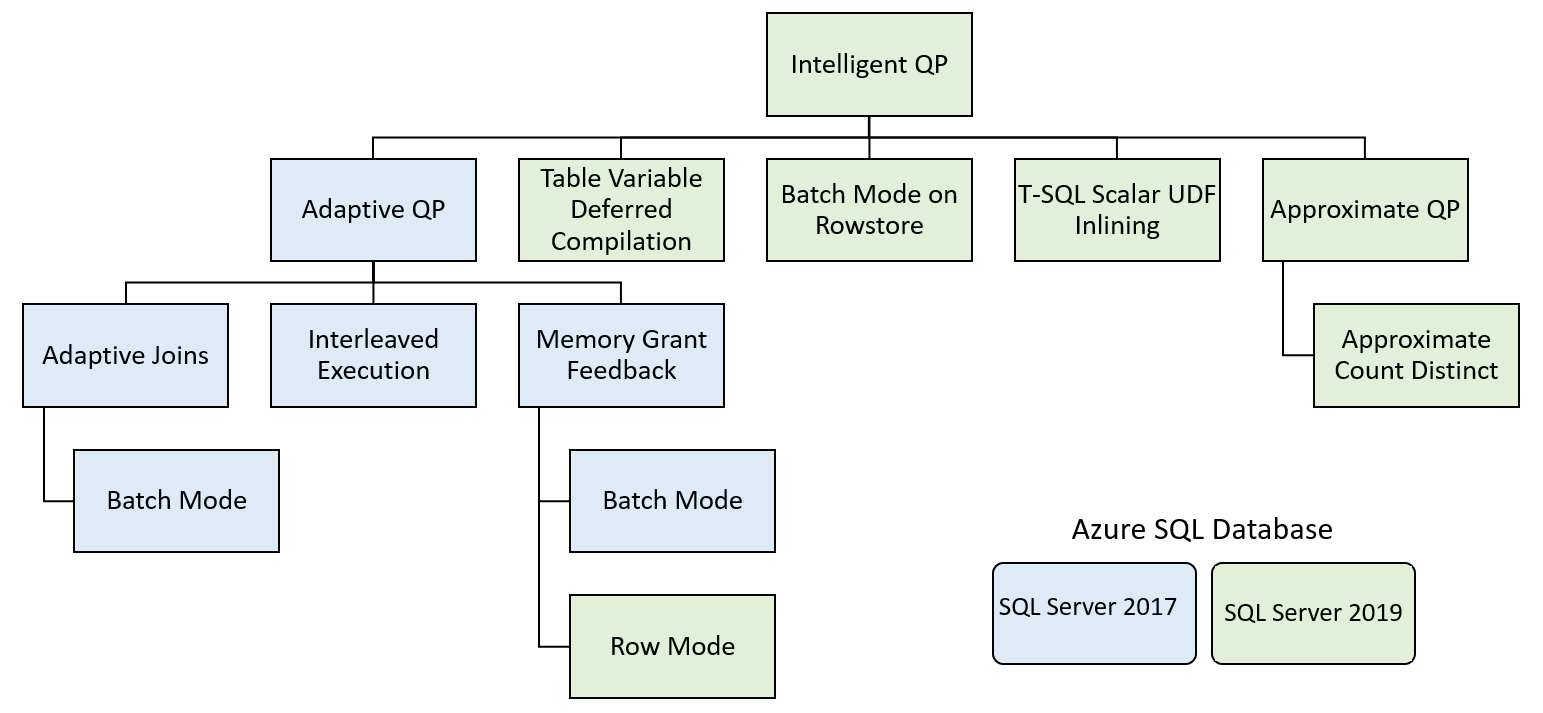
智慧型查詢處理包含可透過最少實作工作改善現有工作負載效能的功能。
若要讓工作負載自動符合智慧型查詢處理資格,請將適用的資料庫相容性層級變更為 150。 例如:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
自適性查詢處理
自適性查詢處理包含許多選項,其可根據查詢的執行內容,讓查詢處理更加動態。 這些選項包含數個增強查詢處理的功能。
自適性聯結 - 資料庫引擎會根據進入聯結的資料列數目,延遲在雜湊與巢狀迴圈之間的聯結選擇。 自適性聯結目前僅在批次執行模式下運作。
交錯執行 - 目前這項功能支援多重陳述式資料表值函式 (MSTVF)。 在 SQL Server 2017 之前,MSTVF 已使用 1 或 100 列的固定資料列估計值,視 SQL Server 版本而定。 如果函式傳回了更多資料列,則此估計值可能會導致次佳的查詢計劃。 透過交錯執行,會在編譯計畫的其餘部分之前,從 MSTVF 產生實際的資料列計數。
記憶體授與意見反應 - SQL Server 會根據來自統計資料的資料列計數估計,在查詢的初始計畫中產生記憶體授與。 嚴重的資料扭曲可能會導致高於或低於資料列計數估計值,因而導致降低並行的過度記憶體授與,或可能導致查詢將資料溢出到 tempdb 的不足記憶體授與。 使用記憶體授與意見反應,SQL Server 會偵測這些狀況,並減少或增加授與查詢的記憶體數量,以避免溢出或過度配置。
這些功能都會在相容性模式 150 下自動啟用,而且不需要其他變更即可啟用。
資料表變數延後編譯
就像 MSTVF 一樣,SQL Server 執行計畫中的資料表變數帶有一個資料列的固定資料列計數估計。 就像 MSTVF 一樣,此固定估計值會在變數具有的資料列計數比預期更大時導致效能不佳。 使用 SQL Server 2019,現在會分析資料表變數,而且這些變數具有實際的資料列計數。 延後編譯的本質類似於 MSTVF 的交錯執行,差別在於其是在第一次編譯查詢時執行,而不是在執行計畫內以動態方式執行。
資料列存放區上的批次模式
批次執行模式可讓您以批次方式處理資料,而不是逐列處理資料。 由於計算和彙總而產生大量 CPU 成本的查詢,將會看到來自此處理模型的最大優勢。 藉由分隔批次處理和資料行存放區索引,可讓更多的工作負載受益於批次模式處理。
純量使用者定義函式內嵌
在較舊版本的 SQL Server 中,有數個原因導致純量函式的執行效能很差。 純量函數反覆地執行,一次有效地處理一個資料列。 它們在執行計畫中沒有適當的成本估計,而且不允許在查詢計劃中使用平行處理原則。 搭配使用者定義函式內嵌,這些函式會轉換成純量子查詢,以取代執行計畫中的使用者定義函數運算子。 對於涉及純量函式呼叫的查詢,此轉換可能會大幅提升效能。
近似相異計數
常見的資料倉儲查詢模式是執行訂單或使用者的相異計數。 此查詢模式對於大型資料表而言可能所費不貲。 近似相異計數引進更快的方法,藉由將資料列分組來收集相異計數。 此函式保證信賴區間為 97% 的 2% 錯誤率。