什麼是機器學習服務?
機器學習在統計資料和資料數學模型化方面具有其來源。 機器學習的基本概念是使用過去觀察的資料來預測未知的結果或值。 例如:
- 冰淇淋店的擁有者可能會使用結合歷史銷售額和天氣記錄的應用程式,根據天氣預測,在給訂日期,預測可能會銷售多少個冰淇淋。
- 醫生可能會使用過去病患的臨床資料來執行自動化測試,根據體重、血糖等級和其他度量等因素,預測新病患是否具有罹患糖尿病風險。
- 南極的研究人員可能會利用過去的觀察來自動識別不同的企鵝物種 (如 阿德利企鵝、巴布亞企鵝 或 頰帶企鵝),這是基於對鳥類的鰭、喙和其他物理特徵的測量。
機器學習即 函式
因為機器學習是以數學和統計資料為基礎,所以通常會以數學術語來思考機器學習模型。 基本上,機器學習模型是一種軟體應用程式,可封裝 函式,以根據一或多個輸入值來計算輸出值。 定義該函式的流程稱為 定型。 定義函式之後,您可以使用它來預測稱為 推斷 的流程中的新值。
讓我們來探索定型和推斷相關的步驟。
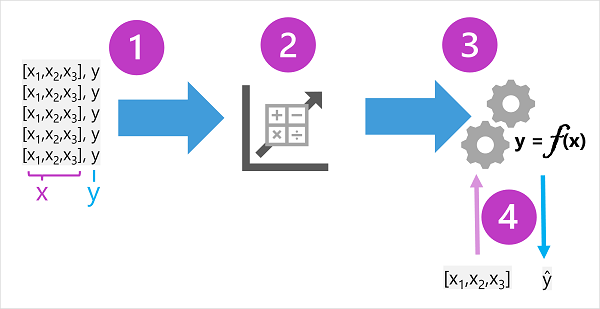
定型資料是由過去的觀察所組成。 在大部分情況下,觀察包括所觀察專案的觀察屬性或 特徵,以及您想要定型模型來預測 (稱為 標籤) 的已知值。
在數學方面,您通常會看到使用簡短變數名稱 x 代指特徵,而標籤則稱為 y。 通常,觀察是由多個特徵值所組成,因此 x 實際上是 向量 (具有多個值的陣列),如下所示: [x1、x2、x3、...]。
為了更清楚說明,讓我們考慮先前所述的範例:
- 在冰淇淋銷售案例中,我們的目標是定型模型,以根據天氣預測冰淇淋銷售數目。 當日 (溫度、氣象、風流等) 的天氣測量是 特徵 (x),而每天銷售的冰淇淋數目會是標籤 (y)。
- 在醫療案例中,目標是根據病患的臨床測量,預測患者是否具有罹患糖尿病風險。 病患的度量 (體重、血糖等級等等) 是 特徵(x),而罹患糖尿病的可能性 (例如 1 表示有風險,0 表示沒有風險) 是 標籤(y)。
- 在南極研究案例中,我們想要根據企鵝的物理屬性來預測其物種。 企鵝的關鍵度量 (鰭的長度,喙的寬度等等) 是特徵(x),而物種 (例如,0 代表阿德利企鵝,1 代表巴布亞企鵝,2代表頰帶企鵝) 是標籤(y)。
演算法 會套用至資料,以嘗試判斷特徵與標籤之間的關聯性,並將該關聯性一般化為可在 x 上執行的計算,來計算 y。 使用的特定演算法會依您嘗試解決的預測性問題類型而定 (這部分稍後會詳述),但基本準則是設法使函式和資料適配,其中功能值可用於計算標籤。
演算法的結果是一種 模型,可將演算法衍生的計算封裝為 函式,讓我們將之稱為 f。 在數學標記法中:
y = f(x)
既然 定型 階段已完成,定型的模型就可以用於 推斷。 此模型基本上是軟體程式,可封裝定型程式所產生的函式。 您可以輸入一組特徵值,並接收作為對應標籤預測的輸出。 由於模型的輸出是由函式所計算的預測,而不是觀察到的值,所以您通常會看到函式的輸出顯示為 ŷ (其被愉快地表述為「y-hat」)。